Chapter 4.1: Data Sourcing, Discovery & Understanding
Learn how to identify, evaluate, and source data for ML systems while avoiding common pitfalls like training-serving skew
Data Sourcing, Discovery & Understanding
Why this matters
Bad models are often just bad data decisions with good training code. This phase prevents:
- training-serving skew (features not available at inference)
- “mystery datasets” nobody trusts
- silent bias/leakage
- pipelines that can’t meet freshness/volume needs
1) The “Data Shopping List” (requirements, not sources)
Start from the ML framing
Write requirements before hunting datasets:
A. Target + unit of prediction
- What’s the entity? (user, item, transaction, session)
- What’s the time window? (next day, next week, real-time)
B. Candidate features (hypotheses)
- What signals likely predict the target?
- Which of these are available at serving time?
C. Granularity / volume / freshness
- Granularity: event-level vs aggregated
- Volume: enough to cover tails + rare classes
- Freshness: daily vs hourly vs real-time
D. Bias risks
- Who is missing from the data?
- What population does this data represent?
Heuristic: If you can’t specify granularity + freshness, you can’t choose ingestion architecture.
2) Source types and what they’re good for
| Source type | Typical strengths | Typical failure modes | Operational note |
|---|---|---|---|
| User-provided inputs | direct intent signals | malformed/noisy, adversarial | validate aggressively |
| System-generated logs | high volume, objective events | missing context, schema drift | define contracts + schemas |
| Internal DB / warehouse | structured, business-critical | access friction, integration complexity | lineage + ownership required |
| Public datasets/APIs | fast bootstrap | inconsistent quality, rate limits, ToS | treat as external dependency |
| 3rd-party vendors | enriched signals | cost + opaque lineage | require QA + lineage |
| Web scraping | unique coverage | fragile + legal/ethical risks | respect ToS/robots + monitor breakage |
Rule of thumb: Prefer first-party system logs for long-term production value; use public/scrape sources mainly for bootstrapping or enrichment.
3) Batch vs Streaming ingestion (choose by freshness + coupling)
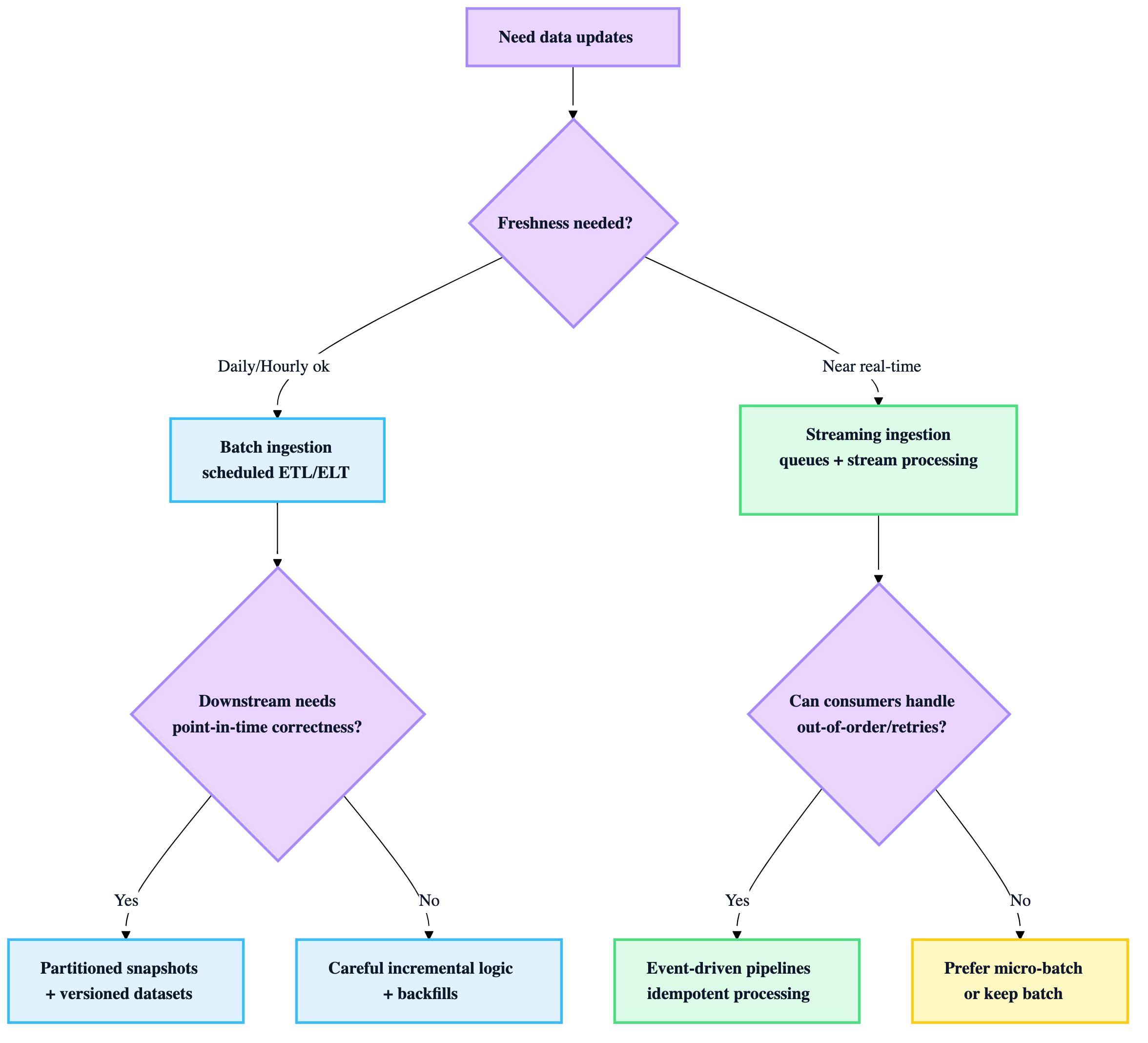
Heuristics
- Start with batch unless you have a real product need for near-real-time.
- Streaming requires: idempotency, ordering strategy, replay/backfills, and more observability.
4) Storage decisions (land raw first, then curate)
Practical “two-zone” standard
- Raw zone: store source-native payloads (JSON/HTML/logs). Immutable.
- Curated zone: cleaned, typed, deduped, analytics-friendly tables (often Parquet).
Format defaults
- Curated: Parquet (compression + columnar + schema evolution-friendly)
- Raw: JSON/text/blobs (source-native)
Heuristic: never overwrite raw. If you need to “fix” something, produce a new curated version.
5) Data versioning (non-negotiable for reproducibility)
You need to answer: “Which exact data produced this model?”
Minimum viable data versioning:
- dataset snapshot IDs (e.g.,
dataset_v2026_01_04) - pointers to raw + curated paths
- schema version
- extraction time range
Rule: model artifacts must link to:
- code commit
- dataset snapshot/version
- feature definitions version
- training parameters
- environment/container digest
6) EDA as a production activity (not just a notebook ritual)
EDA goals (production-first)
- Validate suitability for the intended task
- Expose missingness, outliers, duplicates
- Find leakage risks and shortcut signals
- Surface bias skews early
“Minimum EDA checklist”
- schema + types
- missing values per field
- distributions & long tails
- label balance (and slice balance)
- duplicates / entity collision
- time-based leakage checks (feature timestamp vs label timestamp)
- sample records sanity review
Heuristic: EDA output should become tests later (schema checks, distribution checks, null-rate thresholds).
7) Data documentation & discovery (so you don’t build “data folklore”)
Minimal “Data Card” template (use for every dataset)
- What it is + what it’s for
- Source + extraction method
- Owner + SLA (freshness, availability)
- Schema + key fields
- Known issues + bias risks
- Allowed usage (privacy/ToS)
- Versioning strategy + retention
When you need a catalog/discovery platform
If you have:
- many datasets, many teams, or frequent reuse
- repeated “where is the data?” cycles
- governance/audit needs
Core capabilities to expect from discovery platforms (as described in the chapter): search, rich metadata, lineage, profiling, collaboration/curation, APIs/integration.
Heuristic: Start with a versioned manifest + data cards; adopt a catalog when search + trust becomes a productivity bottleneck.
8) Early governance (do it now, not after the incident)
Immediate checks to implement
- Identify if sourced content can contain PII
- Access control via least privilege (roles per pipeline stage)
- Respect ToS / robots.txt for any external source
- Basic retention + deletion story (even if conceptual initially)
Rule: any external data source is a “dependency” with legal + operational failure modes—treat it like one.
9) Operational deliverables (what “done” looks like for this phase)
You’re done when you have:
- ✅ data requirements doc (granularity, volume, freshness, bias risks)
- ✅ documented source list + access method + ToS constraints
- ✅ raw + curated storage layout
- ✅ dataset versioning approach (even if simple)
- ✅ EDA notebook + a written findings summary
- ✅ initial data dictionary / schema
- ✅ owners + access controls defined