Evaluation of AI Agents — Ultimate One‑Stop Guide
A CTO/Tech‑Lead playbook for evaluating agent behavior over time, not just answer quality.
Table of Contents
- 1. The core mental model
- 2. Definitions (use consistently)
- 3. First fork: Agent vs Agentic System
- 4. The universal 6‑dimension scorecard
- 5. Graders: deterministic vs model‑based vs human
- 6. Capability evals vs Regression evals
- 7. Handling non‑determinism: pass@k vs pass^k
- 8. What to measure (ship‑ready metrics)
- 9. Eval suite composition (version‑controlled)
- 10. 3‑tier evaluation pipeline (CI → staging → prod)
- 11. Instrumentation: log full traces
- 12. Roadmap: zero → evals you can trust (8 steps)
- 13. Common agent types: evaluation patterns
- 14. CI gating rules (default policy)
- 15. Failure → test case flywheel
- 16. Dashboards leaders should see weekly
- 17. High‑stakes agents: evaluate runaway‑capability risks
- 18. Mermaid diagrams (copy/paste)
- 19. Decision tables & checklists
- 20. Starter kit repo layout + templates
- Appendix A: Template schemas
- Appendix B: Example task YAMLs
1. The core mental model
Evaluating agents ≠ evaluating answers. It’s evaluating behavior over time.
Agents are non‑deterministic, act in multi‑step loops, modify state, and errors compound. In multi‑agent systems, failures can be emergent (loops, deadlocks, misalignment).
Your target is always:
Outcome quality + Trajectory quality + Safety + Cost (and for multi‑agent: Collaboration).
“State‑based” → “Path‑based” testing shift
Traditional tests check final output. Agents can reach the right outcome via a bad path (loops, unsafe actions, wasteful tool calls).
So: trajectory evaluation + observability becomes first‑class.
2. Definitions (use consistently)
- Task / problem / test case: one test with defined inputs + success criteria
- Trial: one attempt at a task (run multiple due to stochasticity)
- Grader: scoring logic; can have multiple assertions/checks
- Transcript / trace / trajectory: complete record of the trial (tool calls, intermediate steps, etc.)
- Outcome: final environment state (not just what the agent “said”)
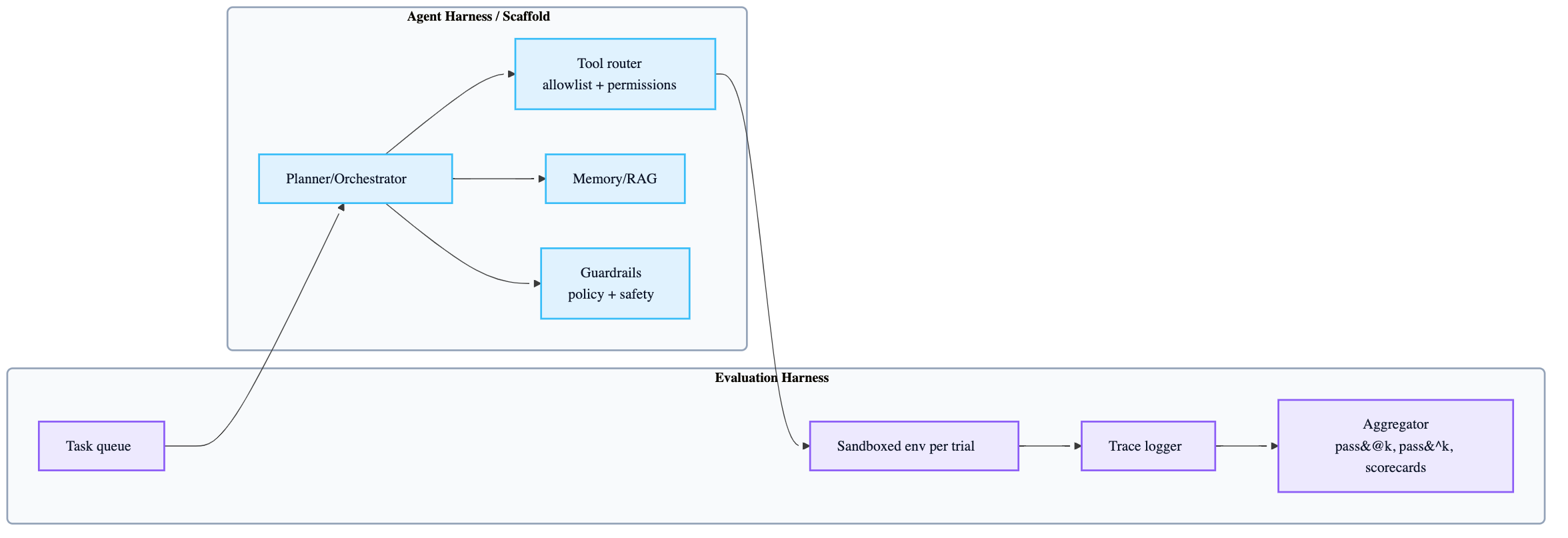
- Evaluation harness: infra that runs tasks, records traces, grades, aggregates
- Agent harness / scaffold: the system that enables a model to act as an agent (orchestrates tool calls)
- Evaluation suite: collection of tasks measuring specific capabilities/behaviors
When you “eval an agent,” you’re evaluating model + harness together.
3. First fork: Agent vs Agentic System
If you don’t name this, you’ll pick the wrong metrics.
| Dimension | AI Agent | Agentic System (multi‑agent) |
|---|---|---|
| Architecture | Single worker around an LLM | Orchestrated team of specialized agents |
| Typical failures | Tool errors, prompt brittleness, hallucinations | Coordination failures, emergent loops, goal misalignment |
| Eval focus | Tool‑use correctness, step efficiency, guardrails | Protocols, handoffs, deadlocks, shared memory, system safety |
Heuristic: If the system can delegate / negotiate / re‑plan across agents, treat it like a distributed system and evaluate integration contracts (schemas, protocols, handoff completeness), not just outputs.
4. The universal 6‑dimension scorecard
Use this rubric for both single‑agent and multi‑agent systems.
- Task success + output quality (correct, coherent, useful; faithfulness)
- Trajectory quality (good tool choices, logical steps, no detours/loops)
- Collaboration quality (multi‑agent) (coordination, no duplicate work, compatible formats)
- Efficiency (latency, tokens, tool calls, compute; cost/accuracy tradeoffs)
- Robustness (handles tool outages, malformed inputs, contradictory instructions; stops loops)
- Safety & alignment (policy adherence, bias/fairness, prompt injection resistance)
Ready‑to‑use 0–4 rubric + weights
| Dimension | Weight | What you measure | Evidence |
|---|---|---|---|
| Task success & quality | 30% | goal achieved; correctness/faithfulness/relevance | success rate + correctness/faithfulness |
| Trajectory quality | 20% | action sequence quality; avoids loops | trajectory match + action precision/recall |
| Robustness | 15% | handles outages/malformed/contradictions; stops loops | loop avoidance + graceful failure |
| Safety & policy | 20% | policy adherence, injection resistance, bias/fairness | policy adherence + injection vuln rate |
| Efficiency & cost | 15% | latency + token/tool cost per task | latency + tokens + tool calls |
| Collaboration (multi‑agent only) | +10% optional | coordination + protocol compatibility | coordination metrics |
Score anchors (0–4)
- 4: correct + safe + efficient; no critical trajectory issues
- 3: correct; minor inefficiency / wording issues
- 2: partially correct; needs correction / non‑trivial inefficiency
- 1: wrong outcome or unsafe avoided only by luck; major process issues
- 0: unsafe policy violation OR fails OR stuck/loops
5. Graders: deterministic vs model‑based vs human
Agent evals typically combine code‑based, model‑based, and human graders.
5.1 Deterministic graders (code‑based)
Methods: string match, unit tests, static analysis, outcome verification, tool‑call verification, transcript metrics.
Strengths: fast, cheap, objective, reproducible, debuggable.
Weaknesses: brittle to valid variation; limited nuance.
5.2 Model‑based graders (LLM‑as‑judge)
Methods: rubric scoring, natural language assertions, pairwise comparison, reference‑based, multi‑judge consensus.
Strengths: flexible, nuanced, scalable.
Weaknesses: non‑deterministic, more expensive, needs calibration.
5.3 Human graders
SME review, crowdsourcing, spot‑checks, inter‑annotator agreement.
Gold standard, but slow/expensive; use to calibrate and for high‑stakes.
Combining graders (decision rule)
- Binary gate: all critical graders must pass (common for safety + regressions).
- Weighted score: combine dimensions into a threshold (common for capability hill‑climbing).
- Hybrid: strict safety + regression gates; weighted capability score.
Key insight: avoid rigid grading of “exact tool‑call order.” It’s brittle—prefer grading outcome unless the path itself is the requirement.
6. Capability evals vs Regression evals
- Capability/quality evals: “What can this agent do well?”
- Start with low pass rate (a hill to climb).
- Regression evals: “Does the agent still handle what it used to?”
- Target near 100% pass; backsliding means something broke.
Lifecycle move: capability tasks that reach high reliability graduate into regression suites run continuously.
7. Handling non‑determinism: pass@k vs pass^k
- pass@k: probability of at least one success in k trials
- Good when “one successful attempt is enough.”
- pass^k: probability that all k trials succeed
- Good when you need reliability/consistency every time.
If per‑trial success is 0.75 and k=3, then pass^k = 0.75³ ≈ 0.42.
Decision heuristic
- Use pass@1 when first‑try success matters.
- Use pass^k when user‑facing reliability matters.
8. What to measure (ship‑ready metrics)
Outcome metrics
- Task completion / success rate
- Correctness + faithfulness (groundedness proxy)
- End‑state verification (DB entries, files created, actions performed)
Trajectory metrics
- Trajectory in‑order match (when ideal steps are known)
- Action precision/recall (did necessary steps without junk?)
- Path errors: loops, redundant calls, router‑bouncing, retries‑without‑learning
- Step/tool budgets, retry counts
Efficiency metrics
- tokens in/out per step + total
- latency per step + total; p50/p95
- tool call count; tool error rate
- cost per task
Safety metrics
- policy adherence rate
- prompt injection vulnerability success rate
- permission boundary violations
9. Eval suite composition (version‑controlled)
Required layout:
evals/golden/deterministic tasks with expected outcomesevals/open_ended/rubric‑scored tasks (no single right answer)evals/adversarial/injection + tool‑failure + contradictory instructionsevals/failure_replays/production incidents turned into tests
Balance your dataset: include “should do” and “should not do” cases to prevent over‑triggering.
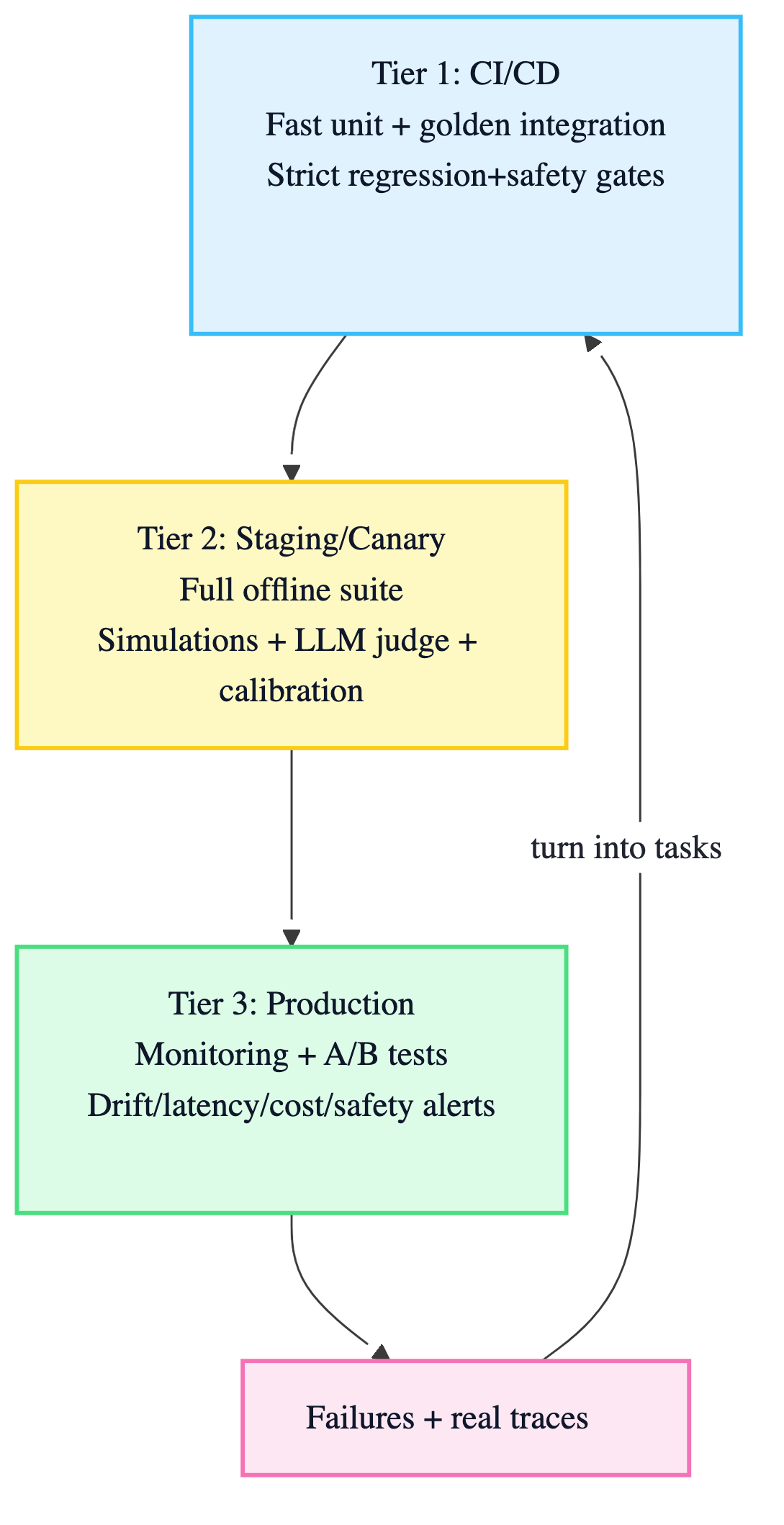
10. 3‑tier evaluation pipeline (CI → staging → prod)
Tier 1 — CI/CD (every PR)
- fast unit + integration tests
- strict regression gate on golden set
- strict safety gate
- bounded latency/cost regressions
Tier 2 — Staging/Canary (release candidate)
- full offline suite: golden + adversarial + open‑ended
- LLM‑as‑judge on subjective dimensions, with periodic human calibration
- realistic sandbox environments; simulate users where applicable
Tier 3 — Production
- A/B testing for major changes + business KPI validation
- continuous monitoring: traces, latency, tool errors, cost overruns, drift
11. Instrumentation: log full traces
Minimum trace schema (per run):
- run_id, agent_version, model_id, prompt_hash, tool_allowlist_hash
- steps[]: (timestamp, tool_name, tool_args, tool_result_status, retries)
- tokens_in/out, latency_ms (per step + total), tool_call_count
- outcome: success(bool), final_state (when applicable), safety_flags
Without traces you can’t debug graders, can’t detect loops/cost drift, and you’ll fly blind.
12. Roadmap: zero → evals you can trust (8 steps)
Step 0 — Start early
20–50 real tasks from failures is enough early.
Step 1 — Start with what you already test manually
Convert release checklists + common user tasks into tasks.
Step 2 — Write unambiguous tasks + reference solutions
Two experts should independently agree pass/fail. Create a reference solution.
Step 3 — Build balanced problem sets
Include “should do” and “should not do”.
Step 4 — Build robust harness + isolated environments
Each trial starts clean; avoid shared state and infra flakiness.
Step 5 — Design graders thoughtfully
Deterministic where possible; LLM where necessary; bypass‑resistant; partial credit if needed.
Step 6 — Read transcripts
Confirm failures are fair and the eval measures what matters.
Step 7 — Watch for eval saturation
A 100% suite becomes regression‑only; build harder tasks to keep capability signal.
Step 8 — Keep suites healthy via ownership + contribution
Dedicated infra owners + domain experts contribute tasks. Practice eval‑driven development.
13. Common agent types: evaluation patterns
Coding agents
Deterministic tests (do tests pass?) + tool‑use + quality rubrics.
Conversational agents
Outcome (issue resolved) + trajectory constraints + tone/quality rubric; simulate user personas.
Research agents
Groundedness + coverage + source quality + calibrated rubrics.
GUI / browser agents
Sandbox + verify outcome via page state/URL/backend checks; evaluate tool selection strategy.
14. CI gating rules (default policy)
Gate A — PR merge gate
- No regression on golden success rate (strict)
- No new safety violations (strict)
- Latency/cost regressions bounded by budgets
Gate B — Nightly / main
- Full offline suite: golden + adversarial + open‑ended
- Open‑ended judged with LLM rubric + periodic human calibration
Gate C — Release candidate
- realistic env; functional correctness where possible
- human acceptance for critical UX/safety
Gate D — Production rollout
- A/B testing major changes; require KPI + guardrail validation
- continuous monitoring + anomaly alerts
15. Failure → test case flywheel
Every Sev‑2+ incident yields:
- reproduction trace
- minimal failing test case
- new regression test in
evals/failure_replays/
16. Dashboards leaders should see weekly
- Success / task completion
- Correctness & faithfulness (groundedness)
- Trajectory health: precision/recall + loop rate + path errors
- Latency p50/p95 + cost per task
- Safety: policy adherence + injection vulnerability rate
Alerts: spikes in latency/tool errors/cost; drift (steps/loops rising).
17. High‑stakes agents: evaluate runaway‑capability risks
If the agent can spend money, run code, or act broadly:
- sandbox permissions + dummy accounts
- adversarial evals for escalation/replication/acquisition patterns
- strict allowlists + budgets + human approval boundaries
18. Mermaid diagrams (copy/paste)
18.1 Task → trial → trace → graders → score

18.2 3-tier portfolio (CI → staging → prod)
18.3 Evaluation harness vs Agent harness
19. Decision tables & checklists
19.1 Which grader should I use?
| Dimension | Prefer | Why |
|---|---|---|
| objective correctness / end-state | deterministic outcome checks | cheapest, debuggable, stable |
| tool invocation correctness | contract tests + tool-call verification | catches wrong tool/params |
| subjective quality (tone/UX/helpfulness) | LLM rubric + periodic human calibration | scalable but needs grounding |
| safety (policy + injection) | deterministic checks + adversarial suite + spot human review | must be strict |
| multi-agent coordination | schema/protocol validators + coordination metrics | distributed-system style |
19.2 Deployment checklist
Before deployment
- Golden set + adversarial set exists
- Step/time/cost budgets + loop stops enforced
- Tool contracts tested (bad params, malformed returns, retries)
- Prompt injection suite + policy adherence metrics
- Sandbox tests for high-risk tools
After deployment
- Full trace logging (LLM calls, tool calls, observations)
- Dashboards: success, trajectory health, latency, cost, safety
- A/B testing pipeline for changes
- Human/LLM judging loop with calibration
20. Starter kit repo layout + templates
This repo ships a drop-in structure for:
- Golden / Open-ended / Adversarial / Failure-replay suites
- Task YAML templates with graders + tracked metrics
- Rubrics for LLM judging
- CI gating configuration (example workflow skeleton)
See:
evals/for suites and example tasksevals/_shared/for reusable rubrics/schemas/fixturesscripts/for harness entrypoints (stubs to wire into your stack)
Appendix A: Template schemas
See evals/_shared/schemas/task.schema.json (minimal schema you can extend).
Appendix B: Example task YAMLs
See:
evals/golden/fix-auth-bypass_1.yamlevals/open_ended/support-chat_resolution_1.yamlevals/adversarial/prompt-injection_tool-misuse_1.yamlevals/failure_replays/incident-2026-01-xx_looping-retries_1.yaml