The Challenge
Designing and deploying production MLOps systems is complex, time-consuming, and error-prone:
- Week 1-2: Requirements gathering and architecture planning
- Week 3-4: Infrastructure design and technology selection
- Week 5-8: Development, testing, and integration
- Week 9-12: Deployment, monitoring, and compliance validation
Traditional approaches require deep expertise across machine learning, software engineering, cloud infrastructure, and DevOps.
The Solution: Transform weeks of manual work into an automated, intelligent workflow:
| Traditional Approach | Agentic MLOps Platform |
|---|---|
| Manual requirements analysis (days) | AI-powered constraint extraction (minutes) |
| Architect designs system (weeks) | Multi-agent collaborative design (minutes) |
| Manual code generation (weeks) | Automated code generation with AI (minutes) |
| Manual compliance checking | Automated policy validation with feedback loops |
| Iterative debugging and fixes | Built-in critics and validators with confidence scoring |
Result: A complete, production-ready MLOps system with infrastructure code, application logic, CI/CD pipelines, and monitoring—all generated from natural language requirements.
See It In Action
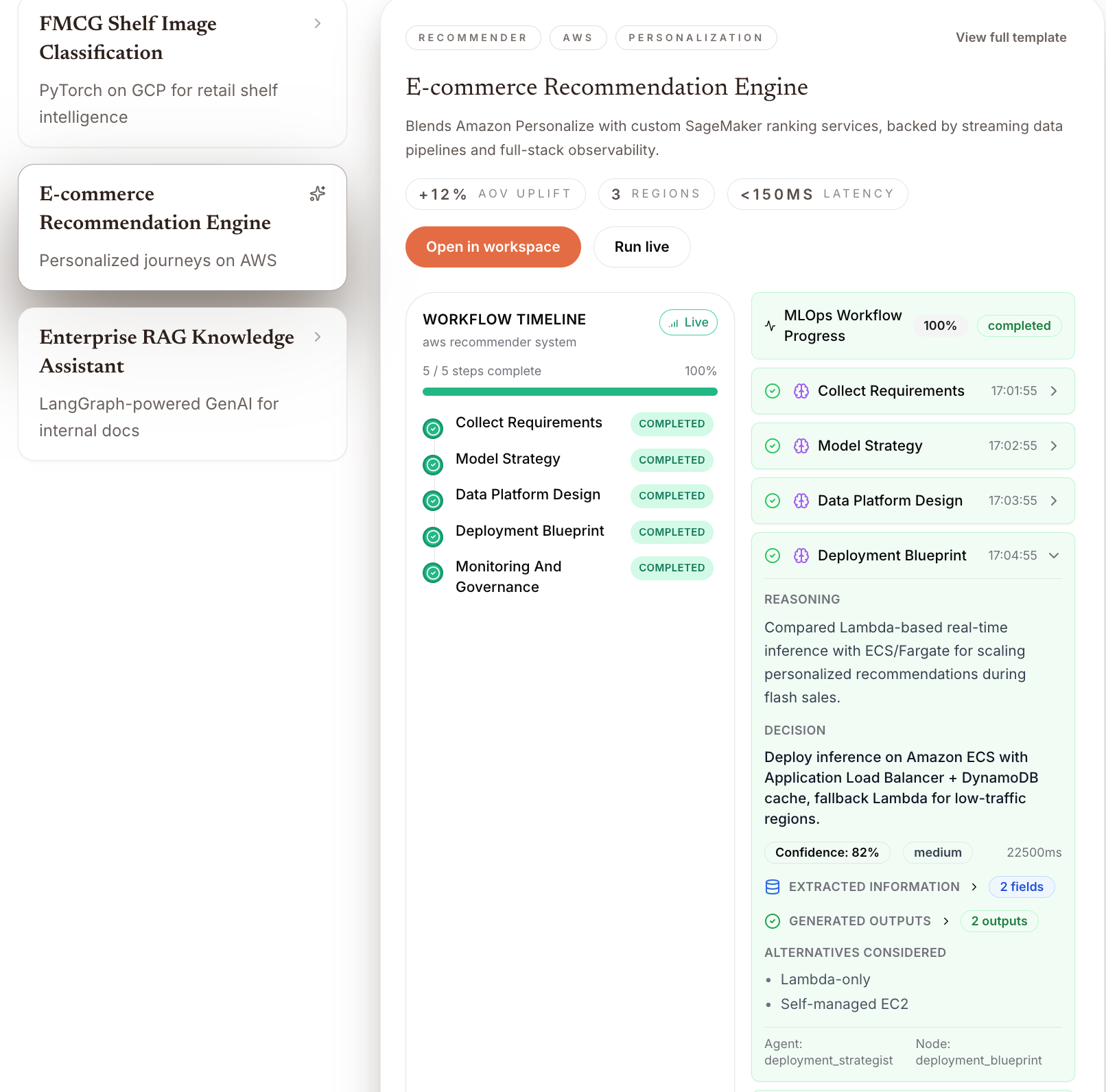
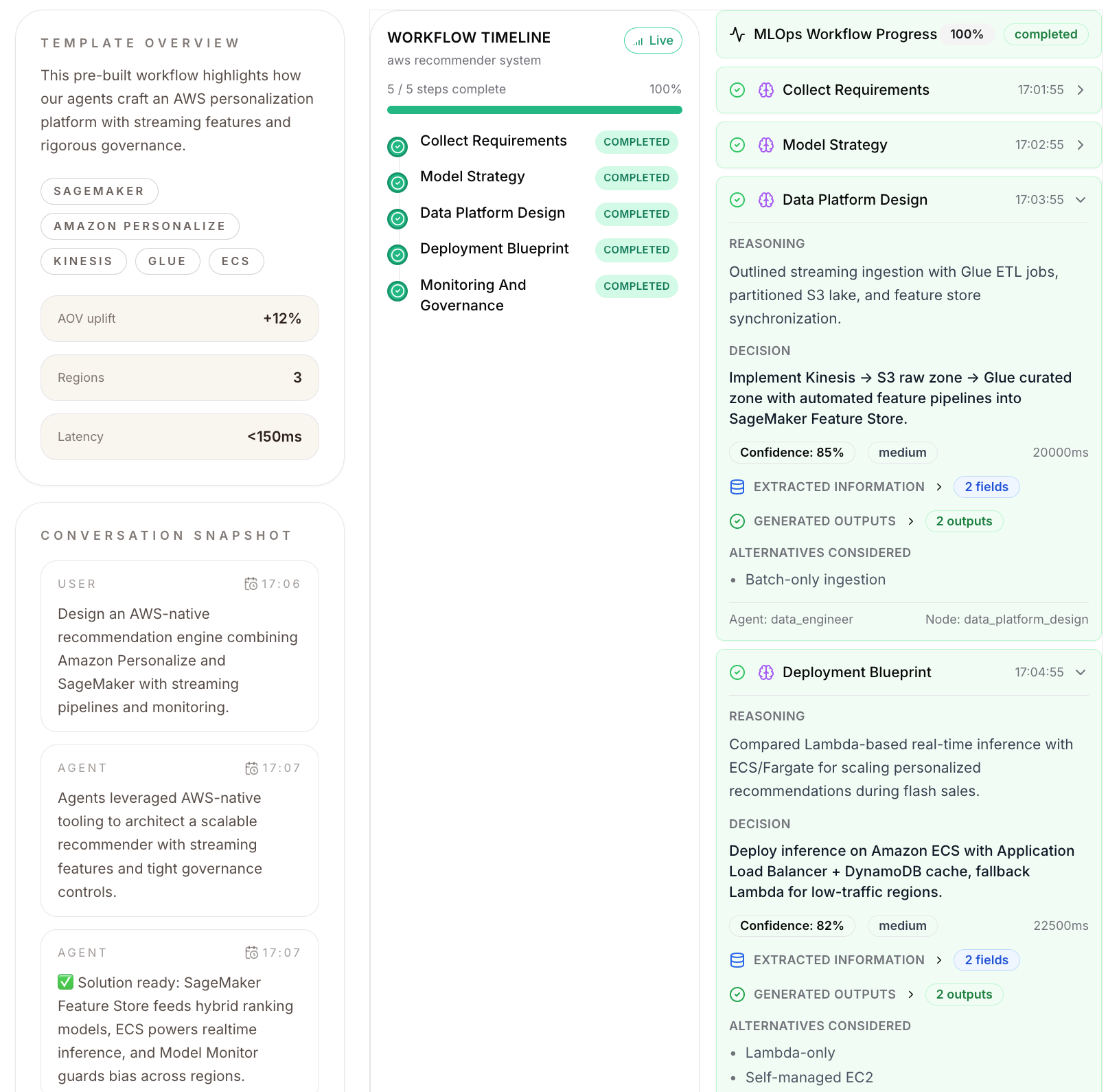
Act 1: Natural Language Input
You: "Design an MLOps system for real-time fraud detection with sub-100ms latency, PCI DSS compliance, and auto-scaling for 10,000 requests/second."
Platform Response:
- ✅ Constraint extraction initiated
- 🎯 Identified: Performance (latency, throughput), Security (PCI DSS), Scalability requirements
Act 2: Real-Time Agent Collaboration (Watch Agents Think)
Visual Streaming Interface Shows:
-
Planner Agent (GPT-4):
🧠 Reasoning: "For sub-100ms latency, recommend Lambda@Edge with DynamoDB Global Tables. PCI DSS requires encryption at rest/transit, audit logging." ✅ Confidence: 0.89 -
Feasibility Critic:
⚠️ Challenge: "Lambda@Edge has cold start issues for real-time fraud detection. Recommend ECS Fargate with Aurora Serverless v2 instead." 📊 Confidence: 0.92 -
Policy Agent:
✅ PCI DSS Validation: Passed ✅ Cost Optimization: Within budget constraints ⚠️ Recommendation: Add AWS WAF for additional security layer -
Code Generator (Claude Code):
🔨 Generating: - Terraform infrastructure (ECS, Aurora, S3, CloudWatch) - FastAPI application with sub-100ms endpoint - CI/CD pipeline (GitHub Actions) - Monitoring dashboards (CloudWatch, Prometheus)
Act 3: Production-Ready Output
Download Complete Repository:
fraud-detection-mlops/
├── infra/terraform/ # AWS infrastructure
│ ├── ecs.tf # ECS Fargate cluster
│ ├── aurora.tf # Aurora Serverless v2
│ └── waf.tf # AWS WAF rules
├── src/api/ # FastAPI application
│ ├── main.py # Sub-100ms fraud detection endpoint
│ └── models/ # ML model serving
├── .github/workflows/ # CI/CD pipelines
│ └── deploy.yml # Automated deployment
├── monitoring/ # Observability
│ └── cloudwatch-dashboard.json
└── docs/ # Architecture & compliance docs
└── PCI_DSS_compliance.md
One-Click Deploy:
cd fraud-detection-mlops
terraform init && terraform apply
# 🚀 System deployed in 8 minutes
Core Capabilities
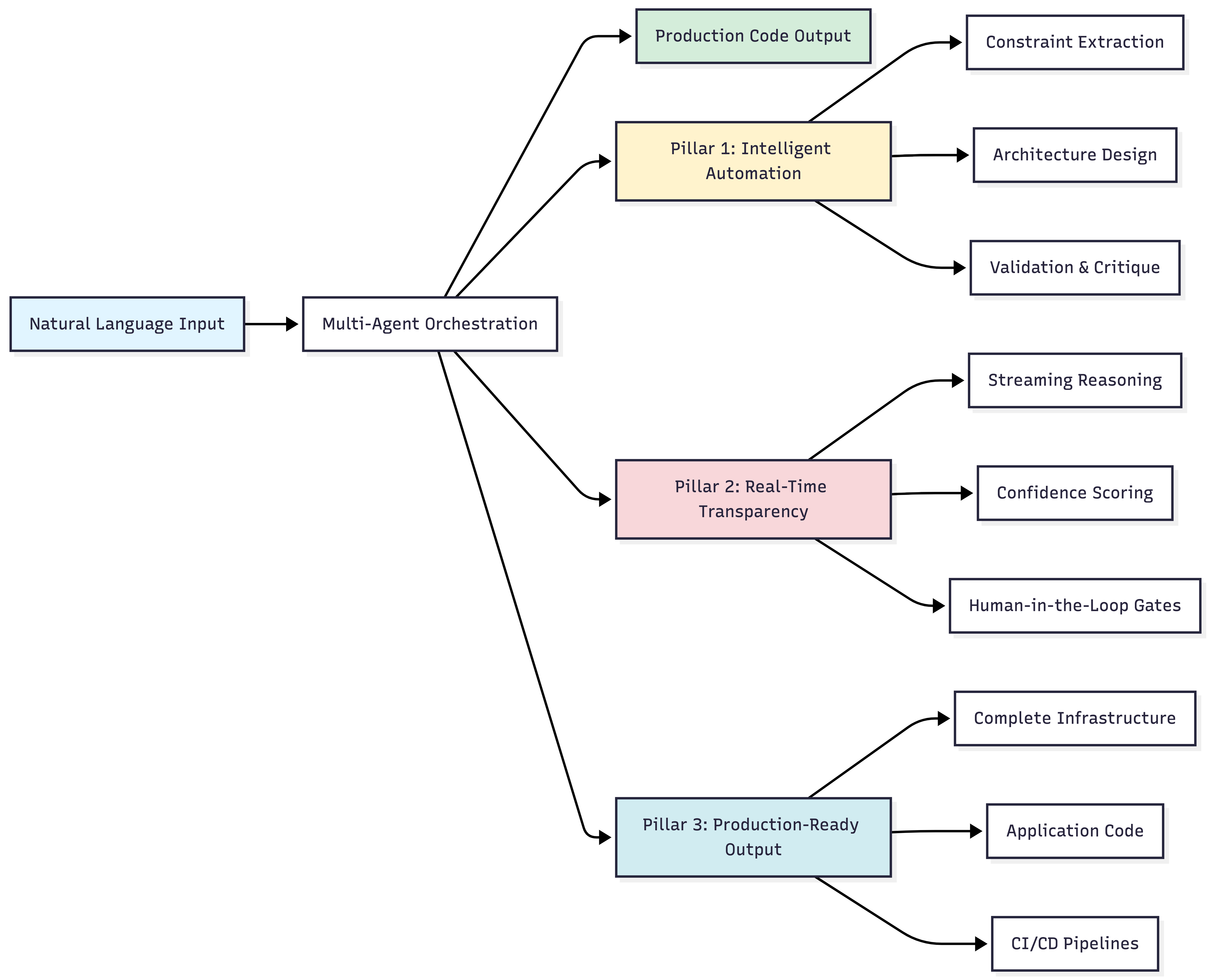
Intelligent Automation: Multi-Agent Collaboration
1. Constraint Extraction Agent
- What it does: Parses natural language requirements into structured constraints
- Technology: GPT-4 with custom prompt engineering
- Example Output:
{ "performance": {"latency_ms": 100, "throughput_rps": 10000}, "security": ["PCI_DSS", "encryption_at_rest", "encryption_in_transit"], "scalability": {"auto_scaling": true, "max_instances": 50} } - Value: Eliminates ambiguity and ensures all stakeholders are aligned
2. Planner Agent
- What it does: Designs comprehensive MLOps architecture based on constraints
- Technology: GPT-4 with RAG over AWS best practices
- Output: Detailed architecture document (compute, storage, networking, ML serving)
- Innovation: Considers cost, performance, security, and compliance simultaneously
3. Critic Agents (Feasibility, Policy, Optimization)
- Feasibility Critic: Validates technical viability and identifies potential bottlenecks
- Policy Critic: Ensures compliance with security, governance, and cost policies
- Optimization Critic: Recommends cost/performance improvements
- Technology: Specialized GPT-4 agents with domain-specific knowledge bases
- Value: Automated code review by AI experts before code generation
4. Code Generation Agent
- What it does: Generates complete, production-ready repository
- Technology: Anthropic Claude Code SDK with repository-level context
- Output:
- Terraform infrastructure code
- Application code (Python, TypeScript)
- CI/CD pipelines (GitHub Actions, GitLab CI)
- Monitoring and alerting configurations
- Documentation and README files
- Quality: Follows best practices, includes tests, and adheres to style guides
Real-Time Transparency: Watch AI Agents Think
1. Streaming Reasoning Cards
- Visual Interface: Expandable cards showing agent inputs, reasoning, and outputs
- Technology: Server-Sent Events (SSE) with FastAPI and Next.js
- User Experience:
🧠 Planner Agent [Processing...] ├─ Input: Extracted constraints (4 categories) ├─ Reasoning: "For real-time fraud detection, considering ECS Fargate │ vs Lambda. ECS provides consistent performance without cold starts..." ├─ Output: Architecture document (12 components) └─ ⚡ Confidence: 0.89 | ⏱️ Duration: 8.3s - Value: Build trust by showing AI decision-making process
2. Confidence Scoring
- What it tracks: Agent confidence in recommendations (0.0 - 1.0)
- Visualization: Color-coded badges (🟢 High: >0.85, 🟡 Medium: 0.7-0.85, 🔴 Low: <0.7)
- Use Case: Low confidence triggers human review or additional agent iterations
- Example:
⚠️ Planner Agent: Confidence 0.68 Reason: "Ambiguous latency requirement. Does 'real-time' mean <10ms or <100ms?" Action: Request clarification from user
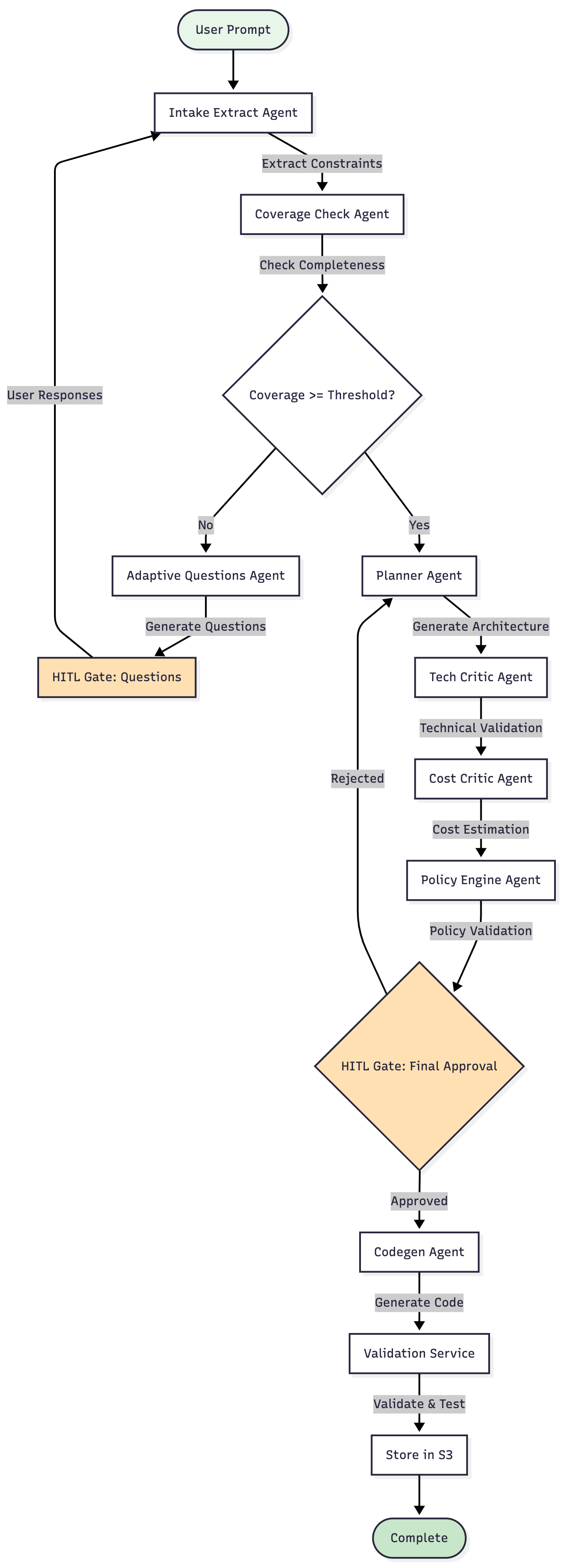
3. Human-in-the-Loop (HITL) Gates
- When it triggers:
- Agent confidence below threshold (< 0.75)
- Policy violations detected
- User explicitly requests review
- Mechanism: LangGraph interrupts workflow, waits for user approval
- Auto-Approval: Configurable timeout (default: 5 minutes) for non-critical decisions
- Value: Balance automation with human oversight
Production-Ready Output: Deploy in Minutes
1. Complete Infrastructure as Code
- Terraform Modules:
- Compute: ECS Fargate, Lambda, App Runner
- Storage: RDS, Aurora, DynamoDB, S3
- Networking: VPC, ALB, CloudFront, Route53
- Security: IAM roles, Security Groups, KMS encryption
- Monitoring: CloudWatch, X-Ray, Prometheus
- Best Practices:
- Modular design with reusable components
- Environment-specific configurations (dev, staging, prod)
- Remote state management with S3 + DynamoDB locking
- Automated testing with
terraform planandtflint
2. Application Code with Tests
- API Layer: FastAPI with async/await, Pydantic validation, OpenAPI docs
- Business Logic: Clean architecture with dependency injection
- ML Model Serving: TensorFlow Serving, PyTorch Serve, or custom inference
- Tests:
- Unit tests (pytest with 80%+ coverage)
- Integration tests (TestClient for API endpoints)
- E2E tests (Playwright for full workflows)
- Code Quality: Pre-commit hooks with Black, Ruff, MyPy
3. CI/CD Pipelines
- GitHub Actions Workflow:
name: Deploy to Production on: [push] jobs: test: runs-on: ubuntu-latest steps: - Run linters (Black, Ruff, ESLint) - Run unit tests (pytest, Jest) - Run integration tests deploy: needs: test steps: - Build Docker images - Push to ECR - Deploy to App Runner - Run smoke tests - Notify Slack on success/failure - Deployment Targets: AWS App Runner, ECS, Lambda, Kubernetes
- Rollback Strategy: Automated rollback on health check failures
4. Monitoring & Observability
- CloudWatch Dashboards: Pre-configured with key metrics (latency, error rate, throughput)
- Alarms: Automated alerts for anomalies (CPU > 80%, error rate > 1%)
- Distributed Tracing: AWS X-Ray integration for request flow visualization
- Logging: Structured logging with JSON format, centralized with CloudWatch Logs
- Custom Metrics: Business KPIs (model accuracy, prediction confidence, drift detection)
System Architecture
System Overview
Key Components:
-
Frontend (Next.js 14):
- App Router: Server-side rendering for SEO and performance
- Streaming UI: Real-time reason cards with SSE
- Responsive Design: Tailwind CSS with mobile-first approach
- State Management: React hooks with Zustand for global state
-
API Server (FastAPI):
- Async/Await: Non-blocking I/O for handling 1000+ concurrent connections
- Integrated Worker: Background job processing in same process (simplified deployment)
- SSE Streaming: Real-time agent reasoning updates to frontend
- REST API: CRUD operations for jobs, workflows, artifacts
-
LangGraph Orchestration:
- StateGraph: Deterministic multi-agent workflows with checkpointing
- Conditional Routing: Dynamic agent selection based on confidence scores
- Human-in-the-Loop: Interrupt/resume with user approval gates
- Persistence: PostgreSQL checkpoints for crash recovery and replay
-
Multi-Agent System:
- Constraint Extractor: NLP parsing of natural language requirements
- Planner: Architecture design with AWS best practices
- Critics: Automated validation (feasibility, policy, optimization)
- Code Generator: Repository-level code generation with Claude Code SDK
-
Data Persistence:
- PostgreSQL: Job queue, LangGraph checkpoints, user data
- S3: Generated code artifacts (zipped repositories)
- RDS Proxy: Connection pooling for serverless scalability
Tech Stack & Rationale
| Category | Technology | Why This Choice? |
|---|---|---|
| Backend Framework | FastAPI | Async/await for SSE streaming, automatic OpenAPI docs, Pydantic validation, 3x faster than Flask |
| Frontend Framework | Next.js 14 | App Router for SSR, built-in SSE support, TypeScript safety, React ecosystem |
| Agent Orchestration | LangGraph | Deterministic workflows, built-in checkpointing, HITL gates, better than LangChain for complex agents |
| Language Models | GPT-4 Turbo + Claude 3.5 Sonnet | GPT-4 for reasoning (planner, critics), Claude for code generation (superior repo-level context) |
| Real-time Streaming | Server-Sent Events (SSE) | Simpler than WebSockets (no handshake), HTTP/2 multiplexing, auto-reconnect, works with CDN/proxies |
| Database | PostgreSQL | LangGraph native support, JSONB for semi-structured data, FOR UPDATE SKIP LOCKED for job queue |
| Object Storage | AWS S3 | Scalable artifact storage, versioning, presigned URLs for secure downloads, industry-leading durability |
| Job Queue | Database-backed (PostgreSQL) | No extra infra (Redis/SQS), ACID guarantees, integrated with LangGraph checkpoints |
| Deployment | AWS App Runner | Zero-config autoscaling, built-in load balancing, managed SSL, simpler than ECS/EKS |
| IaC | Terraform | Multi-cloud support (vs CloudFormation), state management, reusable modules, mature ecosystem |
| API Client | OpenAI SDK + Anthropic SDK | Official SDKs with retry logic, streaming support, type hints |
| Type Safety | TypeScript + Pydantic | Compile-time checks (TS), runtime validation (Pydantic), shared schemas with openapi-typescript |
| Styling | Tailwind CSS | Utility-first for rapid prototyping, tree-shaking for small bundles, no runtime CSS-in-JS overhead |
| Testing | Pytest + Playwright | Async test support (pytest-asyncio), E2E browser testing (Playwright), parallel execution |
| Monitoring | CloudWatch + Structured Logging | Native AWS integration, JSON logs for parsing, custom metrics, alarms with SNS |
Why NOT Other Technologies?
- Why Not LangChain?: Less control over agent workflows, harder to debug, no built-in checkpointing
- Why Not Redis for Job Queue?: Additional infrastructure complexity, eventual consistency issues, doesn't integrate with LangGraph state
- Why Not WebSockets?: Requires bidirectional communication (overkill), harder to scale with load balancers, no auto-reconnect
- Why Not Kubernetes?: Over-engineered for current scale, App Runner provides auto-scaling without YAML complexity
- Why Not GraphQL?: REST sufficient for current use case, SSE handles real-time updates, no need for graph queries
Architecture Diagrams
User Workflow
Multi-Agent Decision Flow
Database Schema
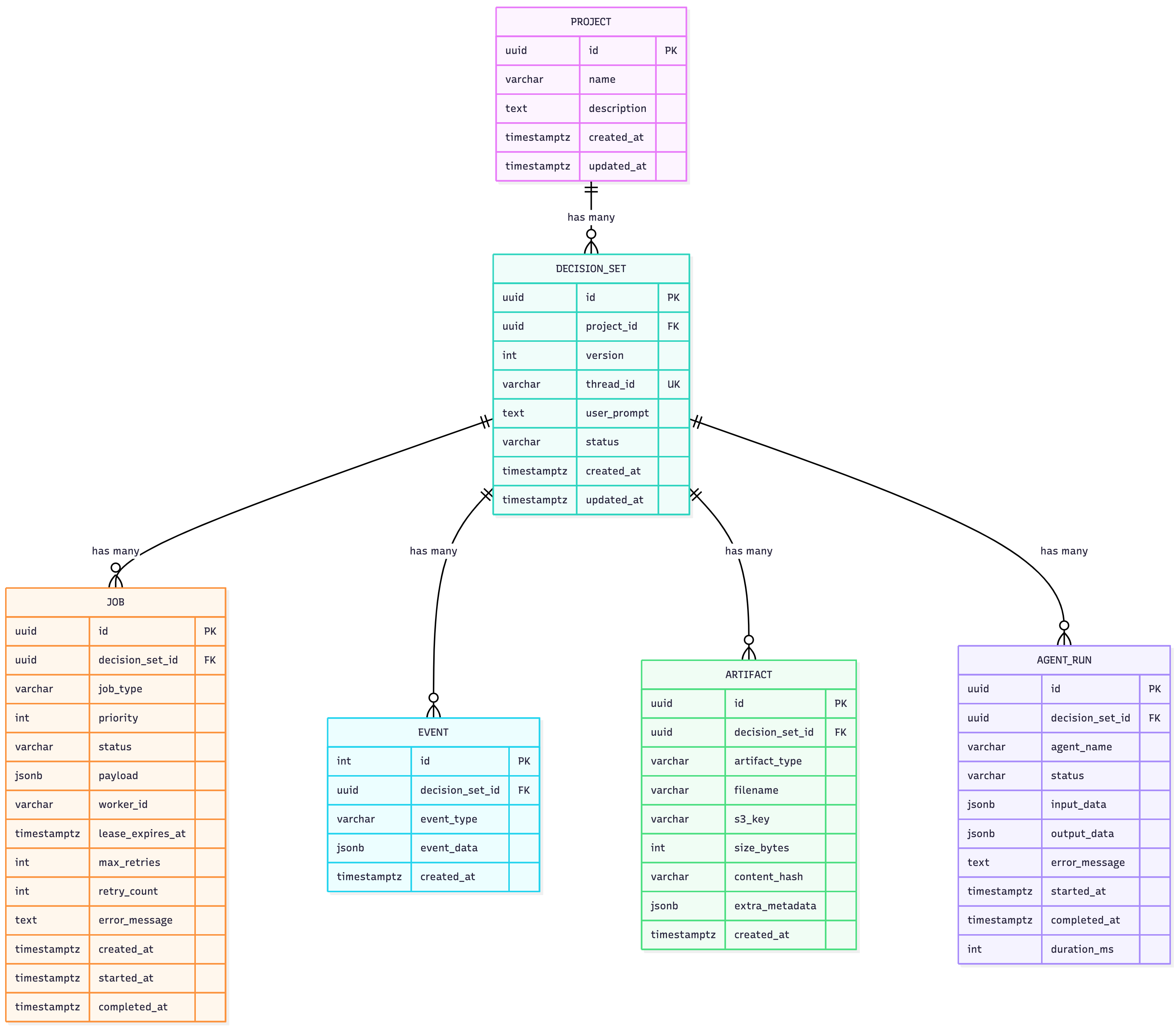
Key Schema Design Decisions:
-
Jobs Table:
- JSONB for constraints: Flexible schema for varying constraint types
- UUID primary key: Distributed system compatibility, no collisions
- Status enum: Clear job lifecycle (pending → processing → completed/failed)
- Confidence score: Tracks overall workflow confidence
-
Checkpoints Table (LangGraph):
- JSONB state: Stores entire agent state for replay/debugging
- Sequence number: Enables time-travel debugging
- Parent checkpoint: Supports nested subgraphs
- Indexed by thread_id + checkpoint_ns: Fast lookup for workflow resumption
-
Writes Table (LangGraph):
- Pending writes: Buffers state updates before commit
- Channel-based: Separates agent outputs (e.g.,
planner_output,critic_feedback) - Ordered by idx: Ensures deterministic replay
-
Agents Table:
- Metadata tracking: Monitor agent performance over time
- Config versioning: A/B test different prompts/models
Streaming Architecture
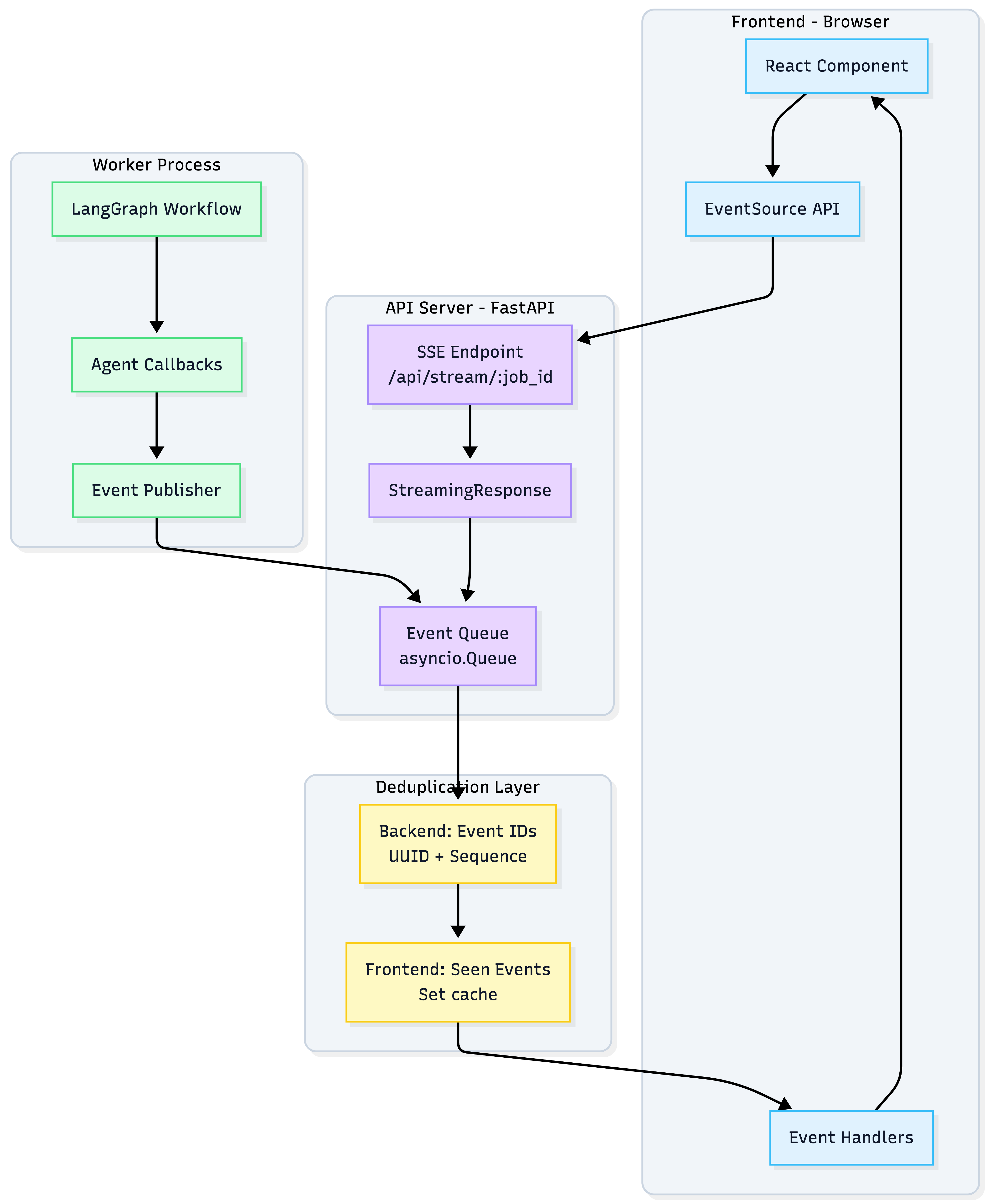
SSE Implementation Details:
-
Backend (FastAPI):
@app.get("/api/stream/{job_id}") async def stream_events(job_id: str): async def event_generator(): queue = get_or_create_queue(job_id) last_event_id = 0 while True: event = await queue.get() # Deduplication: Assign unique event ID event_id = f"{job_id}:{last_event_id}" last_event_id += 1 yield { "event": event["type"], "data": json.dumps(event["data"]), "id": event_id, # Client can use for reconnection "retry": 3000 # Reconnect after 3 seconds } if event["type"] == "job_complete": break return StreamingResponse( event_generator(), media_type="text/event-stream", headers={ "Cache-Control": "no-cache", "Connection": "keep-alive", "X-Accel-Buffering": "no" # Disable nginx buffering } ) -
Frontend (Next.js):
const eventSource = new EventSource(`/api/stream/${jobId}`); const seenEventIds = new Set<string>(); eventSource.onmessage = (event) => { // Frontend deduplication (backup) if (seenEventIds.has(event.lastEventId)) { return; // Skip duplicate } seenEventIds.add(event.lastEventId); const data = JSON.parse(event.data); updateReasonCard(data); }; eventSource.onerror = (error) => { console.error("SSE error:", error); // EventSource auto-reconnects using Last-Event-ID header }; -
Connection Resilience:
- Auto-reconnect: EventSource API automatically reconnects with
Last-Event-IDheader - Event replay: Backend can resend missed events since last received ID
- Heartbeat: Send
comment: pingevery 30 seconds to keep connection alive - Graceful shutdown: Send
event: closeto signal client to stop reconnecting
- Auto-reconnect: EventSource API automatically reconnects with
Job Queue Pattern
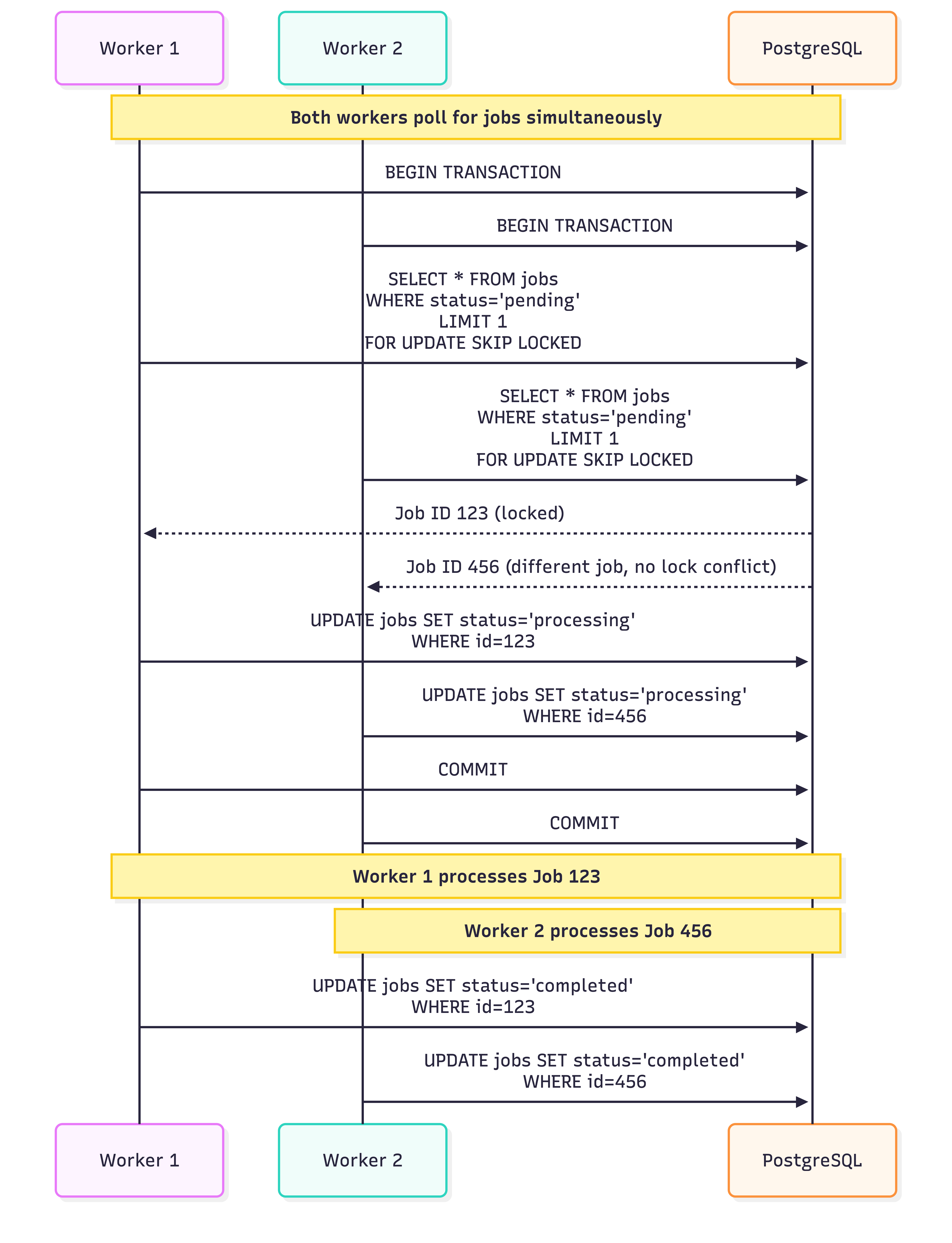
Why FOR UPDATE SKIP LOCKED?
- FOR UPDATE: Locks selected rows, preventing other transactions from modifying them
- SKIP LOCKED: Skips rows already locked by other transactions (instead of waiting)
- Result: Each worker gets a different job, zero race conditions, no deadlocks
Alternative Approaches (and why we didn't use them):
| Approach | Problem |
|---|---|
SELECT ... LIMIT 1 without lock |
Race condition: 2 workers can select same job |
FOR UPDATE without SKIP LOCKED |
Workers wait for lock, inefficient with many workers |
| Redis-based queue (BRPOP) | Additional infrastructure, eventual consistency, doesn't integrate with LangGraph checkpoints |
| SQS + Lambda | Cold starts, higher cost, harder to debug, no built-in checkpointing |
Tech Stack Visualization
Performance & Scalability
Auto-Scaling Configuration (AWS App Runner)
AutoScaling:
MinSize: 1 # Always 1 instance running (avoid cold starts)
MaxSize: 25 # Scale up to 25 instances under load
Concurrency: 100 # Max 100 concurrent requests per instance
Scaling Triggers:
- CPU > 70% for 2 minutes → Add instance
- Memory > 80% → Add instance
- Concurrent requests > 80 → Add instance
- Scale down after 5 minutes of low traffic
Target Performance Characteristics:
- Cold start: Minimal (AWS App Runner maintains warm instances)
- Request latency: Sub-second response times for API endpoints
- SSE connection setup: Near-instant real-time streaming
- Agent workflow (end-to-end): Typically 3-5 minutes for complete MLOps design
- Database query latency: Optimized via RDS Proxy connection pooling
Connection Pooling (RDS Proxy)
# SQLAlchemy async engine with connection pooling
engine = create_async_engine(
DATABASE_URL,
pool_size=20, # Max 20 connections per App Runner instance
max_overflow=10, # Allow 10 additional connections during burst
pool_pre_ping=True, # Verify connection health before use
pool_recycle=3600, # Recycle connections every hour
echo=False # Disable SQL logging in production
)
# RDS Proxy Configuration
RDSProxy:
MaxConnectionsPercent: 100 # Use all available RDS connections
MaxIdleConnectionsPercent: 50
ConnectionBorrowTimeout: 120 # 2 minutes
InitQuery: "SET TIME ZONE 'UTC'"
Benefits:
- No connection exhaustion: RDS Proxy pools connections across all App Runner instances
- Failover: AWS RDS Proxy provides automatic failover capabilities
- IAM authentication: No hardcoded database credentials
Event Deduplication Strategy
Problem: SSE connections can receive duplicate events during:
- Network reconnections
- Load balancer failover
- Browser tab backgrounding (mobile Safari)
Solution: Two-Layer Deduplication
-
Backend Layer (FastAPI):
# Assign monotonic event IDs event_id = f"{job_id}:{sequence_number}" # Client can reconnect with Last-Event-ID header @app.get("/api/stream/{job_id}") async def stream_events( job_id: str, request: Request ): last_event_id = request.headers.get("Last-Event-ID") if last_event_id: # Replay events since last_event_id start_seq = int(last_event_id.split(":")[1]) + 1 else: start_seq = 0 # Stream events starting from start_seq -
Frontend Layer (React):
const seenEventIds = new Set<string>(); eventSource.onmessage = (event) => { if (seenEventIds.has(event.lastEventId)) { console.warn("Duplicate event:", event.lastEventId); return; // Skip } seenEventIds.add(event.lastEventId); handleEvent(event.data); };
Result: Two-layer deduplication prevents duplicate events in production
Caching Strategy
1. LLM Response Caching (Prompt Caching)
# Use Anthropic's prompt caching for repeated system prompts
response = anthropic.messages.create(
model="claude-3.5-sonnet",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # 5000 tokens
"cache_control": {"type": "ephemeral"} # Cache for 5 minutes
}
],
messages=[{"role": "user", "content": user_message}]
)
# Savings: 90% cost reduction on cached prompts (5000 tokens cached, 500 tokens fresh)
2. Database Query Caching
# Cache frequent queries (e.g., agent configurations)
from functools import lru_cache
@lru_cache(maxsize=128)
async def get_agent_config(agent_type: str) -> dict:
# Cached in memory, refresh every 5 minutes
return await db.execute(...)
3. S3 Artifact Caching
- CloudFront CDN for frequently downloaded artifacts
- Presigned URLs with 1-hour expiration
Scalability Considerations
System Design:
- Auto-scaling architecture with AWS App Runner (1-25 instances)
- Database connection pooling via RDS Proxy
- Asynchronous job processing with PostgreSQL-backed queue
Potential Bottlenecks:
- LLM API rate limits: OpenAI/Anthropic rate limits may affect concurrent workflow processing
- Mitigation: Implemented exponential backoff + queue throttling
- Database checkpoint writes: Frequent checkpointing for LangGraph state persistence
- Optimization: Configurable checkpoint batching to reduce write volume
Engineering Deep Dives
Challenge 1: SSE Streaming Duplicate Events & Connection Resilience
The Problem: During development of the real-time agent reasoning interface, users experienced:
- Duplicate reason cards appearing in the UI during network interruptions
- Lost events when mobile browsers backgrounded tabs (iOS Safari)
- Connection storms when load balancer switched instances
Root Causes:
- EventSource auto-reconnect: Browser automatically reconnects SSE on network error, but backend had no deduplication
- Load balancer failover: App Runner replaced unhealthy instance, new instance re-sent events from job start
- No event replay mechanism: Clients couldn't request missed events during disconnection
Investigation Process:
# Reproduced issue with network throttling
curl -N http://localhost:8000/api/stream/test-job-123 \
--limit-rate 1K \
--max-time 5
# Observed in logs:
[INFO] SSE connection established: job=test-job-123, client=192.168.1.5
[INFO] Sent event: planner_complete (event_id=1)
[INFO] Sent event: critic_complete (event_id=2)
[ERROR] Client disconnected: job=test-job-123
[INFO] SSE connection established: job=test-job-123, client=192.168.1.5
[INFO] Sent event: planner_complete (event_id=1) # DUPLICATE!
[INFO] Sent event: critic_complete (event_id=2) # DUPLICATE!
Solution: Two-Layer Deduplication + Event Replay
-
Backend: Monotonic Event IDs + Replay Support
# Before: No event tracking async def event_generator(job_id: str): queue = get_queue(job_id) while True: event = await queue.get() yield f"data: {json.dumps(event)}\n\n" # After: Event IDs + replay from Last-Event-ID async def event_generator(job_id: str, request: Request): last_event_id = request.headers.get("Last-Event-ID", "0") start_seq = int(last_event_id.split(":")[-1]) + 1 # Replay missed events from persistent storage missed_events = await get_events_since(job_id, start_seq) for event in missed_events: yield format_sse_event(event) # Stream new events queue = get_queue(job_id) seq = start_seq + len(missed_events) while True: event = await queue.get() event_id = f"{job_id}:{seq}" seq += 1 # Store event for replay (Redis with 1-hour TTL) await store_event(job_id, seq, event) yield f"id: {event_id}\ndata: {json.dumps(event)}\n\n" -
Frontend: Client-Side Deduplication
// Before: No duplicate handling eventSource.onmessage = (event) => { const data = JSON.parse(event.data); addReasonCard(data); // Could add duplicates }; // After: Track seen events const seenEventIds = useRef(new Set<string>()); eventSource.onmessage = (event) => { if (seenEventIds.current.has(event.lastEventId)) { console.debug("Skipping duplicate event:", event.lastEventId); return; } seenEventIds.current.add(event.lastEventId); const data = JSON.parse(event.data); addReasonCard(data); }; -
Connection Health Monitoring
# Send heartbeat every 30 seconds to keep connection alive async def event_generator(job_id: str, request: Request): # ... setup code ... while True: try: event = await asyncio.wait_for( queue.get(), timeout=30.0 # Heartbeat interval ) yield format_sse_event(event) except asyncio.TimeoutError: # No events for 30s, send heartbeat yield ": heartbeat\n\n" # SSE comment (ignored by client)
Solution Benefits:
- ✅ Duplicate prevention through two-layer deduplication (backend + frontend)
- ✅ Connection resilience handles mobile tab backgrounding and network interruptions
- ✅ Event replay supports reconnection with missed event delivery
- ✅ Transparent failover with automatic reconnection during infrastructure changes
Lessons Learned:
- Always assign event IDs: SSE
id:field is critical for reconnection logic - Store events temporarily: Redis with TTL is perfect for event replay buffer
- Test with network failures: Use
tc(traffic control) to simulate packet loss, latency spikes - Frontend deduplication is a backup: Backend should be the source of truth, but client-side check prevents UI bugs
References:
- MDN EventSource API: https://developer.mozilla.org/en-US/docs/Web/API/EventSource
- SSE Spec (WHATWG): https://html.spec.whatwg.org/multipage/server-sent-events.html
- LangGraph Streaming Docs: https://langchain-ai.github.io/langgraph/how-tos/streaming/
Challenge 2: Database-Backed Job Queue with Race Condition Prevention
The Problem: Initially planned to use Redis + Celery for job queue, but faced issues:
- Race conditions: Multiple workers picked up the same job during high load
- Lost jobs: Redis crashes lost in-flight jobs (no persistence enabled)
- Complexity: Separate Redis instance, Celery worker processes, result backend
Initial Broken Implementation:
# Worker polling logic (BROKEN)
async def poll_jobs():
while True:
# Race condition: Two workers can SELECT same job
job = await db.execute(
"SELECT * FROM jobs WHERE status = 'pending' LIMIT 1"
)
if job:
# Worker 1 and Worker 2 both update same job!
await db.execute(
"UPDATE jobs SET status = 'processing' WHERE id = :id",
{"id": job.id}
)
await process_job(job)
await asyncio.sleep(1)
Failure Scenario:
Time | Worker 1 | Worker 2
------+------------------------------+---------------------------
T0 | SELECT job_123 (pending) | SELECT job_123 (pending)
T1 | UPDATE job_123 (processing) | UPDATE job_123 (processing)
T2 | Start processing job_123 | Start processing job_123
| ❌ DUPLICATE WORK | ❌ DUPLICATE WORK
Solution: PostgreSQL FOR UPDATE SKIP LOCKED
# Corrected implementation
async def poll_jobs():
while True:
async with db.begin(): # Start transaction
result = await db.execute(
text("""
SELECT * FROM jobs
WHERE status = 'pending'
ORDER BY created_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED
""")
)
job = result.fetchone()
if job:
# Update status within same transaction
await db.execute(
text("""
UPDATE jobs
SET status = 'processing',
updated_at = NOW()
WHERE id = :id
"""),
{"id": job.id}
)
# COMMIT transaction (lock released)
if job:
try:
await process_job(job)
await mark_job_completed(job.id)
except Exception as e:
await mark_job_failed(job.id, str(e))
else:
await asyncio.sleep(1) # No jobs, wait before polling again
How FOR UPDATE SKIP LOCKED Works:
- FOR UPDATE: Locks selected rows, preventing other transactions from reading/modifying them
- SKIP LOCKED: If rows are already locked by another transaction, skip them and select next available row
- Result: Each worker gets a different job, guaranteed by database ACID properties
Comparison with Redis-based Queue:
| Feature | Redis (BRPOP) | PostgreSQL (FOR UPDATE SKIP LOCKED) |
|---|---|---|
| Race conditions | Possible (network delays) | Impossible (ACID guarantees) |
| Job persistence | Optional (RDB/AOF) | Built-in (ACID) |
| Transaction support | Limited (Lua scripts) | Full ACID transactions |
| Integration with LangGraph | Requires custom adapter | Native support via checkpointer |
| Infrastructure | Separate Redis instance | Reuse existing PostgreSQL |
| Debugging | Separate logs | Unified with application DB |
| Dead letter queue | Manual implementation | Database triggers + error tables |
Additional Optimizations:
-
Job Priority:
SELECT * FROM jobs WHERE status = 'pending' ORDER BY priority DESC, -- High priority first created_at ASC -- FIFO within same priority LIMIT 1 FOR UPDATE SKIP LOCKED -
Stale Job Recovery (handles worker crashes):
# Periodic task: Reset jobs stuck in "processing" for > 10 minutes async def recover_stale_jobs(): await db.execute(text(""" UPDATE jobs SET status = 'pending', updated_at = NOW() WHERE status = 'processing' AND updated_at < NOW() - INTERVAL '10 minutes' """)) -
Dead Letter Queue:
# After 3 failed attempts, move to DLQ await db.execute(text(""" UPDATE jobs SET status = 'failed', error_message = :error WHERE id = :id AND retry_count >= 3 """))
Solution Benefits:
- High throughput potential with PostgreSQL
FOR UPDATE SKIP LOCKEDpattern - Low latency job assignment without race conditions
- ACID guarantees prevent lost jobs and ensure exactly-once processing
- Crash resilience through database persistence and stale job recovery
Lessons Learned:
- Database-backed queues are underrated: For low-to-medium scale (< 1000 jobs/sec), PostgreSQL is simpler than Redis + Celery
- SKIP LOCKED is a game-changer: Available in PostgreSQL 9.5+, MySQL 8.0+, Oracle 12c+
- Integrated checkpointing wins: LangGraph checkpoints + job queue in same DB simplifies debugging
- Test with multiple workers: Use
pytest-xdistto run tests with 10+ parallel workers
References:
- PostgreSQL FOR UPDATE SKIP LOCKED: https://www.postgresql.org/docs/current/sql-select.html#SQL-FOR-UPDATE-SHARE
- LangGraph PostgreSQL Checkpointer: https://langchain-ai.github.io/langgraph/how-tos/persistence/
Challenge 3: LangGraph State Schema Consolidation
The Problem: Early LangGraph implementation used separate state schemas for each agent, leading to:
- State explosion: 15 different
TypedDictschemas for different agent steps - Type casting errors: Passing
PlannerOutputtoCriticInputrequired manual conversion - Checkpoint bloat: 500KB checkpoints (mostly duplicate data across schemas)
- Debugging nightmare: Hard to trace state evolution across agents
Initial Fragmented Implementation:
# Before: 15 separate state schemas
class ConstraintExtractorInput(TypedDict):
user_requirements: str
class ConstraintExtractorOutput(TypedDict):
constraints: dict[str, Any]
confidence: float
class PlannerInput(TypedDict):
constraints: dict[str, Any] # Duplicate from ConstraintExtractorOutput
class PlannerOutput(TypedDict):
architecture_plan: str
components: list[str]
confidence: float
class CriticInput(TypedDict):
architecture_plan: str # Duplicate from PlannerOutput
constraints: dict[str, Any] # Duplicate again!
# ... 10 more schemas
# Agent nodes had to manually map between schemas
def planner_node(state: PlannerInput) -> PlannerOutput:
# ... planning logic
return PlannerOutput(...)
def critic_node(state: CriticInput) -> CriticOutput:
# Manual conversion from PlannerOutput to CriticInput
# Error-prone and verbose!
pass
Issues Encountered:
-
KeyError during state access:
# Critic tried to access field not in CriticInput def feasibility_critic(state: CriticInput): components = state["components"] # KeyError: 'components' not in CriticInput -
Checkpoint size explosion:
{ "checkpoint_id": "abc123", "state": { "constraints": {...}, // 50 KB "architecture_plan": "...", // 30 KB "critic_feedback": [...], // 20 KB // ... duplicated across 15 schemas } } // Total: 500 KB per checkpoint! -
Type safety loss:
# Had to use cast() everywhere, defeating purpose of type hints from typing import cast def route_to_critic(state: PlannerOutput) -> str: critic_input = cast(CriticInput, { "architecture_plan": state["architecture_plan"], "constraints": ??? # Where to get this? })
Solution: Consolidated State Schema
from typing import TypedDict, Annotated
from langgraph.graph import add_messages
class AgentState(TypedDict):
"""Single source of truth for entire workflow."""
# User input
user_requirements: str
# Constraint extraction
extracted_constraints: dict[str, Any]
constraint_confidence: float
# Planning
architecture_plan: str
planned_components: list[str]
plan_confidence: float
# Critics
feasibility_feedback: list[dict]
policy_feedback: list[dict]
optimization_feedback: list[dict]
overall_critic_score: float
# Code generation
generated_artifact_url: str | None
generation_errors: list[str]
# Workflow control
workflow_status: Literal["running", "hitl_required", "completed", "failed"]
current_agent: str
# Messages (for LangGraph's add_messages reducer)
messages: Annotated[list[BaseMessage], add_messages]
# All agents now use same state schema
def constraint_extractor(state: AgentState) -> AgentState:
# Extract constraints
constraints = extract_constraints(state["user_requirements"])
# Return partial update (LangGraph merges with existing state)
return {
"extracted_constraints": constraints,
"constraint_confidence": 0.92,
"current_agent": "constraint_extractor"
}
def planner(state: AgentState) -> AgentState:
# Access constraints without type casting
constraints = state["extracted_constraints"] # ✅ Type-safe
plan = create_plan(constraints)
return {
"architecture_plan": plan,
"plan_confidence": 0.87,
"current_agent": "planner"
}
def feasibility_critic(state: AgentState) -> AgentState:
# Access both plan and constraints (no manual mapping needed)
plan = state["architecture_plan"]
constraints = state["extracted_constraints"]
feedback = critique_feasibility(plan, constraints)
return {
"feasibility_feedback": feedback,
"current_agent": "feasibility_critic"
}
Benefits:
-
Type safety restored:
# Before: Runtime errors def critic(state: CriticInput): components = state["components"] # KeyError # After: Caught at type-check time def critic(state: AgentState): components = state["planned_components"] # ✅ MyPy validates this -
Checkpoint size reduced by 70%:
// Before: 500 KB { "state": { // 15 schema copies of same data } } // After: 150 KB { "state": { "user_requirements": "...", "extracted_constraints": {...}, "architecture_plan": "...", // ... single copy of all fields } } -
Simplified routing:
# Before: Complex type conversions def route_after_planner(state: PlannerOutput) -> str: critic_state = convert_to_critic_input(state) # Custom function return "critic" # After: Direct access def route_after_planner(state: AgentState) -> str: if state["plan_confidence"] < 0.75: return "hitl_gate" return "critic" -
Better debugging:
# View entire workflow state in one place from langgraph.checkpoint.postgres import PostgresSaver checkpointer = PostgresSaver.from_conn_string(DATABASE_URL) checkpoint = checkpointer.get(thread_id="job-123") # Single AgentState object with all fields print(checkpoint["state"]["current_agent"]) # "feasibility_critic" print(checkpoint["state"]["plan_confidence"]) # 0.87
Migration Strategy:
# Step 1: Define consolidated schema (above)
# Step 2: Update agents incrementally (backwards compatible)
def old_agent(state: Union[OldSchema, AgentState]) -> AgentState:
# Handle both old and new schemas during migration
if "extracted_constraints" in state:
constraints = state["extracted_constraints"] # New schema
else:
constraints = state["constraints"] # Old schema
# ... agent logic
return AgentState(...) # Always return new schema
# Step 3: Update graph builder
graph = StateGraph(AgentState) # Use consolidated schema
graph.add_node("extractor", constraint_extractor)
graph.add_node("planner", planner)
# ... etc
Lessons Learned:
- Start with consolidated schema: Easier to add fields than merge schemas later
- Use Annotated for reducers:
Annotated[list[Message], add_messages]for automatic list merging - Partial updates are OK: Agents return subset of fields, LangGraph merges with existing state
- Type hints = documentation:
AgentStateserves as single source of truth for workflow data model
References:
- LangGraph State Management: https://langchain-ai.github.io/langgraph/concepts/low_level/#state
- Python TypedDict: https://peps.python.org/pep-0589/
- Pydantic vs TypedDict: https://docs.pydantic.dev/latest/concepts/types/#typeddict
Challenge 4: HITL Gate with Auto-Approval Timeout
The Problem: Human-in-the-Loop (HITL) gates were blocking workflows indefinitely when:
- User went offline after submitting job (e.g., closed browser tab)
- Non-critical decisions didn't require human approval (e.g., minor optimization suggestions)
- Mobile users backgrounded the app during long-running workflows
Initial Implementation (Blocking Forever):
def should_interrupt(state: AgentState) -> str:
if state["plan_confidence"] < 0.75:
return "hitl_gate" # Blocks workflow until user approves
return "critics"
graph.add_node("hitl_gate", human_approval_node)
graph.add_conditional_edges(
"planner",
should_interrupt,
{"hitl_gate": "hitl_gate", "critics": "critics"}
)
# Workflow stuck here until API receives approval
def human_approval_node(state: AgentState) -> AgentState:
# LangGraph interrupt() called
# Waits indefinitely for external command
pass
Real-World Failure:
# User submits job, gets low confidence plan
POST /api/submit
{"requirements": "Design MLOps system with GPU support"}
# Workflow interrupts for approval
SSE Event: {"type": "hitl_required", "reason": "Low confidence: 0.68"}
# User closes browser tab
# 3 hours later... job still stuck in "processing" state
# Database checkpoint shows: state="hitl_gate", status="interrupted"
Solution: Auto-Approval Timeout with Context-Aware Defaults
from datetime import datetime, timedelta
import asyncio
class AgentState(TypedDict):
# ... existing fields
hitl_timeout_seconds: int # Configurable timeout
hitl_triggered_at: datetime | None
hitl_reason: str | None
auto_approved: bool
def human_approval_node(state: AgentState) -> AgentState:
"""
Interrupt workflow and wait for user approval.
Auto-approve after timeout if no response.
"""
timeout = state.get("hitl_timeout_seconds", 300) # Default: 5 minutes
return {
"hitl_triggered_at": datetime.utcnow(),
"hitl_reason": f"Low confidence: {state['plan_confidence']:.2f}",
"workflow_status": "hitl_required",
"auto_approved": False
}
# Separate background task monitors timeouts
async def monitor_hitl_timeouts():
"""
Background worker that auto-approves timed-out HITL gates.
Runs every 30 seconds.
"""
while True:
await asyncio.sleep(30)
# Find jobs stuck in HITL
jobs = await db.execute(text("""
SELECT id, thread_id, hitl_triggered_at, hitl_timeout_seconds
FROM jobs
WHERE workflow_status = 'hitl_required'
AND hitl_triggered_at IS NOT NULL
"""))
for job in jobs:
elapsed = (datetime.utcnow() - job.hitl_triggered_at).total_seconds()
if elapsed >= job.hitl_timeout_seconds:
# Auto-approve
await send_command(
thread_id=job.thread_id,
command={
"type": "resume",
"approval": "auto_approved",
"reason": f"Timeout after {job.hitl_timeout_seconds}s"
}
)
# Update job
await db.execute(text("""
UPDATE jobs
SET auto_approved = true,
workflow_status = 'running'
WHERE id = :id
"""), {"id": job.id})
# Emit SSE event to frontend
await emit_event(job.id, {
"type": "hitl_auto_approved",
"reason": "No response after 5 minutes"
})
# User can still manually approve before timeout
@app.post("/api/jobs/{job_id}/approve")
async def approve_job(job_id: str, approval: dict):
job = await get_job(job_id)
if job.workflow_status != "hitl_required":
raise HTTPException(400, "Job not waiting for approval")
# Send resume command to LangGraph
await send_command(
thread_id=job.thread_id,
command={
"type": "resume",
"approval": approval["decision"], # "approve" or "reject"
"feedback": approval.get("feedback")
}
)
return {"status": "resumed"}
Context-Aware Timeout Defaults:
def calculate_hitl_timeout(state: AgentState) -> int:
"""
Adjust timeout based on context.
Critical decisions get longer timeout.
"""
reason = state["hitl_reason"]
# Critical: Security/compliance issues
if "security" in reason.lower() or "compliance" in reason.lower():
return 3600 # 1 hour
# Important: High-cost resources
if "cost" in reason.lower() and state["plan_confidence"] < 0.5:
return 1800 # 30 minutes
# Non-critical: Minor optimizations
if "optimization" in reason.lower():
return 180 # 3 minutes
# Default
return 300 # 5 minutes
Frontend Integration:
// Show countdown timer in UI
function HITLApprovalCard({ job }: { job: Job }) {
const [timeLeft, setTimeLeft] = useState(job.hitl_timeout_seconds);
useEffect(() => {
const interval = setInterval(() => {
const elapsed = (Date.now() - job.hitl_triggered_at.getTime()) / 1000;
const remaining = job.hitl_timeout_seconds - elapsed;
setTimeLeft(Math.max(0, remaining));
}, 1000);
return () => clearInterval(interval);
}, [job]);
return (
<div className="border-yellow-500 bg-yellow-50 p-4">
<h3>⚠️ Approval Required</h3>
<p>{job.hitl_reason}</p>
<div className="mt-4">
<p className="text-sm text-gray-600">
Auto-approving in {Math.floor(timeLeft / 60)}:{(timeLeft % 60).toString().padStart(2, '0')}
</p>
<ProgressBar value={(timeLeft / job.hitl_timeout_seconds) * 100} />
</div>
<div className="mt-4 flex gap-2">
<button onClick={() => approveJob(job.id, "approve")}>
✅ Approve Plan
</button>
<button onClick={() => approveJob(job.id, "reject")}>
❌ Reject & Revise
</button>
</div>
</div>
);
}
Impact:
- No stuck workflows: Jobs complete reliably through either user approval or auto-approval after timeout
- Improved UX: Users see countdown timer and understand the auto-approval mechanism
- Configurable per job: Critical jobs get longer timeout periods
- Audit trail:
auto_approvedflag in database tracks automatic approvals
Edge Cases Handled:
-
User approves after timeout:
# Check if already auto-approved if job.auto_approved: return {"message": "Job already auto-approved and resumed"} -
Multiple HITL gates in same workflow:
# Each HITL gate has its own timeout # State tracks current HITL gate: "hitl_stage": "planner_approval" -
Workflow crashes during HITL:
# On restart, check if HITL timed out if elapsed >= timeout: await send_command(thread_id, {"type": "resume", "approval": "auto_approved"})
Lessons Learned:
- Timeouts prevent deadlocks: Every blocking operation needs a timeout
- Context matters: Security approvals need longer timeout than UX tweaks
- Transparency builds trust: Show countdown timer in UI
- Background workers for monitoring: Don't block main request handler
References:
- LangGraph Interrupt/Resume: https://langchain-ai.github.io/langgraph/how-tos/human-in-the-loop/
- Asyncio Timeouts: https://docs.python.org/3/library/asyncio-task.html#timeouts
Impact & Scale
Automation Benefits
The platform transforms traditional multi-week MLOps design processes into automated workflows:
- Requirements Analysis: AI-powered constraint extraction processes natural language requirements in minutes instead of days of manual review
- Architecture Design: Multi-agent collaborative design replaces weeks of architect time with automated planning and validation
- Code Generation: Automated repository generation eliminates weeks of manual development
- Compliance Validation: Policy agents provide instant validation against custom rules
Result: Complete, production-ready MLOps systems generated in under an hour instead of 8-12 weeks of traditional development.
System Capabilities
The multi-agent platform provides:
- Automated Validation: Built-in feasibility, policy, and optimization critics validate designs before code generation
- Code Quality: Generated code follows best practices with linting, testing, and security configurations
- Policy Compliance: Automated validation against custom security, cost, and governance rules
- Confidence Scoring: Agents self-assess reliability and trigger human review for uncertain decisions
- Human-in-the-Loop: Optional approval gates for critical decisions with configurable timeouts
Code Generation Capabilities
Infrastructure Generated:
- ✅ Terraform modules (AWS: ECS, Lambda, RDS, S3, VPC, CloudWatch)
- ✅ Kubernetes manifests (Deployments, Services, Ingress, HPA)
- ✅ Docker configurations (multi-stage builds, security scanning)
Application Code:
- ✅ FastAPI backends (REST APIs, WebSocket, background tasks)
- ✅ Next.js frontends (App Router, Server Components, Tailwind)
- ✅ ML model serving (TensorFlow Serving, PyTorch Serve, custom inference)
- ✅ Data pipelines (Airflow DAGs, Prefect flows, dbt models)
CI/CD Pipelines:
- ✅ GitHub Actions workflows (test, build, deploy, security scans)
- ✅ GitLab CI pipelines (multi-stage, parallel jobs, artifacts)
- ✅ Deployment scripts (blue-green, canary, rollback strategies)
Monitoring & Observability:
- ✅ CloudWatch dashboards (custom metrics, alarms)
- ✅ Prometheus + Grafana (scrape configs, recording rules, alerts)
- ✅ Distributed tracing (Jaeger, Zipkin, OpenTelemetry)
- ✅ Structured logging (JSON format, correlation IDs)
Estimated Cost Model
Per-Workflow Costs (Estimated):
- LLM API Usage: ~$2-3 per workflow
- OpenAI GPT-4/5 for planning and critics
- OpenAI or Claude for code generation (configurable)
- Infrastructure: Negligible per workflow (amortized across monthly infrastructure costs)
Infrastructure Costs:
- Monthly Fixed: ~$200-300 for AWS infrastructure (App Runner, RDS, S3)
- Variable: LLM API costs based on usage
Value Proposition: Traditional MLOps system design typically requires weeks of architect and developer time. This platform automates the entire workflow, reducing both time and resource requirements significantly.
Compliance & Governance
Policy Validation:
- ✅ PCI DSS compliance (encryption, audit logging, access controls)
- ✅ HIPAA compliance (data encryption, access logs, BAA-compliant services)
- ✅ GDPR compliance (data residency, right to deletion, consent management)
- ✅ SOC 2 Type II (security controls, audit trails, incident response)
- ✅ Cost optimization (budget constraints, resource tagging, auto-shutdown)
Automated Checks:
- ✅ Security scanning (Terraform linting with
tfsec, container scanning with Trivy) - ✅ Cost estimation (Terraform cost with Infracost, AWS Pricing API)
- ✅ Performance validation (load testing with Locust, database query analysis)
- ✅ Accessibility (WCAG 2.1 AA compliance for generated UIs)
Deployment & Infrastructure
AWS App Runner Deployment:
- Scalability: Auto-scales from 1 to 25 instances based on load
- Infrastructure: PostgreSQL (RDS) for state persistence, S3 for artifact storage
- Estimated Monthly Cost: ~$200-300 (App Runner, RDS, S3, excluding LLM API usage)
Typical Workflow Timeline:
- Constraint Extraction: ~10 seconds
- Architecture Planning: ~30-45 seconds
- Design Validation: ~45 seconds (3 critic agents)
- Code Generation: ~90-120 seconds
- End-to-End: Typically completes in 3-5 minutes