Chapter 2.2: MLOps Platforms
Design, build/buy decisions, and operating models for ML platforms that scale across teams
MLOps Platforms (Design, Build/Buy, and Operating Model)
What an ML Platform is (operational definition)
An ML Platform is a shared internal product that standardizes and automates the ML lifecycle so teams can repeatedly ship models with:
- predictable reliability
- reproducibility & auditability
- safe deployment
- monitoring + retraining loops …without every team reinventing pipelines, serving, and governance.
1) When you need a platform (vs “project MLOps”)
Use a platform when any of these become true
-
2–3 production models OR > 1 team shipping models
- frequent retraining / data refresh cycles
- production incidents from “skew / drift / silent failure”
- duplicated tooling (each team has its own tracking, its own deploy scripts, its own feature code)
- compliance / audit requirements (lineage, access control, approvals)
Anti-pattern: building a platform too early
If you have one model and no repeat use-cases, a platform becomes “internal bureaucracy-as-a-service.”
Heuristic: build platform capabilities only when the pain is recurring weekly (not hypothetical future scale).
2) The “Platform as a product” mental model
Treat the platform like you would treat an external product:
- Users: DS/MLE/DataEng/Service teams
- UX: paved roads, templates, CLI/SDK, golden paths
- Roadmap: driven by adoption + friction metrics (not platform engineers’ preferences)
- Success metric: “time to safe production experiment” + “number of models shipped per quarter” + “incidents per model”
Rule of thumb: the platform’s job is to reduce cognitive load and shift effort left (tests, validation, guardrails).
3) Capabilities map (what a “real” platform must cover)
Core capability groups
| Group | Must provide | Why it matters |
|---|---|---|
| Data & Features | standardized ingestion/ELT, feature definitions, training/serving parity | prevents skew + duplicates |
| Dev Experience | reproducible envs, notebooks/workspaces, templates | faster iteration, fewer “works on my machine” |
| Training | job orchestration, scalable compute, HPO | repeatable training at production scale |
| Registry & Artifacts | model versions, metadata, lineage, artifact store | reproducibility + governance |
| Evaluation | automated validation gates, offline + shadow/online checks | prevents bad models shipping |
| Serving | batch + online + (maybe) streaming, rollout strategies | production SLOs + safe releases |
| Observability | system + data drift + model quality signals | detect silent failure |
| Governance | IAM, audit logs, approvals, privacy | compliance and risk |
4) Reference architecture (capability-oriented)
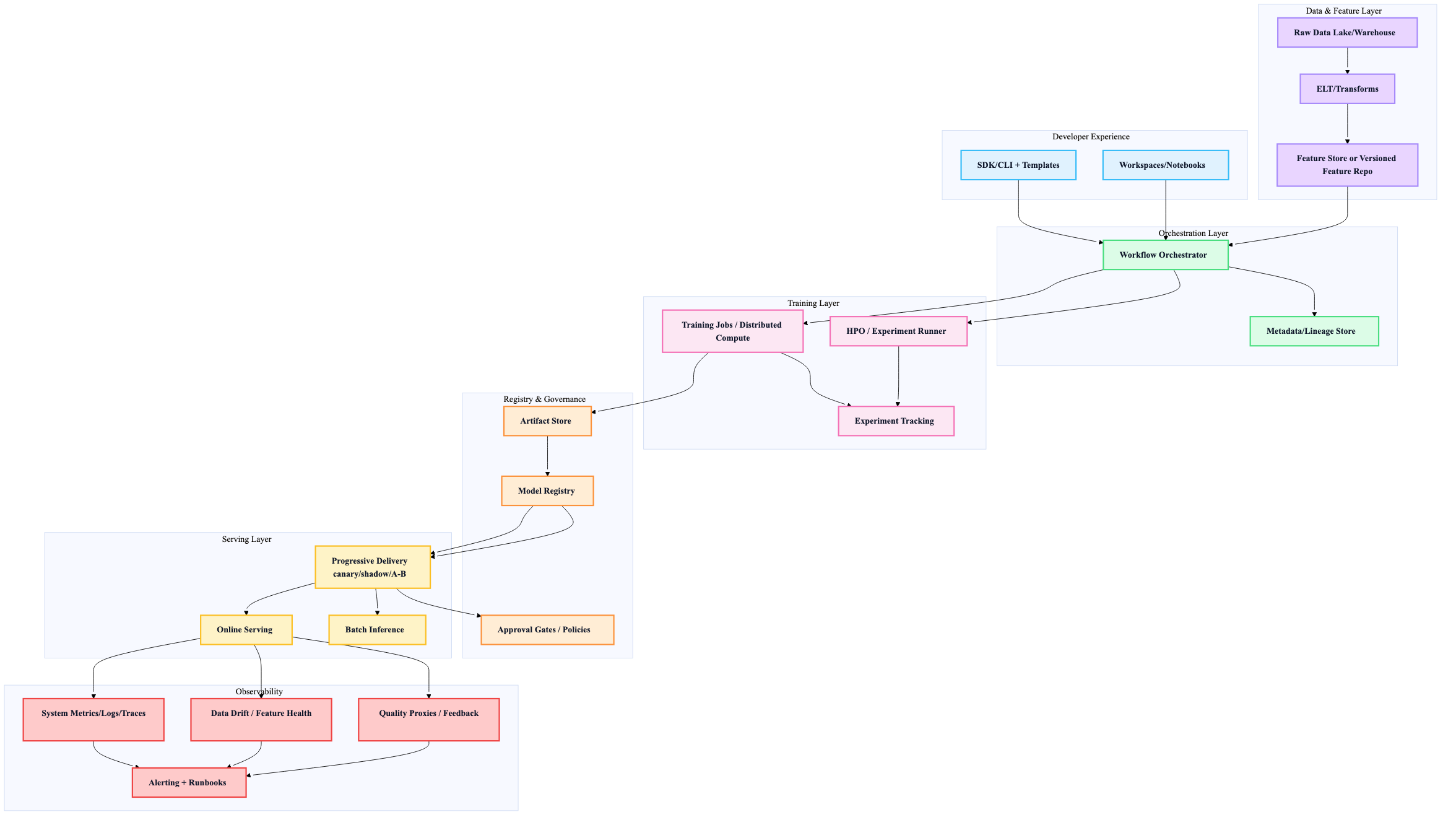
Heuristic: design the platform around interfaces/contracts (data schema, feature definitions, model package format), not around a specific vendor tool.
5) Big architectural choices (with defaults)
A) Build vs Buy vs OSS (default: “hybrid”)
| Option | Pros | Cons | Use when |
|---|---|---|---|
| Build | perfect fit, full control | slow, expensive, ops burden | you are at big scale or have unique needs |
| Buy (managed suites) | fastest, less ops | lock-in, cost, constraints | you need speed + reliability now |
| OSS (self-host) | flexible, no license | integration + maintenance | you have platform expertise and want modularity |
Default strategy: Buy managed primitives (compute, storage, auth, monitoring) + OSS for workflow glue + build only the differentiators (eval harness, safety gates, feature standards).
B) Monolithic suite vs best-of-breed (default: best-of-breed until it hurts)
- Monolithic: fewer integration points, unified UX, but less flexibility.
- Best-of-breed: flexible and future-proof, but integration is real engineering.
Heuristic: start best-of-breed if you already have strong data + infra stacks. Move toward a suite if integration cost becomes your #1 bottleneck.
C) Abstraction level: “paved roads” vs “platform enforces everything”
- Too little abstraction → DS/MLEs fight infra
- Too much abstraction → power users revolt / platform becomes blocker
Default: offer golden paths + allow escape hatches (bring your own container, custom step).
6) Maturity levels (what “good” looks like)
| Level | Platform reality | What you standardize | Key risk |
|---|---|---|---|
| 0: Ad hoc | scripts + manual deploy | nothing | incidents + irreproducibility |
| 1: Repeatable pipelines | orchestrated train + registry + basic deploy | pipeline templates | poor CI/testing + fragile releases |
| 2: CI/CD for ML | tests + gates + staged rollout | model promotion policies | platform complexity |
| 3: Multi-tenant scale | self-serve onboarding, quotas, cost controls | tenancy boundaries + governance | platform becomes “product” (needs PM mindset) |
Heuristic: don’t chase Level 3 unless you actually have many teams/models.
7) Platform operating model (how to not become a bottleneck)
Team interaction models
| Model | Works when | Fails when |
|---|---|---|
| Central platform owns everything | many teams, strong platform org | platform is under-resourced → queues |
| Embedded platform engineers | few teams, high-touch | doesn’t scale |
| Hybrid “platform + enablement” | most orgs | requires clear ownership |
Default: Platform provides self-serve paved roads, plus enablement (docs, office hours, onboarding) rather than “ticket-based MLOps.”
Ownership boundaries (must be explicit)
- Platform owns: templates, orchestration, registry, serving infra, observability primitives, governance framework
- Model teams own: features, training code, eval criteria, thresholds, business KPI alignment, oncall for model behavior (with platform support)
8) “Keep it simple” rules that prevent platform death
The 10 platform rules (hard-earned defaults)
- Reuse existing infra (data warehouse, CI/CD, auth) before adding “ML-specific replacements”
- Standardize interfaces before standardizing tools
- Containers everywhere (training and serving)
- Metadata/lineage is non-negotiable (otherwise you can’t debug or audit)
- Policy gates are automated, not wiki checklists
- Observability is part of the platform, not a model-team afterthought
- Make the golden path the easiest path
- Provide escape hatches for advanced use cases
- Cost controls are features (quotas, budgets, chargeback/showback)
- Adoption > elegance (if users don’t adopt, the platform doesn’t exist)
9) What to build first (minimal viable platform roadmap)
Phase 1 (highest ROI)
- standardized project template + CI baseline
- orchestrated training pipelines
- artifact store + model registry
- one supported deployment path (batch or online) with rollback
- baseline monitoring + alerting + runbooks
Phase 2
- automated validation gates (data + model)
- progressive delivery (canary/shadow)
- feature standardization / feature store strategy
- lineage + audit trails
Phase 3
- multi-tenant hardening (quotas, RBAC, sandboxing)
- self-serve onboarding + catalog
- advanced monitoring (drift + performance proxies + feedback loops)
Heuristic: ship Phase 1 fast; platform value comes from removing friction today, not from “ultimate architecture.”