Chapter 1: ML Problem Framing
Learn how to frame ML problems correctly to avoid the most common failure mode in production ML systems - building the right model for the wrong problem.
ML Problem Framing
Why this step exists
Most ML failures are framing failures, not modeling failures:
- You optimize the wrong target (proxy label mismatch).
- "Great offline metrics, zero business impact."
- You build a model when rules would've been cheaper + safer.
- You design something that can't be served (features unavailable / latency impossible).
1) The Framing Stack (work top → down)
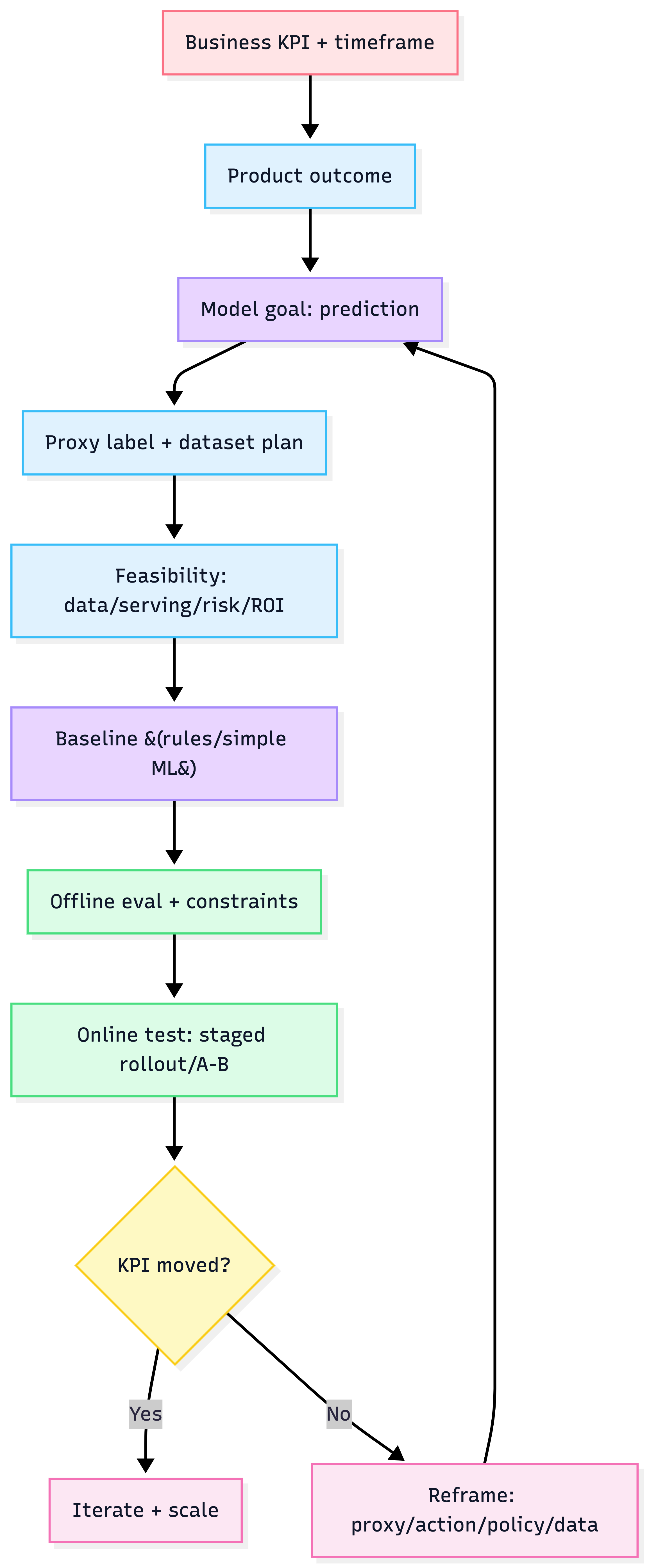
Level 0 — Business objective (the why)
Define the business problem in one sentence + one metric. Examples: reduce churn %, increase conversion %, cut manual review hours, reduce fraud loss $.
Heuristic: if you can't state a measurable KPI + timeframe, you don't have an ML project yet.
Level 1 — Product outcome (the what)
What should the product/system do differently after ML exists? Examples: "route tickets faster", "rank items better", "flag risky transactions".
Level 2 — Model goal (the prediction)
The model should output a prediction that enables the product outcome. Examples: "P(user purchases item X)", "P(transaction is fraud)".
Level 3 — Decision policy (the action)
How is prediction used to trigger action?
- thresholding
- top-K ranking
- human review queue
- block/allow
Rule of thumb: write this policy early—many "accuracy wins" don't matter because policy isn't actionable.
2) Should we use ML at all?
Fast decision tree
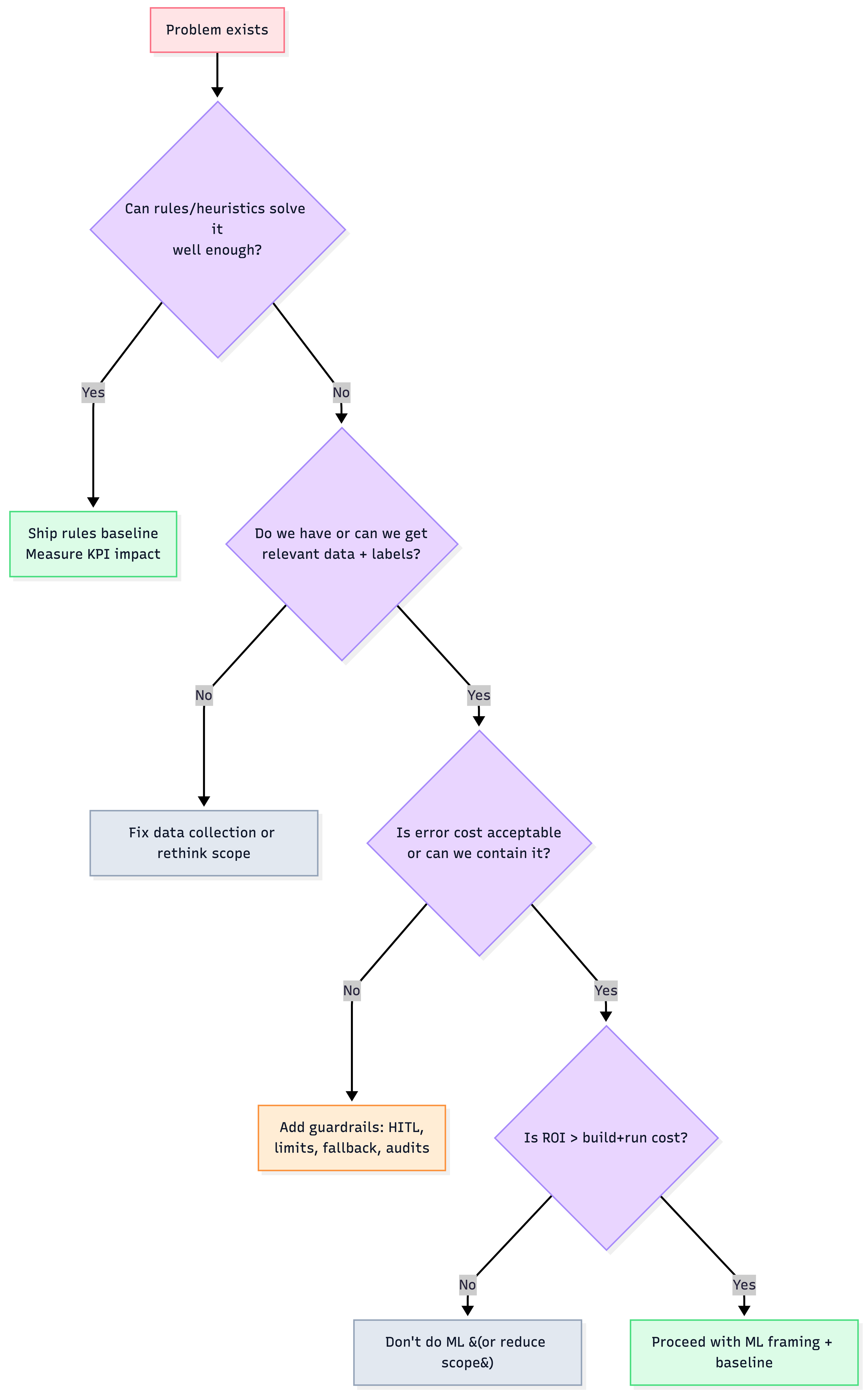
"Use ML when…" checklist
- Patterns are too complex for explicit rules (vision/NLP/fraud-like signals).
- The task repeats at scale (high volume decisions).
- Data exists or can be created.
- You can tolerate and manage errors (or add human-in-the-loop / guardrails).
- The world changes (rules get brittle; retraining helps).
"Don't use ML when…"
- Rules or simple stats achieve acceptable KPI.
- Data is weak or cannot be collected.
- Errors are catastrophic and can't be contained.
- Interpretability/auditability is mandatory and black-box behavior is unacceptable (unless mitigated).
- ROI doesn't justify ongoing maintenance.
3) Pick the right ML product archetype (drives requirements)
| Archetype | What it is | Success focus | Typical guardrails |
|---|---|---|---|
| Automation augmentation ("Software 2.0") | Replace/augment rules with learned behavior | measurable uplift vs baseline | fallback to rules |
| Human-in-the-loop | Model assists humans | time saved + reduced mistakes | queueing, confidence thresholds |
| Autonomous | Model acts without humans | failure rate + severity | safety constraints, audits, staged rollout |
Heuristic: the more autonomous, the more your roadmap becomes "risk + monitoring + rollback", not "accuracy".
4) Define the ML problem correctly (and avoid scaling traps)
Choose task type based on output
- Classification (binary/multiclass/multilabel/high-cardinality)
- Regression (scores/probabilities)
- Generation (text/image/audio; usually needs eval + safety controls)
Framing trick: avoid "giant multiclass" when entities change
If the label space grows (apps/products/items), prefer:
- score-based regression:
P(user interacts | user features + item features)instead of "predict which item among 50k".
Heuristic: if you expect new classes weekly, don't hardwire class IDs into the model output.
5) Proxy labels: the single most common cause of "model works, product fails"
When the true outcome isn't directly labeled ("useful", "quality", "trust"), you choose a proxy.
Proxy label selection rubric
Score each candidate label on:
- Alignment with desired outcome
- Gaming risk (clickbait / spam incentives)
- Coverage (label volume + class balance)
- Latency (how quickly label arrives after prediction)
- Causal usefulness (does improving it plausibly move KPI?)
| Ideal Outcome | Proxy candidate | Typical failure mode |
|---|---|---|
| "Useful content" | click | optimizes for sensationalism |
| "Purchase intent" | add-to-cart | abandonment mismatch |
| "Quality answer" | thumbs-up | selection bias (only some users rate) |
Heuristic: prefer proxies closer to business value (purchase > click), even if sparser—then use sampling/weighting rather than downgrading the objective.
6) Feasibility & risk audit (do this before building anything big)
The 8 "production killers"
- Label scarcity / imbalance (rare positives)
- Feature not available at serving time (training/serving skew)
- Latency/QPS mismatch (p99 matters)
- Error cost underestimated (false positives vs false negatives)
- Distribution shift (drift, seasonality, new users/items)
- Adversarial behavior (fraud/spam)
- Compliance constraints (privacy/regulatory)
- Organizational readiness (no data pipeline, no owners, no monitoring budget)
Minimal feasibility table (use in kickoff)
| Area | Green means… | Red means… |
|---|---|---|
| Data | enough + reliable + legal | missing/dirty/blocked |
| Labels | obtainable + affordable | no labeling path |
| Serving | features + infra feasible | skew/latency impossible |
| Risk | failures contained | catastrophic failures |
| ROI | clear value + sponsor | unclear or negative |
7) Metrics that don't lie
Separate metrics (always)
- Business KPI: what leadership cares about (conversion, churn, $ loss)
- Model metric: offline evaluation (AUC/F1/RMSE/etc.)
- Satisficing constraints: must-not-break (latency p99, precision floor, fairness checks)
Rule: pick one primary model metric, and treat everything else as constraints.
Multi-objective recommendation (pragmatic)
If you have conflicting goals (engagement vs quality vs safety), prefer decoupled models:
- Model A scores quality
- Model B scores engagement
Then combine:
final = α*quality + β*engagement
Why this wins: you can tune α/β without retraining the underlying models.
8) Validate the KPI link early (offline success ≠ real success)
Must-do experiment plan
- Define baseline (rules / heuristic / existing system)
- Ship to small slice (e.g., 1% traffic) with safe rollback
- Run A/B test or staged rollout
- Measure KPI + guardrail metrics
Common "why KPI didn't move" diagnosis
- Prediction not early enough to act
- You optimized the wrong proxy
- The action policy is ineffective
- Thresholds are wrong
- Users adapt (feedback loops)
9) A practical framing workflow
10) The "One-page kickoff spec" (copy/paste)
- Business KPI:
- Target users & workflow change:
- Decision being improved:
- Model output:
- Action policy: (threshold/top-K/HITL)
- Primary model metric:
- Constraints: (latency p99, precision floor, safety)
- Proxy label + known risks:
- Data sources + labeling plan:
- Serving-time features confirmed: yes/no
- Rollout plan: baseline → 1% → 10% → 50% → 100%
- Owner + oncall + monitoring: