Chapter 13.1: Governance, Ethics & Human Element
Address governance, ethics, and human factors in production ML systems
Governance, Ethics & The Human Element
The core mental model
Production ML is not “ship a model.” It’s operate a socio-technical system:
- models affect people and decisions,
- decisions change data,
- regulations impose obligations,
- humans own accountability.
Governance and ethics are how you keep speed + trust simultaneously.
1) Model governance: what it is (and what it buys you)
Governance = control + auditability + repeatability
A governed ML system makes it possible to answer, quickly and confidently:
- What model is live, where, and why?
- What data + code produced it?
- Who approved it?
- What changed since the last version?
- How do we roll it back safely?
Why governance becomes non-optional
- regulatory/compliance pressure (risk-based regimes, stricter obligations for “high-risk” systems)
- business risk (silent failures, reputational damage, opportunity cost)
- scaling complexity (many models + many teams)
Heuristic: If you can’t audit decisions, you can’t scale responsibly.
2) Governance integration model (how “deep” it must be)
Your governance depth depends on:
- regulation strength (health/finance vs low-risk domains)
- AI risk category + business risk
- number of models / deployment frequency
Two common operating modes
- Strict governance everywhere: embedded into each stage (train → eval → deploy → monitor).
- Light governance at scale: governance primarily in model management (registry, monitoring, access controls) for quality + operational efficiency.
Rule: The more models you ship, the more you need standardized governance—even in low-reg domains.
3) The governance artifacts that actually matter
These are the “production evidence pack” items:
A) Reproducibility & lineage
- code version (commit), environment/container digest
- data snapshot/version, feature version
- hyperparams/config, seeds (as applicable)
- training/eval reports + slice metrics
B) Documentation (not essays—decision-grade)
- Model card: intended use, limitations, training data summary, evaluation results (incl. slices), ethical considerations, monitoring plan
- Data sheet: data provenance, collection biases, labeling policy, privacy notes
- clear owners + escalation paths
C) Validation gates
Multi-stage validation should include:
- offline metrics + slices + calibration (if scores drive actions)
- business KPI proxies / constraints
- explainability checks (at least “is it using sensible signals?”)
D) Logging + auditability
- serving logs (inputs/feature stats, outputs, model/version IDs)
- audit trails for approvals, promotions, and access
- monitoring alerts tied to runbooks
4) Responsible AI: the practical sub-playbooks
A) Fairness (measure, then decide trade-offs)
Where bias comes from
- data: historical, representation, measurement bias
- labeling bias
- feature choices
- objective functions and thresholds
- evaluation that hides subgroup regressions
Metric reality
Different fairness metrics conflict (e.g., demographic parity vs equalized odds). You must pick based on:
- domain harms
- legal/compliance expectations
- business trade-offs
Mitigation toolkit (choose by where bias enters)
- pre-processing: re-sampling, re-weighting
- in-processing: fairness constraints during training
- post-processing: different thresholds per group (careful: policy + explainability implications)
Rule: You don’t “add fairness later.” You add fairness as slice gates + monitoring.
B) Explainability (debugging and accountability)
Use explainability for:
- debugging shortcut features / leakage
- understanding failure slices
- communicating limitations and risks
- supporting audits
Practical pattern
- global: feature importance, cohort analysis
- local: per-decision explanation (LIME/SHAP-style) when needed
Heuristic: Explainability is most valuable when it changes what you do next (feature fixes, data fixes, policy changes).
C) Transparency (system-level, not just model internals)
Transparency includes:
- what data is used
- what objective is optimized
- what the model is not good at
- what happens on low confidence / failures
- how users can contest/correct outcomes (when relevant)
Rule: “AI-powered” isn’t transparency. Clear limits are.
D) Privacy (minimize, protect, and prove it)
Practical defaults:
- data minimization (collect only what you need)
- pseudonymization where feasible
- retention + deletion propagation (especially if user data)
- access controls and audit logs
Advanced techniques (use when required):
- differential privacy
- federated learning
- secure computation (HE/SMPC)
Heuristic: Most teams get 80% privacy win by doing minimization + access hygiene + retention controls well.
E) Security (treat ML as an attack surface)
Threats to plan for:
- data poisoning (training-time)
- adversarial inputs (serving-time)
- model stealing/inversion
Defenses:
- strong data validation + provenance checks
- input sanitization + anomaly monitoring
- rate limits + authentication + logging
- robustness testing / adversarial training where warranted
5) Holistic production readiness: “ML Test Score” as a maturity rubric
A useful rubric is to score readiness across:
- data/features
- model development
- infra
- monitoring
Key idea: manual check = half credit; automated repeated check = full credit. Overall readiness is constrained by the weakest category.
A minimal “ML Test Score” checklist you can adopt now
- data invariants + schema expectations are codified
- features are unit-tested and cost-checked
- training is reproducible enough for audits
- full pipeline integration test exists
- model validated before serving + canary rollout
- rollback is safe and tested
- skew/drift/perf regression monitors exist
Heuristic: Use this rubric as a roadmap: convert repeated incidents into automated checks.
6) The human element: team structures that scale ML
Roles that repeatedly show up
- DS / Applied scientist (hypotheses, evaluation, analysis)
- ML engineer (training/serving systems)
- MLOps/platform engineer (tooling, CI/CD, reliability)
- data engineer (pipelines, contracts, data quality)
- security/compliance, SME, PM
Org models (common archetypes)
- separate specialist teams (clear expertise, slower handoffs)
- “full-stack” DS/MLE (fast early, burnout risk)
- platform-enabled model: platform team builds paved roads; product MLEs own outcomes (high scale pattern)
Rule: If you want velocity across many models, invest in platform/paved roads, not heroics.
7) User-centric trustworthy ML products (how to avoid “AI disappointment”)
Manage expectations
- communicate capabilities and limits
- show confidence / uncertainty appropriately
- avoid overclaiming autonomy
Design for smooth failure
- fallback behaviors (rules, defaults, humans)
- “low confidence” routes to safer flows
- guardrails and prescriptive UIs for high-risk actions
Build feedback loops
Types of feedback to capture:
- implicit (clicks, dwell time)
- explicit binary/categorical (“this was wrong”)
- free-text corrections (often highest value)
- user-provided labels (gold)
Heuristic: Make feedback cheap to give and visible in its impact—or users stop giving it.
8) Reference architecture: governance embedded in the lifecycle
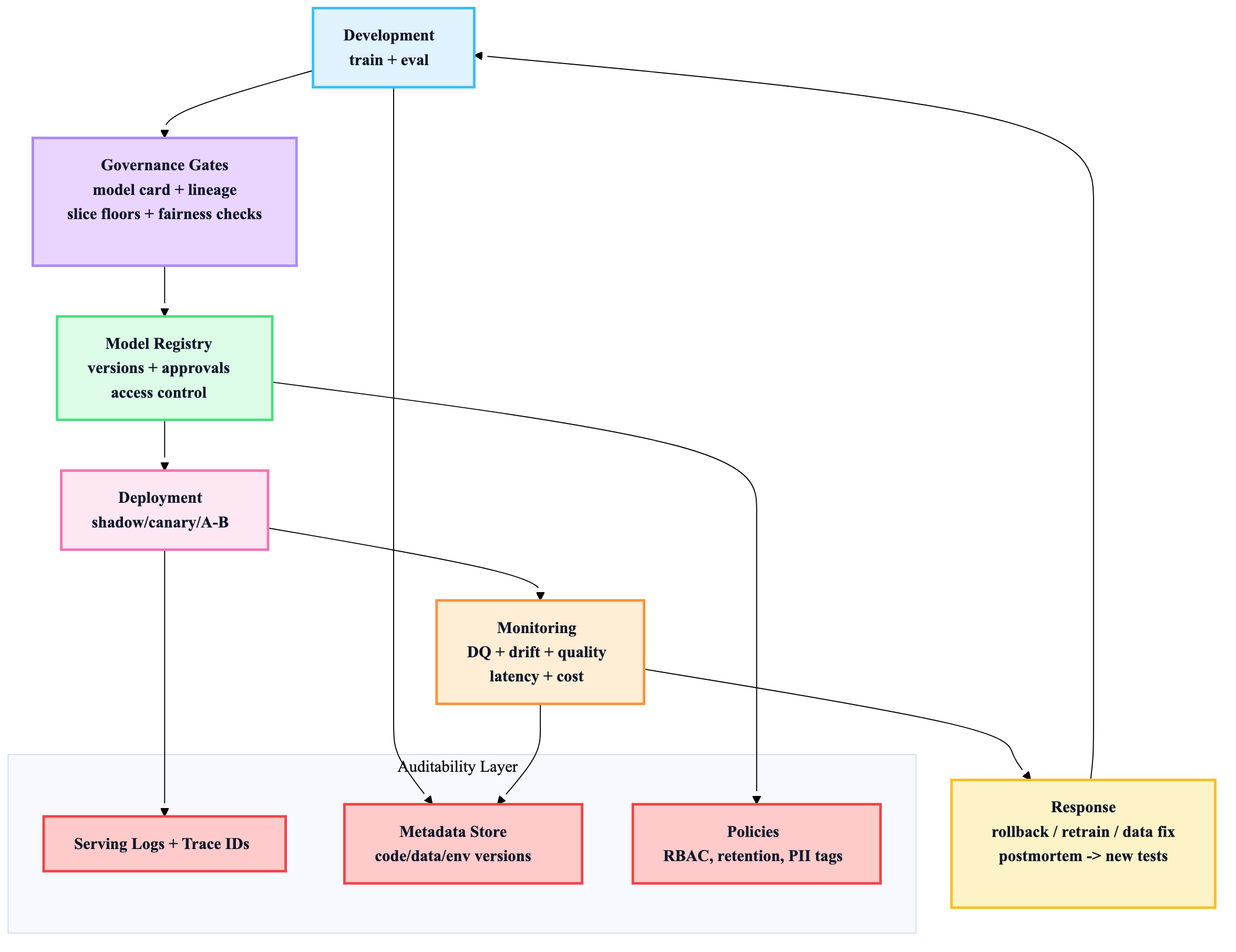
If you only implement 10 things
- Model registry with approvals, ownership, and full lineage
- Model cards + data sheets (short, decision-grade)
- Automated gates: DQ + slice floors + calibration + skew checks
- Canary/shadow rollouts + tested rollback
- Evaluation store: inputs/outputs/versions + trace IDs
- Fairness as explicit slice metrics + monitoring (not a PDF policy)
- PII tagging + retention/deletion propagation
- Security baseline: IAM/RBAC, secrets mgmt, rate limits, audits
- Platform “paved roads” + clear oncall/incident playbooks
- UX that fails smoothly + feedback loops for continuous improvement