Chapter 8.1: ML Training Pipelines
Build repeatable, governed production training pipelines from notebook wins
ML Training Pipelines (From Notebook Wins → Repeatable, Governed Production Training)
The core mental model
A training pipeline is a factory that turns versioned inputs (code + config + data + features) into a trusted model artifact (model + metrics + lineage) through gated, automated steps.
If training is not reproducible, it’s not a pipeline—it’s a one-off event.
1) Separate the two “deployables”
This prevents a ton of confusion and outages:
A) Deployable #1: Training pipeline definition
- DAG/workflow code, component containers, configs, infra settings
- Released via CI/CD like normal software.
B) Deployable #2: Model artifact
- Produced by pipeline runs; promoted via registry/gates
- Released via approval + progressive validation.
Heuristic: pipeline changes follow software release discipline; model promotions follow experiment discipline.
2) From notebooks → production training code (minimum refactor bar)
What to do
-
Break notebook into stateless modules:
load_data(),validate_data(),transform(),train(),evaluate(),package()
-
Make the entrypoint a script with CLI args (
argparse) for:- data version/path
- config path
- output path
- run ID / experiment tracking ID
What “stateless” really means
Each step:
- gets all inputs explicitly (args, config, artifacts)
- writes outputs explicitly (S3 path / artifact store)
- avoids implicit global state (“the notebook had it in memory”)
Rule: if the script can’t be executed from a clean container with only a config and data pointer, it’s not production-ready.
3) Configuration management (reproducibility and environment control)
No hardcoding of:
- paths
- hyperparameters
- instance types
- feature lists
- evaluation thresholds
Defaults
- configs in YAML/JSON committed to Git
- environment selects config (
APP_ENV=staging→config/staging.yaml) - allow overrides for runs (CLI flags / env vars)
Heuristic: the config file is part of the “model recipe.” Treat config as a versioned artifact.
4) Canonical pipeline stages (the “must-have stations”)
These steps show up across most mature training systems:
- Data ingestion / extraction (load the versioned dataset)
- Data validation (schema + quality checks; fail fast)
- Preprocess / feature engineering (repeatable transforms)
- Training (with explicit compute + hyperparams)
- Offline evaluation (metrics + slices)
- Business validation (thresholds vs baseline/champion)
- Register model + metadata + lineage

Rule: data validation must happen before expensive training. If DQ fails, training should not run.
5) Component design: containers + explicit contracts
Each step should have:
- its own container (or a small number of shared containers)
- clearly defined inputs/outputs (paths + schemas)
- parameterization (data range, model type, HPs, output tags)
Heuristic: define contracts as if teams will swap components later (because they will).
6) CI/CD for training pipelines (pipeline code is software)
This chapter stresses an important nuance: CI/CD is for the pipeline definition, not “continuous training” (CT).
CI (on PR)
- unit tests for transforms/train/eval logic
- integration tests between adjacent components
- DAG validation (e.g., “does the workflow compile?”)
- build container images if component code changed (tag with commit hash)
CD (on merge)
- deploy pipeline definition to staging orchestration
- run a staging E2E on a small representative dataset
- promote the same pipeline definition + images to prod
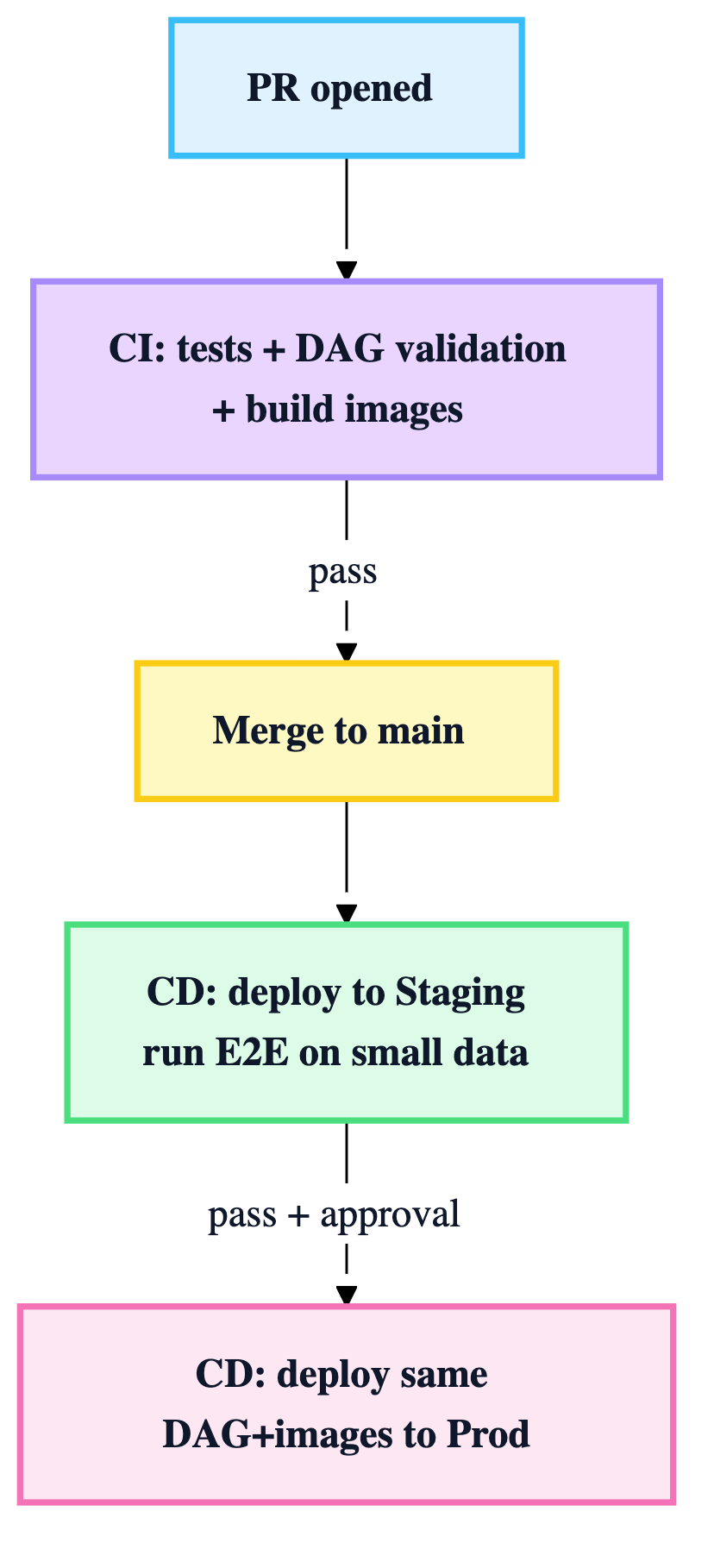
Rule: don’t rebuild images between staging and prod. Promote the exact artifact set you validated.
7) Training orchestration: schedule + events + manual
Common triggering modes:
- Time-based: daily/weekly retrains
- Event-based: new data arrival, upstream pipeline completion
- Monitoring-based: performance degradation/drift triggers retrain
- Manual: urgent reruns or investigations
Heuristic: start with time-based or upstream-completion triggers. Add drift-based triggers only after monitoring is stable.
8) Distributed training strategy (choose the simplest that fits)
Start here:
- Data parallelism (DDP / MirroredStrategy / Horovod) for “model fits on one GPU” Escalate only when forced:
- FSDP/ZeRO when memory is the limit
- tensor/pipeline parallel for very large transformer-style models
Rule: distributed training is an ops burden—earn it with a real need (time-to-train, memory constraints).
9) Infra & cost controls (production training is a FinOps problem)
Instance selection
- CPU for classic ML / smaller jobs
- GPU for DL
- accelerators (TPU/Trainium) when cost/perf justifies
Spot strategy (high ROI)
- use spot for fault-tolerant training
- require checkpointing + resume logic
- auto-terminate clusters/jobs when done
Heuristic: if you can’t resume from checkpoints, you can’t safely use spot—and you’ll overspend.
10) Metadata logging (auditability is a feature)
Every training run must log enough to answer: “What produced this model?” and “Can we reproduce it?”
Minimum metadata:
- pipeline run ID + trigger type
- code commit + DAG version
- container image digests
- data/feature versions
- full config + hyperparams
- metrics + slice metrics
- artifact paths (processed data, model, reports)
- resource utilization (nice-to-have but valuable)
Rule: treat metadata as part of the deliverable, not an afterthought.
11) “Definition of Done” for a training pipeline
A pipeline is production-grade only when:
- ✅ notebook refactored into modular, stateless scripts
- ✅ config-driven (no hardcoded paths/HPs/instance types)
- ✅ data validation gates exist (schema + DQ)
- ✅ evaluation + business validation gates exist (thresholds vs baseline/champion)
- ✅ artifacts are packaged with signatures + dependencies
- ✅ model registry integration exists (versioning + lineage)
- ✅ CI validates components + DAG; images are versioned
- ✅ CD deploys pipeline to staging then prod (no rebuild between)
- ✅ checkpointing + retries + cleanup (auto-terminate) are in place
- ✅ logs/metadata are complete enough for audits and debugging