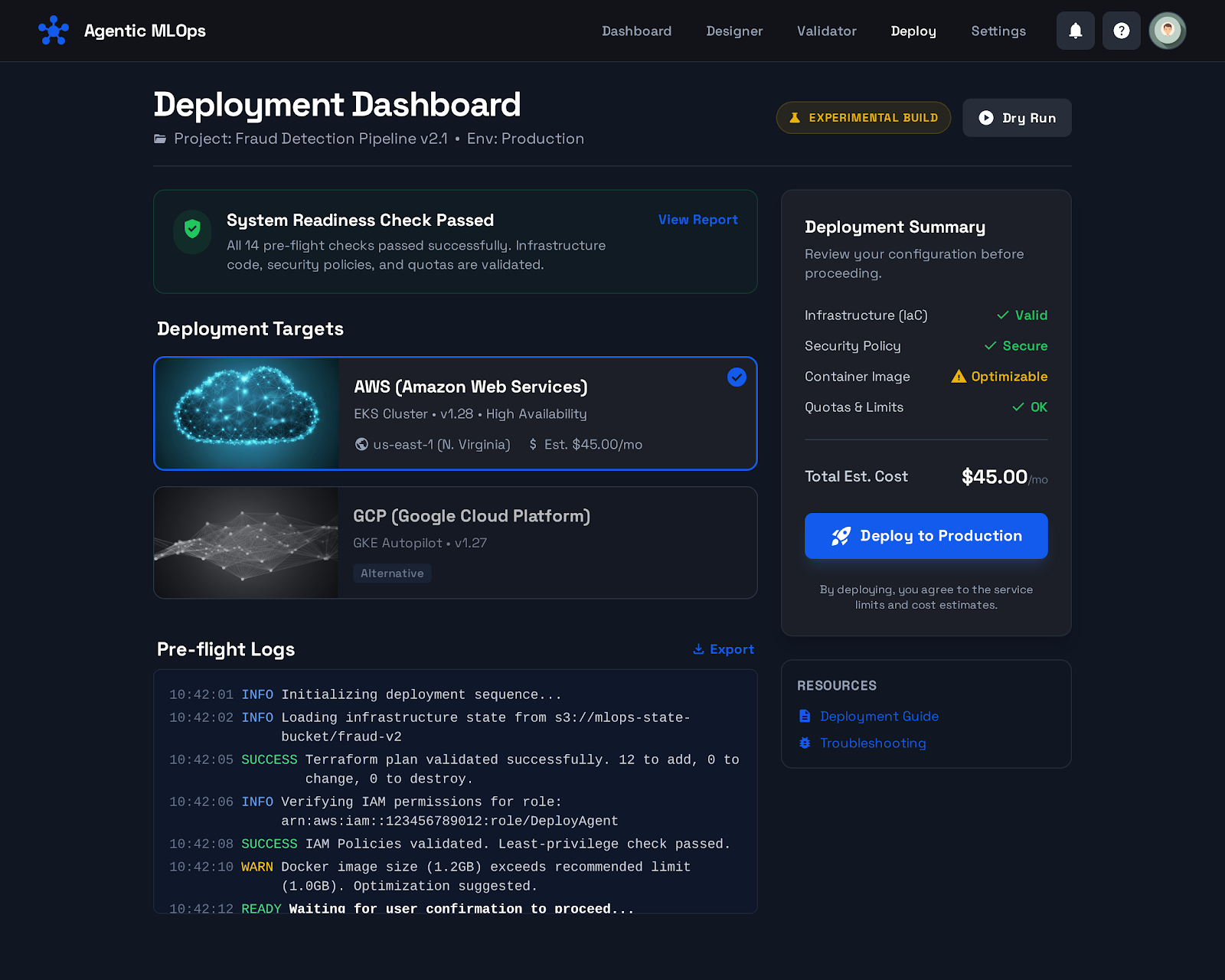
Agentic MLOps — End-to-End Agentic MLOps Platform for Practitioners
Positioning “An AI-native MLOps operating system that designs, validates, and generates production-ready ML infrastructure — from natural language requirements to deployable code — with built-in governance, evals, and continuous improvement via Agentic RL.”
1) Executive snapshot
ICP Senior MLOps Engineers, ML Platform teams, AI Infrastructure Leads, CTOs
Primary Job-to-be-Done
“Design, validate, and ship a production-grade MLOps system that satisfies performance, security, cost, and compliance constraints — without weeks of architecture churn.”
Wedge workflow Natural-language → constraint extraction → multi-agent architecture design → critique & validation → code + IaC generation → deployable repo.
Why an agentic system (not templates or scaffolds)
- MLOps is constraint-heavy and long-horizon
- Tradeoffs emerge only after several decisions (compute ↔ latency ↔ cost ↔ compliance)
- Requires planning, critique, iteration, and HITL — not one-shot generation
Autonomy level Supervised Autopilot
- Agents propose architectures and code
- Humans approve high-impact decisions (infra, security, cost)
North-star KPIs
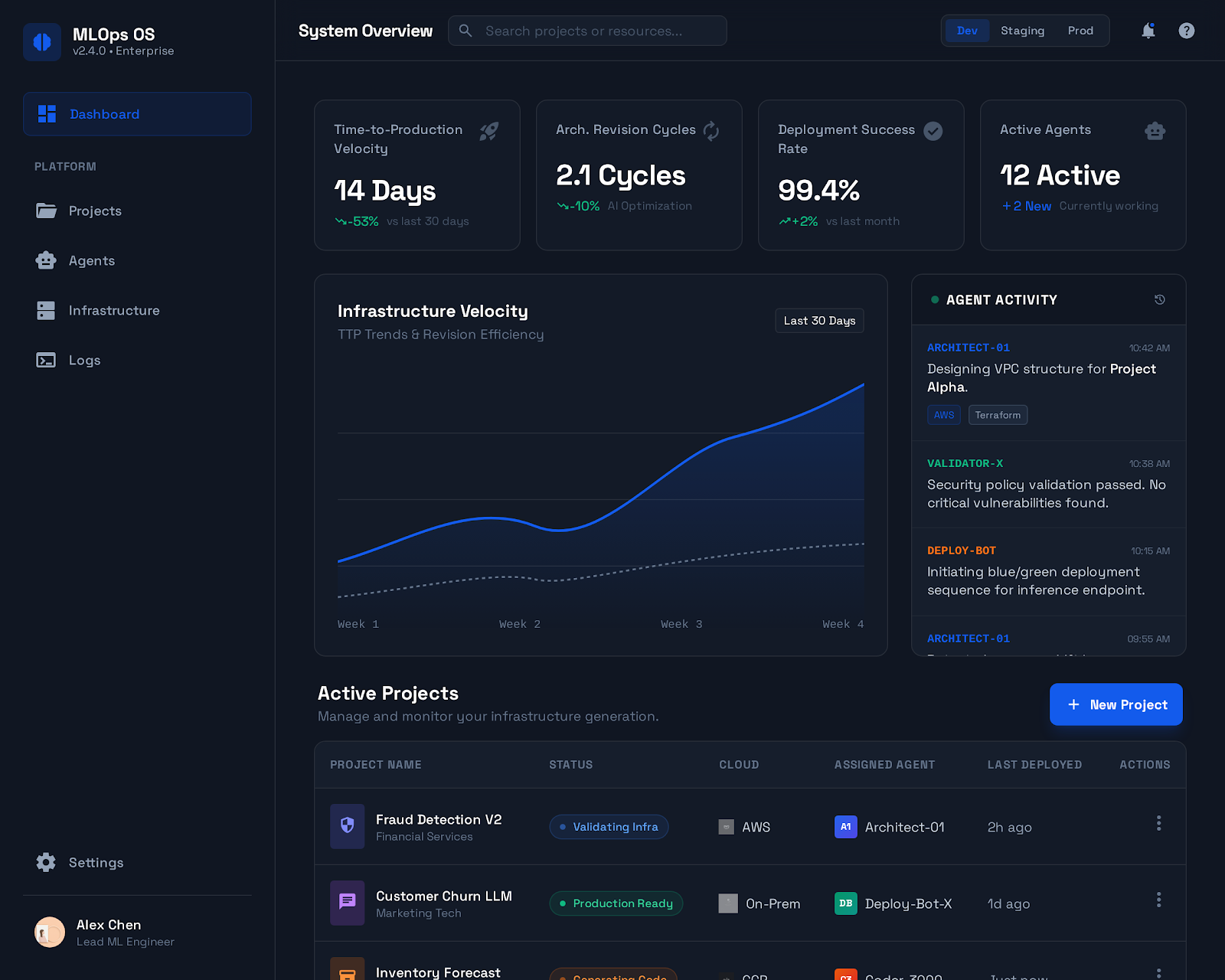
- Time-to-production architecture (weeks → < 1 hour)
- Architecture revision cycles
- % of generated repos deployable without manual fixes
- Cost per successfully deployed system
2) Product experience & UX
Core UX paradigm
“Watch expert MLOps architects collaborate in real time.”
Primary surfaces
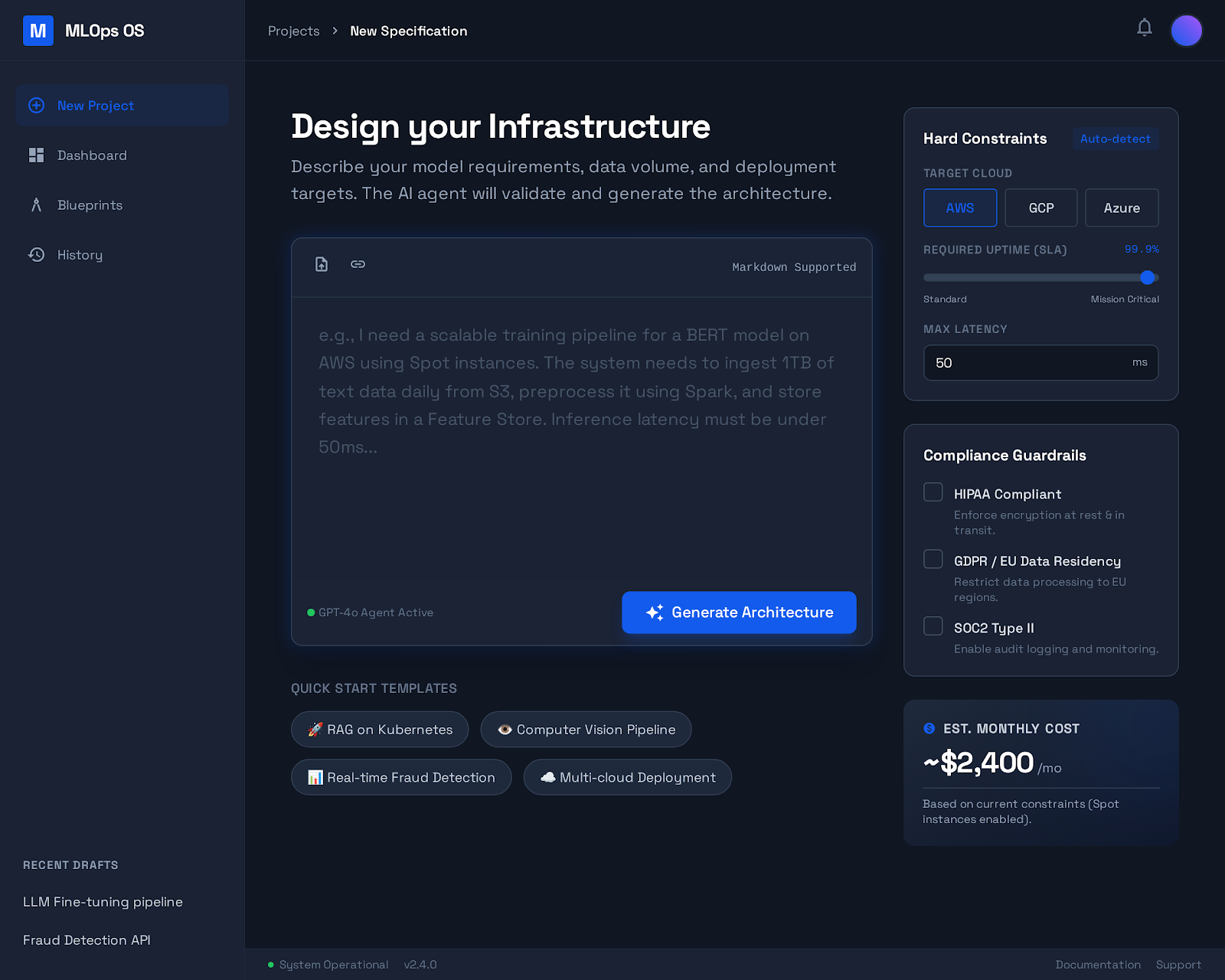
- Natural language input panel (requirements, constraints, SLAs)
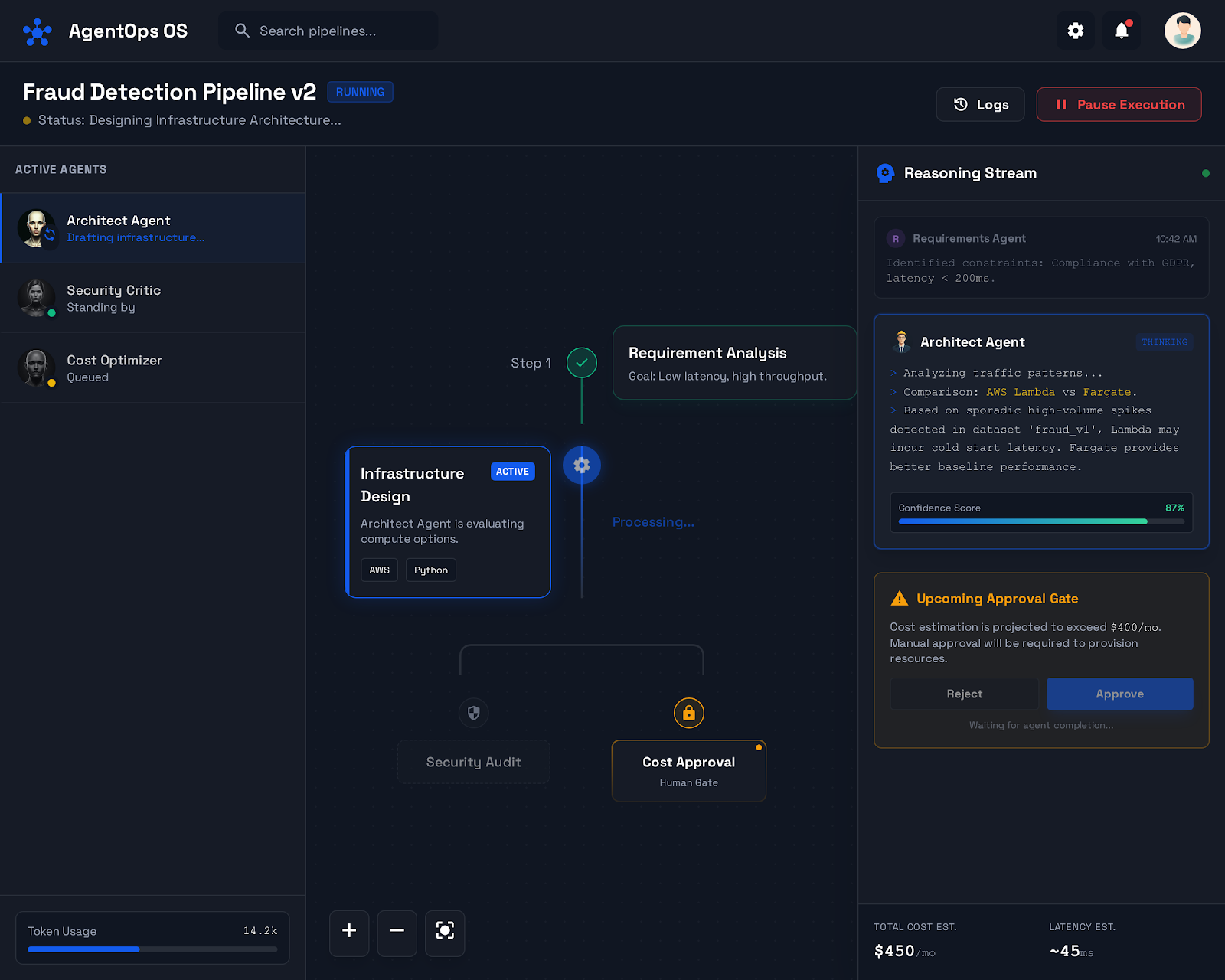
- Streaming agent reasoning cards (Planner, Critics, Policy Agent)
- Confidence & risk indicators
- Approval gates (HITL with auto-timeouts)
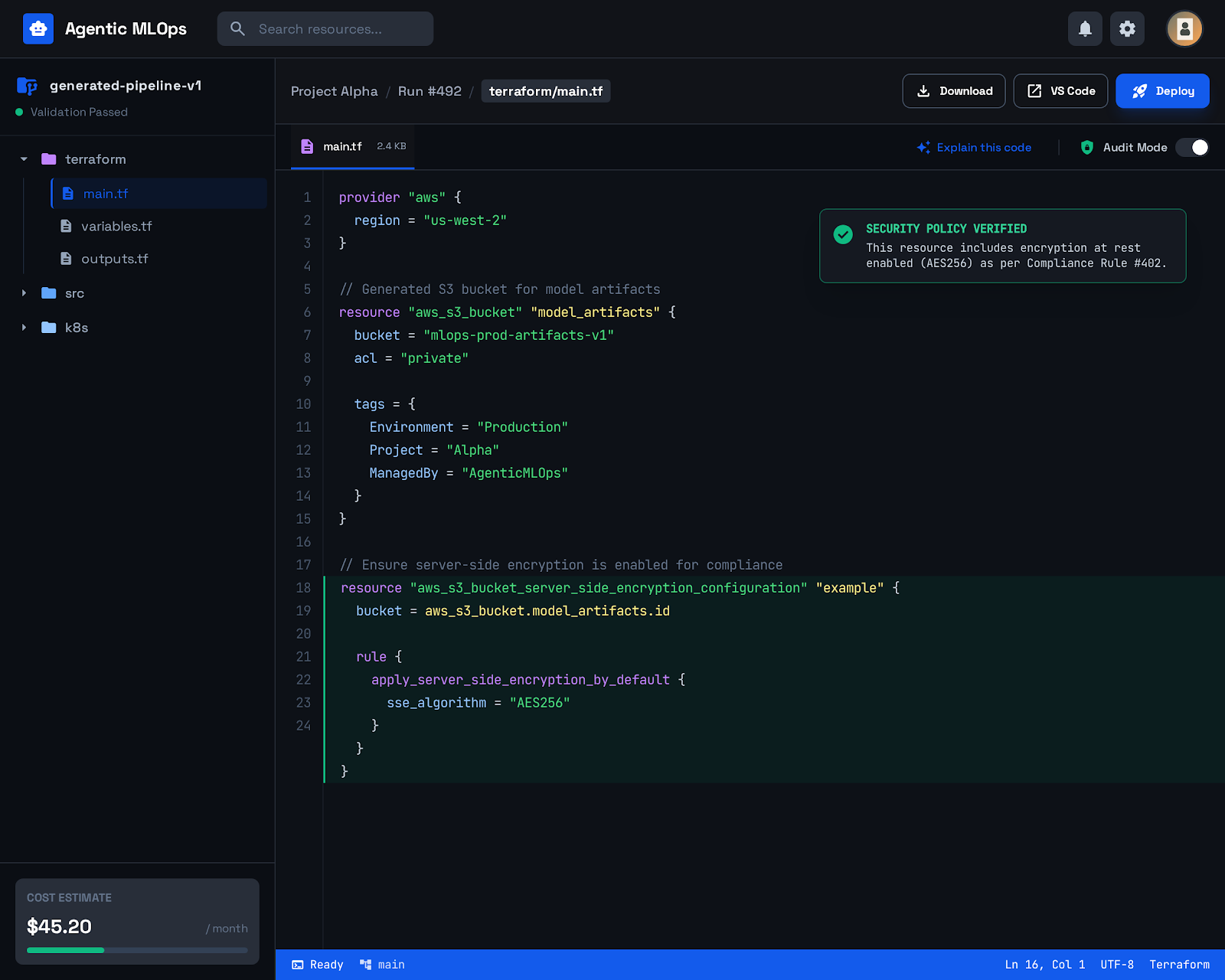
- Generated repo explorer
- One-click deploy instructions
UX principles
- Transparency over magic (reasoning visible)
- Interruptible automation
- Auditability by default
- Production realism (no toy demos)
3) Agent design map
Skills (domain expertise)
- MLOps Architect (system design)
- Cloud Infrastructure Specialist (AWS/GCP/Azure)
- Security & Compliance Reviewer (PCI, HIPAA, SOC2)
- Cost Optimizer
- Platform Reliability Engineer
Subagents (executors)
- Constraint Extractor → parses NL into structured requirements
- Planner Agent → proposes full MLOps architecture
- Feasibility Critic → detects bottlenecks, anti-patterns
- Policy Critic → validates security, compliance, governance
- Optimization Critic → cost/performance tradeoffs
- Code Generator → Terraform + app + CI/CD (Claude Code)
Planner / Orchestrator
- LangGraph-based state machine
- Confidence-based routing
- HITL interrupts with resume semantics
- Checkpointed execution (replayable)
4) Tool & data plane (MCP-centric)
MCP integrations
- Cloud APIs (AWS/GCP)
- Pricing & quota data
- Security policy documents
- Infrastructure templates
- Code generation toolchains
Key design choice
Tools are constrained, typed, auditable, and budget-bounded — critical for safe infra automation.
5) Context engineering plan
Pinned context
- Requirements
- Non-negotiable constraints
- Compliance policies
- Organizational standards
Just-in-time context
- Service-specific best practices
- Tradeoff alternatives
- Prior agent critiques
Compaction
- Decision logs replace raw conversations
- Architecture snapshots, not token history
Isolation
- Critics only see relevant slices (prevents prompt injection + drift)
6) Evals & observability
Offline evals
- Architecture correctness checks
- Policy compliance suites
- Cost estimation accuracy
- IaC validation (terraform plan, lint)
Online metrics
- Human approval rate
- Auto-approval rate
- Revision loops per job
- Deployment success rate
- Cost per workflow
Tracing
- Full agent trajectories
- Tool calls
- Checkpoint diffs
- Confidence evolution
7) Failure modes & mitigations
| What breaks | Detect | Constrain | Prevent regression |
|---|---|---|---|
| Over-confident bad architecture | Low confidence + critic disagreement | HITL gate | Add failed case to eval suite |
| Policy violations | Policy critic + static checks | Block generation | Regression policy tests |
| Tool misuse (dangerous infra) | Tool audits | Read-only / dry-run first | Contract tests |
| Architecture drift over time | Replay deltas | Version pinning | Continuous eval replay |
8) Governance posture & rollout
- Permissions: least-privilege MCP tools
- Approvals: infra writes gated
- Audit trails: immutable logs + artifact hashes
- Rollout: shadow → canary → gated GA
- Kill switches: per-capability (deploy, delete, scale)
This mirrors real enterprise change-management expectations, not demo-ware.
9) Business case & distribution
ROI
- Architect time saved (weeks → minutes)
- Reduced infra mistakes
- Faster experimentation
- Standardization across teams
Pricing model
- Per workflow (design)
- Per seat (platform)
- Enterprise governance tier
Distribution loops
- Generated repos shared internally
- Platform embeds into CI/CD
- Organization-level standards encoded
Why Agentic RL is especially powerful for MLOps
MLOps workflows are:
- Long-horizon
- Multi-step
- Constraint-driven
- Outcome-verifiable
This makes them ideal for Agentic RL / RFT
What Agentic RL optimizes (beyond prompts)
Instead of tuning text style, Agentic RL tunes the policy:
- When to ask clarifying questions
- Which architecture to propose first
- How aggressively to optimize cost vs latency
- Which tools to invoke (and in what order)
- When to escalate to human approval
This aligns perfectly with OpenAI’s Reinforcement Fine-Tuning (RFT) workflow:
- Log trajectories
- Grade outcomes
- Optimize end-to-end behavior, not just answers
Agentic RL training loop for MLOps
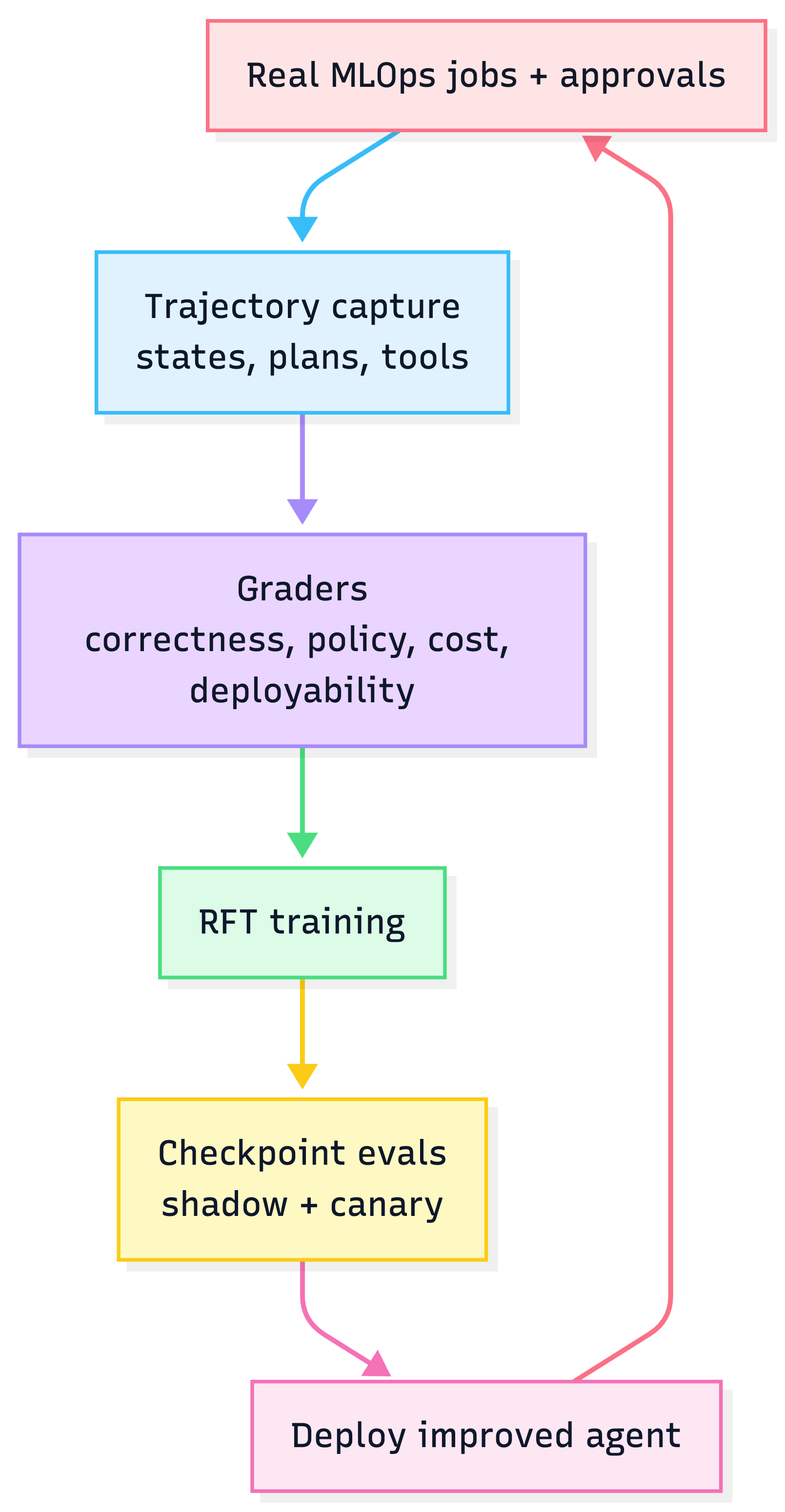
What you train on (signals)
Trajectories
- Requirements → architecture → critiques → revisions → final repo
Graders
- Architecture correctness
- Policy compliance
- Cost efficiency
- Human approval outcome
- Deployment success
Anti-gaming
- Multi-grader stacks
- Holdout evals
- Adversarial cases
Measurable business lift from Agentic RL
| Metric | Before RFT | After RFT (Expected) |
|---|---|---|
| Human revisions | High | ↓ 30–50% |
| Approval rate | ~85% | ↑ 95%+ |
| First-try deployability | ~70% | ↑ 90%+ |
| Tool cost per workflow | Variable | ↓ 20–30% |
| Trust / adoption | Moderate | High |
Key insight
Agentic RL turns the platform from “smart generator” into a learning MLOps architect that improves with every real deployment.