Chapter 4.2: Data Discovery Platforms
Industry case studies and best practices for building data discovery platforms that scale across teams
Data Discovery Platforms — Industry Case Studies
The core lesson from the case studies
As data volume and teams scale, “finding the right dataset” becomes a productivity + trust bottleneck. Mature companies solve it with a metadata platform that makes data:
- discoverable (search + browse)
- understandable (rich context + profiling)
- trustworthy (lineage + quality signals + certification)
- governed (PII, retention, access-aware discovery)
1) When a data discovery platform becomes worth it
Trigger conditions (you’re already late if these are true)
- Data scientists/engineers spend lots of time “where is the data?” instead of building.
- Data is spread across warehouses/lakes/DBs with inconsistent naming.
- Trust erosion: “I don’t know if this table is accurate / current / approved.”
- Tribal knowledge dominates (Slack pings and personal docs).
- Compliance requires knowing lineage/PII/retention/deletion.
Heuristic: If “dataset selection risk” is causing rework, incidents, or blocked projects weekly, build/adopt a discovery platform.
2) What the best platforms converge on (capabilities that repeat across companies)
Capability checklist (minimal → advanced)
Must-have
- Unified search across tables/dashboards/pipelines/models/users
- Rich metadata (schema, owner, freshness, descriptions, tags)
- Lineage (upstream sources + downstream consumers)
- Programmatic APIs (so metadata can power automation)
Should-have
- Profiling & stats (nulls, distributions, distinct counts, popularity)
- Collaboration features (comments, expert finder, Q&A, ownership workflows)
- Curation/certification (trusted “golden datasets”)
Could-have
- Personalization / ranking based on role/team/usage
- NLP-assisted discovery
- Active metadata (metadata triggers actions, not just documentation)
3) Architecture generations (and the trade-offs you inherit)
This is one of the most actionable frameworks in the chapter: three generations of metadata architecture.
| Gen | Architecture style | How metadata comes in | Pros | Cons | Best fit |
|---|---|---|---|---|---|
| 1: Monolith + crawlers | UI + DB + search (+ graph) | Pull-based crawlers | fast MVP, fewer parts | stale metadata, crawler fragility, scaling pain | early stage / single team |
| 2: 3-tier + service API | Service layer + DB + index | Push-enabled via APIs | better contracts, programmatic use cases | harder reactive workflows, bottlenecked evolution | mid-stage orgs |
| 3: Event-sourced metadata | metadata changelog → materialized stores | stream-first (Kafka-like) | freshness, reactive systems, scalable consumers | higher initial complexity | large scale / many domains |
Default heuristic
- Start Gen 1 if you need speed, but plan an upgrade path.
- If you already have many producers/consumers and freshness matters, jump to Gen 3.
4) Push vs Pull ingestion (strong industry bias)
Why “push” wins at scale
Pull-based crawlers break due to:
- credentials/permissions drift
- network/source downtime
- brittle connector logic
- slow freshness cadence
Push-based ingestion distributes responsibility:
- producers emit metadata changes
- platform consumes and indexes reliably
Rule of thumb: run hybrid initially:
- Pull to bootstrap/backfill
- Push for ongoing changes and freshness
5) Reference architecture (Gen 3, event-sourced “changelog is truth”)
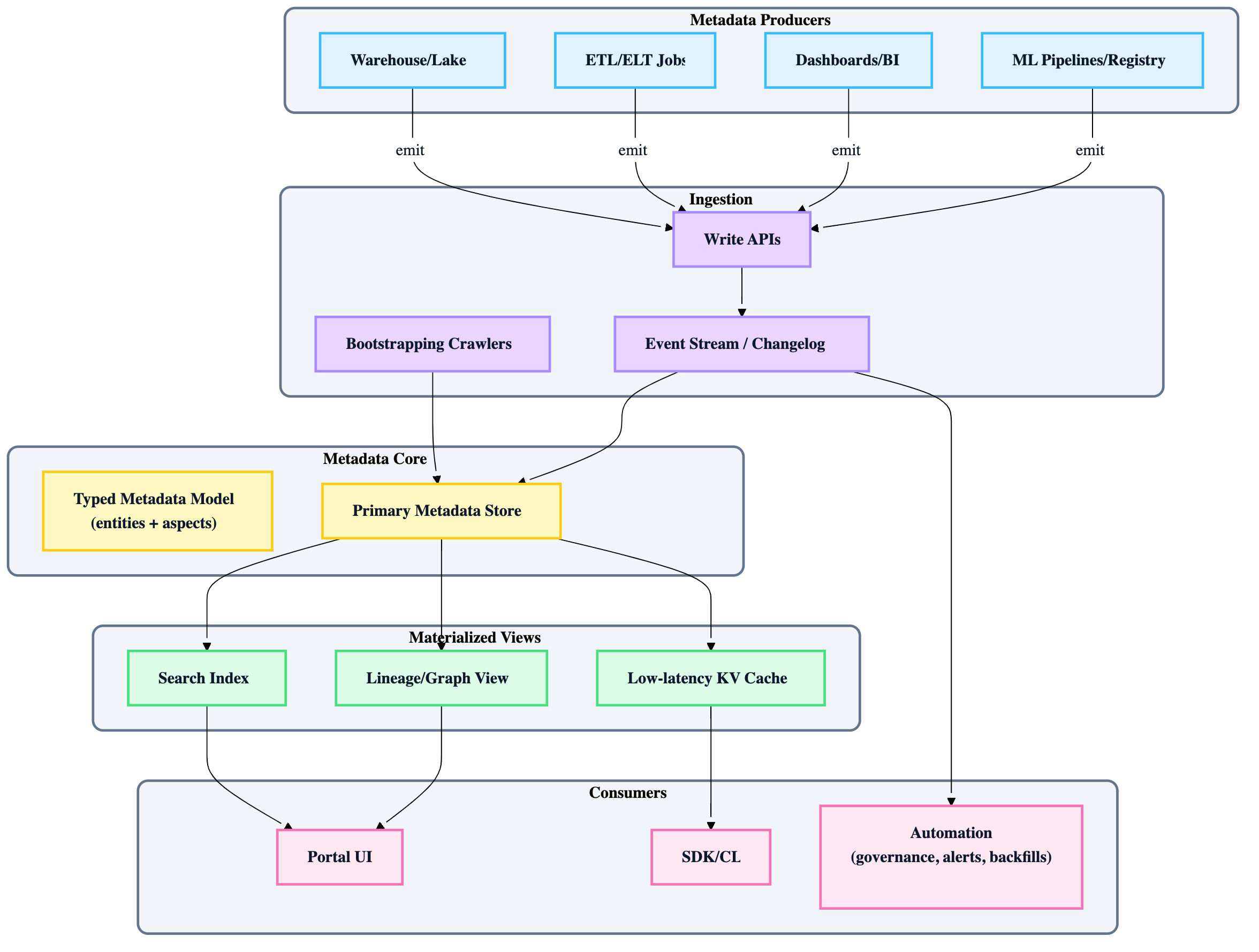
Key idea: treat metadata as a stream of changes, not periodic snapshots.
6) The “Trust signals” playbook (how leaders solved “sea of dubious tables”)
Platforms added trust via layered signals:
- Freshness & job stats (is it updated, when, by whom?)
- Usage/popularity (what do others rely on?)
- Lineage (what produced it, what breaks if it changes?)
- Certification (blessed datasets/entities)
- Quality indicators (profiling, null spikes, anomalies)
- Ownership clarity (who answers questions / fixes issues)
Heuristic: start with ownership + freshness + lineage. Add quality scoring later.
7) Adoption is the hard part (what repeated across companies)
The common failure mode
Building a catalog doesn’t automatically change habits.
What worked in case studies
- UI/UX treated as first-class (not “internal tool aesthetics”)
- Integrations into workflows (e.g., chat ops, query tools, IDE links)
- Social features (tags, comments, experts)
- Clear “golden paths” for certified assets
Heuristic: If it isn’t integrated into daily workflow, it becomes “a website people forget.”
8) Security vs democratization (how to not create a data leak machine)
A discovery portal should:
- allow broad discovery without exposing restricted details
- respect access controls and privacy constraints (PII tags, masking rules)
- maintain audit logs for sensitive interactions
Rule: “Searchable” does not mean “readable.” Metadata visibility can be broader than data access, but must be policy-aware.
9) Build/Adopt decision framework for MLOps leads
Decide scope first (what entities matter for MLOps)
Start by supporting:
- datasets/tables
- features (if you have feature definitions)
- pipelines/jobs
- models + model versions
- dashboards + metrics
- people/teams
MVP feature set (high ROI for MLOps)
- search + dataset pages (schema, owner, freshness)
- lineage (dataset → features → model)
- programmatic APIs/events (so governance + automation can subscribe)
Build vs OSS vs Vendor (pragmatic)
- If you need fast time-to-value and low ops burden → managed/vendor
- If you need extensibility + event-sourcing + deep integration → OSS or build around an event log
- If you have 1 team and low scale → keep it simple (manifests + data cards) until pain repeats
10) “If you only do 5 things” checklist
- Establish ownership for every critical dataset (no owner = no trust).
- Make freshness visible and reliable (staleness kills adoption).
- Implement lineage for impact analysis and debugging.
- Add certification for canonical datasets (reduce choice overload).
- Provide APIs/events so metadata becomes operational (governance/alerts/automation).