Chapter 10.1: Model Deployment & Serving
Deploy models to production with proper deployment strategies and serving patterns
Model Deployment & Serving
The core mental model
Deployment = moving a model artifact + dependencies into a production environment. Serving = the runtime + infrastructure that answers inference requests (online/batch/edge). In ML, “done” means: safe rollout + monitoring + rollback + governance, not “endpoint is up.”
1) Decide the serving mode first (batch vs online vs streaming vs edge)
| Mode | When it’s the right choice | Main strengths | Main risks |
|---|---|---|---|
| Batch (async) | predictions can be stale (hours/days ok) | simplest + cheapest at scale | staleness, delayed detection |
| Online (sync) | user-facing / event-driven, low latency | fresh predictions | tail latency, infra complexity |
| Streaming inference | continuous streams + NRT features | reacts quickly to events | stateful stream ops + backfills |
| Edge | offline/ultra-low latency/privacy | lowest latency, privacy | update/debug complexity |
Heuristic: start with batch or online + mostly batch features. Earn full real-time only where KPI ROI is clear.
2) The pre-deploy “requirements bar” (most teams skip this)
Lock these before choosing infrastructure:
- latency target (p95/p99), throughput (QPS), payload size
- scaling profile (bursty vs steady), need scale-to-zero
- data freshness needs (features + labels)
- cost constraints ($/1k requests, monthly cap)
- risk tolerance (blast radius allowed)
- compliance/security needs (PII, audit, access)
Rule: serving architecture is driven by non-functional requirements more than model type.
3) Packaging: what a deployable model artifact must contain
A production model artifact is more than weights:
- serialized model (framework-native or portable like ONNX)
- preprocessing/postprocessing code + parameters
- dependency lock (requirements/conda) + runtime env
- model signature/schema (inputs/outputs, types, shapes)
- metadata: data version, commit hash, metrics, owner, description
Heuristic: if you can’t load it in a clean container and run a prediction with a single command, it’s not shippable.
4) Serving interface design (treat as an API product)
Stable contract
- versioned request/response schema
- explicit error responses (validation failures, timeouts)
- idempotency keys if needed (especially async)
REST vs gRPC (simple decision rule)
| Choice | Use when | Why |
|---|---|---|
| REST/JSON | public/simple clients, easy debugging | ubiquitous + low friction |
| gRPC/Protobuf | internal high-QPS, larger payloads, lower latency | efficient serialization + HTTP/2 |
Heuristic: if you’re fighting p99 and payload is large, gRPC usually pays off.
5) The serving platform spectrum (pick the lowest TCO that meets needs)
A) Serverless (Lambda/Functions)
Best for: sporadic traffic, small models, event-triggered inference, cost-sensitive workloads.
Trade-offs
- ✅ scale-to-zero, low ops
- ❌ cold starts, package/resource limits, inconsistent latency
B) Managed ML endpoints (SageMaker/Vertex/Azure ML)
Best for: teams that want managed scaling/rollouts without owning K8s.
Trade-offs
- ✅ fast path to production patterns (autoscaling, variants, traffic splitting)
- ❌ cost and some platform coupling
C) Kubernetes (raw or via KServe/Seldon)
Best for: many models/services, custom networking/routing, strong platform team.
Trade-offs
- ✅ maximum control + portability
- ❌ highest operational complexity (TCO is real)
Heuristic: choose K8s when you have a platform team and a multi-model future—not just because it’s “standard.”
6) Online serving reference architecture (model-as-a-service)
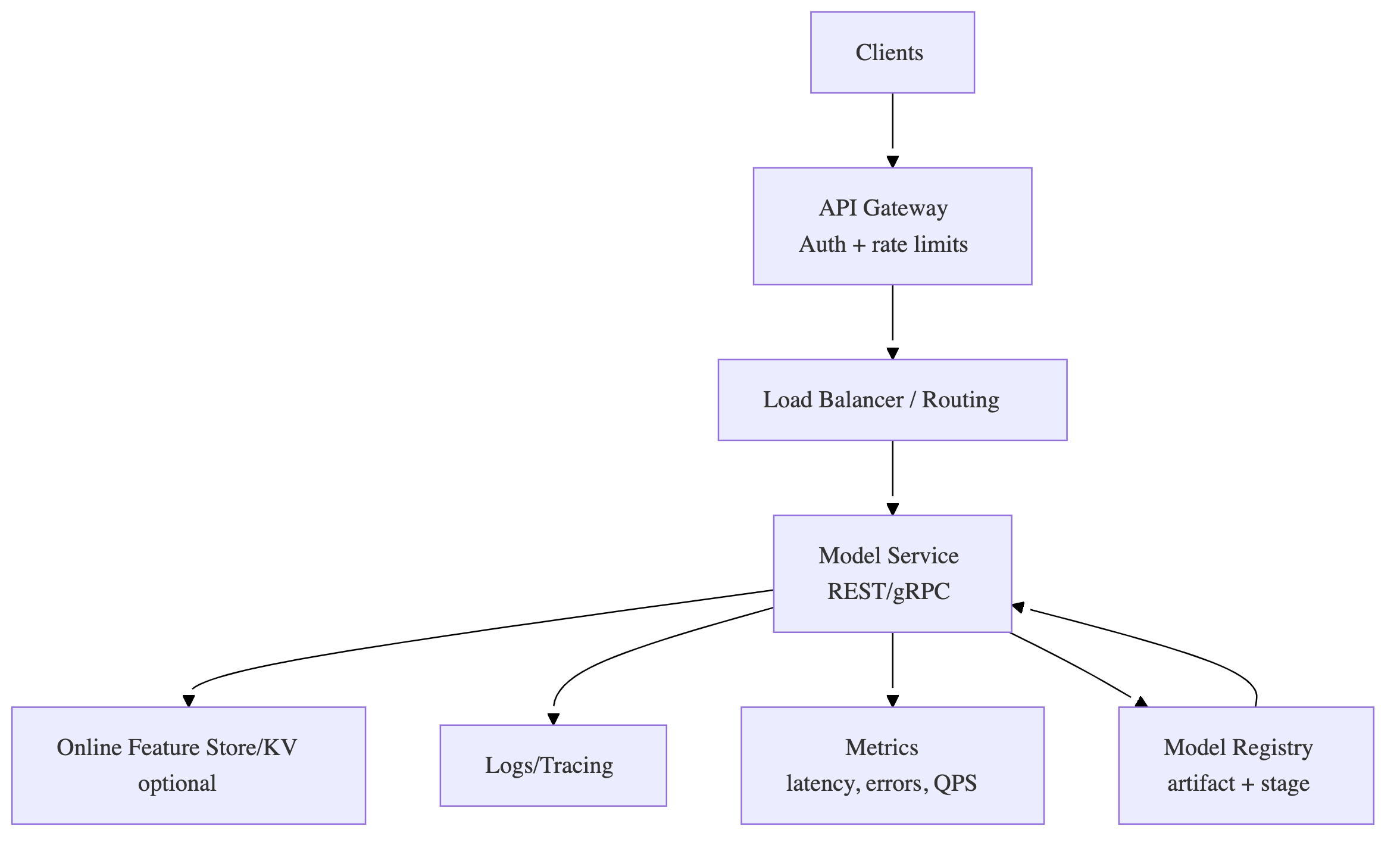
Rule: keep the serving system decoupled from training; connect them via a registry + promotion gates.
7) Batch prediction blueprint (high ROI, low drama)
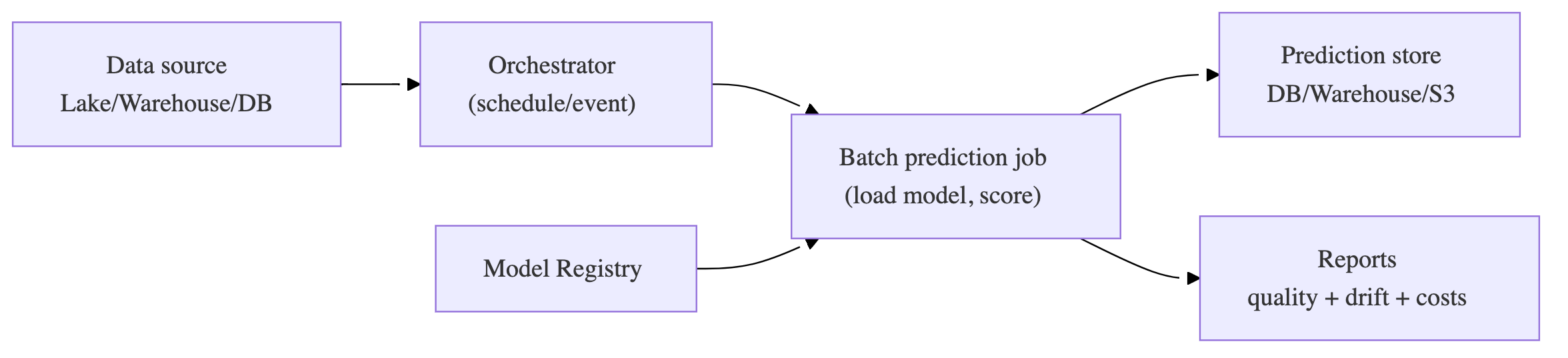
Heuristic: batch is the best default if “staleness threshold” is acceptable.
8) Performance optimization (p99 + throughput wins)
You optimize inference with three levers:
A) Model-level
- quantization (FP16/BF16/INT8; PTQ vs QAT)
- distillation
- pruning (only if hardware/runtime benefits)
- export/compile (ONNX/TensorRT/XLA/TVM-style)
B) Server/runtime-level
- dynamic batching (GPU especially)
- concurrency (threads/workers, async)
- warmup (avoid first-request spikes)
- caching (only if repeat inputs exist)
C) System-level
- multi-stage inference (cheap filter → expensive rerank)
- isolate feature retrieval from compute contention
- right-size instances and autoscaling triggers
Heuristic: optimize the biggest bottleneck first (often feature fetch fanout or batching strategy, not the model).
9) CI/CD for serving (two artifacts, two cadences)
Artifact 1: Serving app + infra
CI (PR):
- lint, unit tests (handlers, pre/post)
- build + scan container
- IaC validation
CD (merge):
- deploy to staging
- run contract + integration + load smoke
- manual approval → prod
Artifact 2: Model versions
Triggered by registry stage change:
- fetch approved model
- activate via config / dynamic loading / deployment update
- progressive rollout + monitors
Key idea: decouple “serving binary deploy” from “model update” when possible (dynamic loading from a model repo/registry).
10) Progressive delivery (how not to explode production)
| Strategy | What it does | Best for | Cost |
|---|---|---|---|
| Shadow | run challenger in parallel, don’t serve its output | safest prod validation | doubles compute |
| Canary | send 1%→5%→… traffic to new model | most common | moderate |
| Blue/Green | switch traffic between two identical envs | fast rollback | double infra |
| A/B test | controlled experiment to measure KPI impact | decision-making | depends |
Non-negotiables
- define success/fail thresholds per stage
- ensure sticky routing if user experience must be consistent
- have rollback automated or at least rehearsed
11) Rollback is part of the design (not an afterthought)
Rollback requires:
- prior champion model available + loadable
- versioned config + infra
- a fast traffic switch mechanism (gateway/LB/mesh/platform)
- tested procedure
Rule: “we can rollback” is only true if you’ve practiced it.
12) Monitoring & governance (serving is ongoing ops)
Always monitor (minimum)
- p50/p95/p99 latency, QPS, error rate
- model load failures, OOMs, CPU/GPU utilization
- feature freshness/lag + null spikes
- prediction distribution shift (label-free early warning)
- cost per request (FinOps)
Governance essentials
- audit trails: who promoted what model when
- model registry stages (dev/staging/prod/shadow)
- security: authn/authz, secrets management, endpoint protection
- documentation: model card + intended use + limitations
Deployment readiness checklist (copy/paste)
- model artifact includes preprocessing, signature, deps, metadata
- model registered with lineage + metrics + owner + stage
- API contract validated (schema, errors, auth)
- staging load test meets p95/p99 + throughput SLAs
- progressive rollout strategy selected + thresholds defined
- monitoring dashboards + alerts live (latency/errors/freshness/drift)
- rollback tested (not just written)
- governance/compliance evidence captured (logs, approvals, audits)