Audience: CTOs • Senior Tech Leads • AI/ML Engineers • Product Managers
Purpose: turn “LLM demos” into reliable, adoptable, defensible, profitable agentic products.
The thesis (what wins in Agentic AI)
1) Build workflow wedges, not generic chatbots
A strong wedge is a narrow, high-frequency workflow step where you can deliver “wow” in < 30 seconds, cheaply, and defensibly.
2) Design distribution as a 3-layer system
- Layer 1 – GTM Wedge: how you enter a workflow
- Layer 2 – PLG Loop: how usage recruits the next user
- Layer 3 – Moat Flywheel: how usage compounds defensibility (data / workflow / trust)
3) Treat trust + governance as a growth engine
For agents, reliability, auditability, and oversight are not “enterprise add‑ons” — they unlock scale.
Playbook map
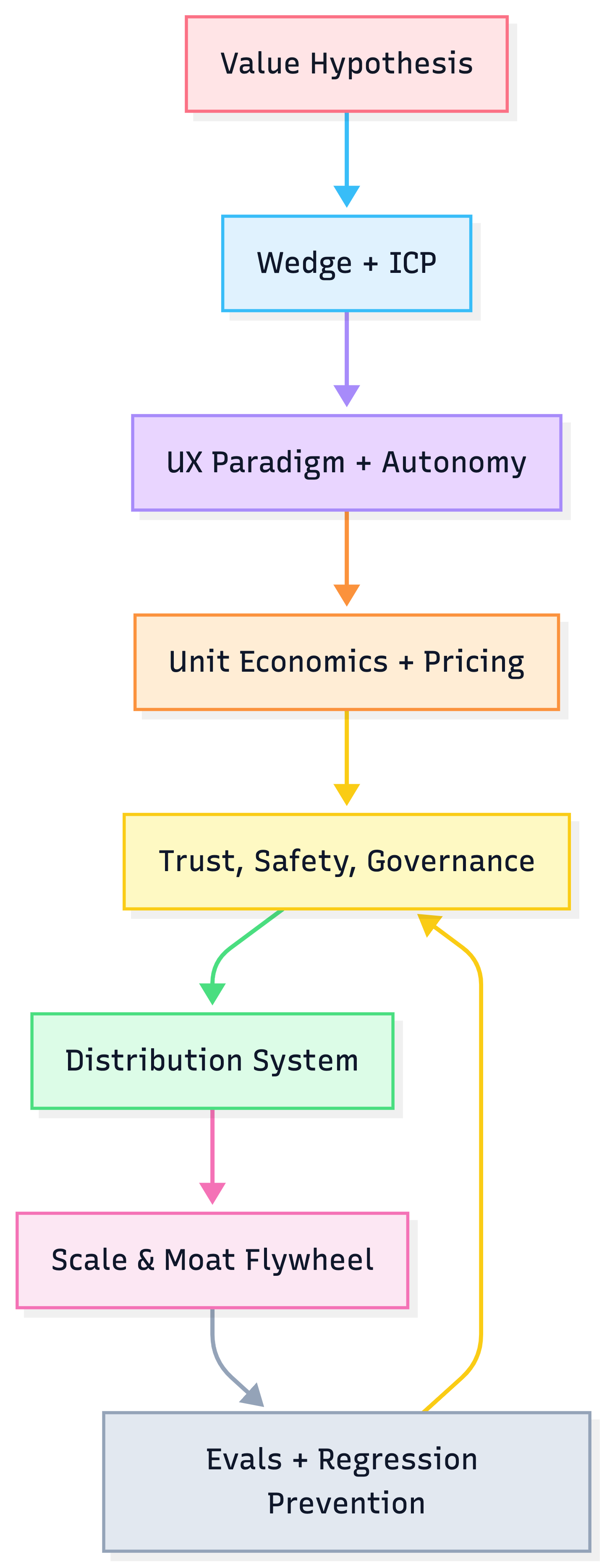
1) Direction: choosing the right wedge (7-step “AI Strategic Lens”)
- Pick the ICP + job-to-be-done (one role, one workflow)
- Map the workflow (before/after, bottlenecks)
- Choose autonomy (assist → approve → bounded autonomy)
- Decide the moat to build first (data, distribution, or trust)
- Design the feedback loop (each use improves quality/cost)
- Model unit economics early (cost per successful outcome)
- Define the eval gate (what “good” means + regression tests)
Heuristic: start at the lowest autonomy that still produces a measurable delta.
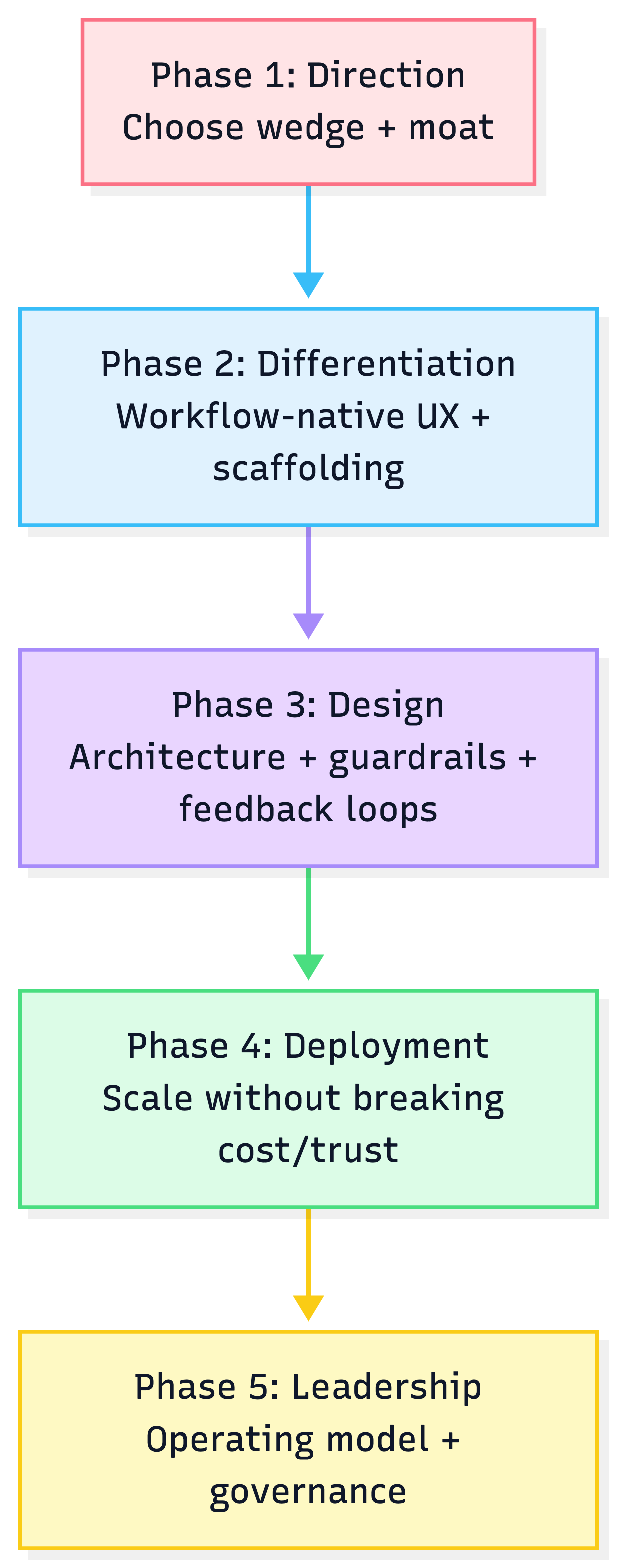
2) A 5-phase roadmap to ship & scale (use this to run programs)
3) Differentiation vs Moat (how you survive commoditized models)
Differentiation (day‑1): why users choose you now
- Workflow-native UX (inside tools they already use)
- Domain constraints (policies, templates, terminology)
- Output artifacts in real formats (PRDs, tickets, decks, filings)
- Opinionated defaults (best practices baked into flows)
Moat (month‑6+): why users can’t switch later
- Workflow moat: you become the OS of the workflow
- Data moat: unique structured feedback + labeled traces
- Trust moat: governance + reliability others can’t match
4) AI UX paradigms (choose deliberately)
| Paradigm | Best for | UX patterns | Key risk |
|---|---|---|---|
| Copilot | high ambiguity, expert user | drafts, suggestions, side-panel | “helpful but ignored” |
| Autopilot (bounded) | repetitive workflows | runbooks, approvals | silent failures |
| Multi-agent “expert room” | planning + tradeoffs | group chat + roles | confusion / too many voices |
| Tool-first agent | reliable actions | “plan → execute → verify” | tool errors cascade |
5) Unit economics: make growth a feature (not a liability)
The two curves you must model
- Value curve (user): time saved, quality improved, risk reduced
- Cost curve (you): inference + tool calls + human review + support
North-star metric: cost per successful outcome (not cost per token).
Pricing patterns that work well for agents
- Outcome-based: $ per resolved ticket / approved report / shipped PRD
- Seat + usage: base + metered heavy actions
- Tiered autonomy: assist → automate → operate
6) Distribution: wedge → loop → moat (with checklists)
Layer 1 — GTM Wedge checklist
- Solves a step users do daily
- Value in < 30 seconds
- Ships inside an existing surface (IDE, email, CRM, docs)
- Passes the “platform test” (you still win if a model vendor clones a feature)
Layer 2 — PLG Loop checklist
- Outputs share naturally (viral artifacts)
- Collaboration pulls in teammates (team loops)
- Templates and reports advertise the product
Layer 3 — Moat Flywheel checklist
- Each interaction creates moat assets
- Assets lower cost / increase quality
- Switching costs become team-wide (formats, policies, integrations)
7) Failure modes & mitigations (what breaks + how you prevent regressions)
| Failure mode | What breaks | Detection | Constraints | Regression prevention |
|---|---|---|---|---|
| Hallucination | invented facts | evals + source checks | retrieval-only; citations | golden set + canary prompts |
| Tool misuse | wrong API action | typed validation | allowlists; dry-run | replay tool traces in CI |
| Over-autonomy | unsafe actions | policy alerts | approvals; step limits | policy tests + red-team suite |
| Prompt injection | hostile overrides | anomaly signals | content isolation | injection benchmarks |
| Context rot | stale state | drift metrics | explicit state machine | versioned context + diffs |
| Cost runaway | loops | cost telemetry | budgets/timeouts | cost regression tests |
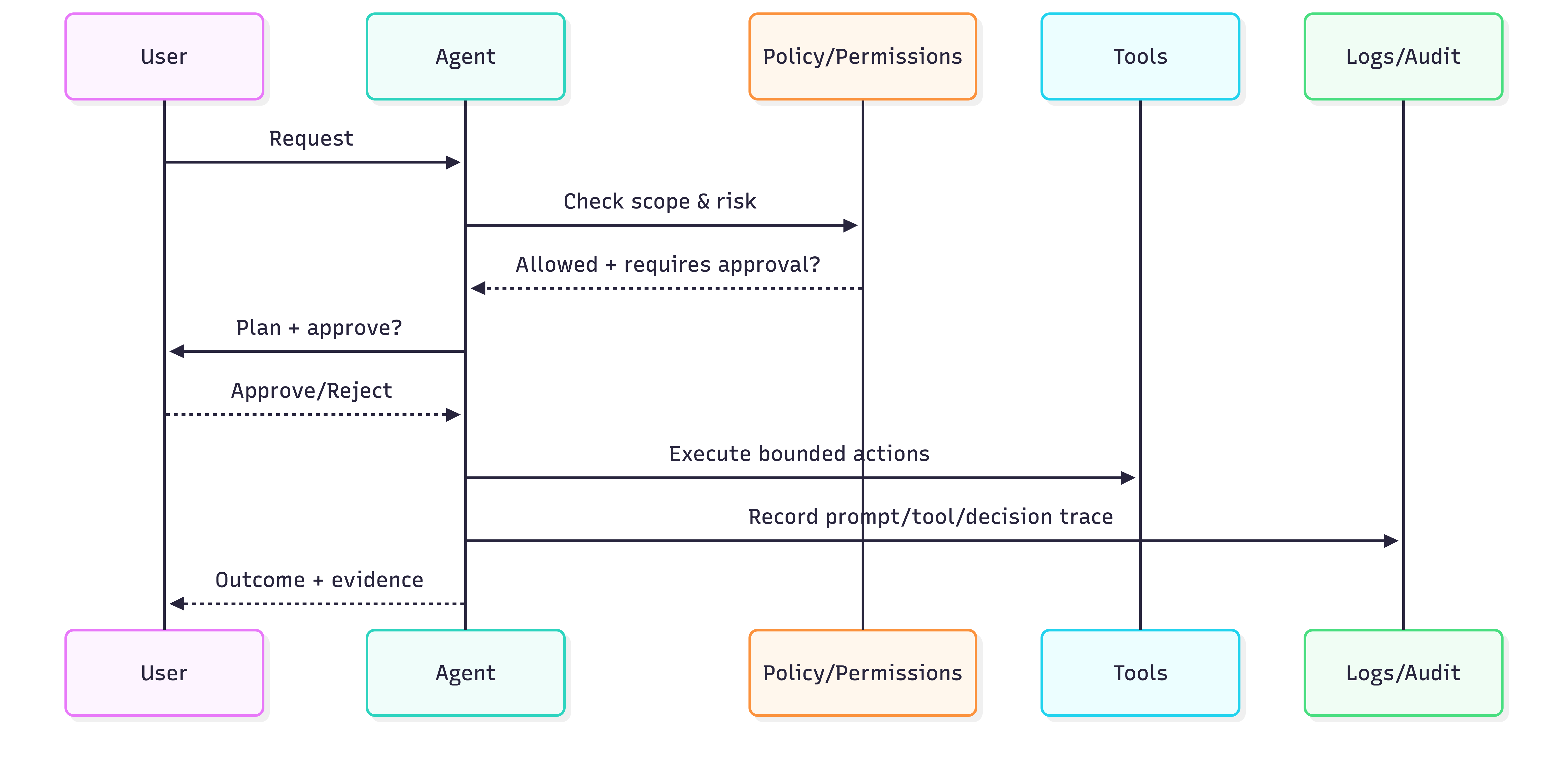
8) Governance posture (permissions, approvals, audit trails, rollout)
Governance levels (pick one per workflow)
- Read-only copilot
- Action with approval (draft → human approve → execute)
- Bounded autonomy (policy-limited, auto-approve low risk)
- Full autonomy (rare)
Minimum governance controls for agentic systems
- Identity & permissions: least privilege; scoped tokens; RBAC for tools
- Approvals: step-up auth for high-impact actions
- Audit trails: prompt + tool calls + outputs + human decisions
- Rollout strategy: flags, canary cohorts, kill switch
- Incident playbook: escalation, rollback, postmortem + eval updates
9) Operating cadence (how teams ship agent products)
The “2-week agent loop”
- Week 1: ship 1 workflow slice + instrumentation
- Week 2: fix top failure mode + expand scope slightly
What to measure (minimum)
- Activation (time-to-first-wow)
- Outcome success rate (acceptance)
- Human effort saved (minutes per task)
- Cost per outcome ($)
- Trust (override/hand-back rate)
- Safety (policy violations)
10) The AI Product Leader “Meta-Framework” (7 layers)
A compact checklist for senior leaders shipping agentic products end-to-end.
- Context depth — what the system must know (and what it must ignore)
- Intelligent interface sense — UX for uncertainty, transparency, hand-offs
- Agentic workflow thinking — task decomposition → tools → autonomy
- Reliability engineering — evals, regression gates, observability
- Economics & pricing — cost per outcome, margin-aware growth
- Governance & safety — permissions, approvals, audits, incident response
- Distribution & moat — wedge → loop → flywheel
11) Templates
A) Agent PRD (one page)
- Problem + ICP
- Workflow map (before/after)
- Wedge statement (3–5 words)
- Autonomy level + approvals
- Tools/integrations required
- Success metrics (outcome + cost + trust)
- Top 5 risks + mitigations
- Evals plan + regression gates
- Rollout plan (flags, canary, kill switch)
B) ROI worksheet (quick)
- Baseline time/task × hourly cost × volume
- Quality delta (rework reduction %)
- Risk delta (incident reduction %)
- Agent cost per task (model + tools + review)
- Net value = (time + quality + risk) − agent cost