Chapter 3.1: Environments, Branching, CI/CD & Deployments
Learn how to structure environments, repos, and CI/CD pipelines for ML systems with code and model deployment lanes
Environments, Branching, CI/CD, Repo Structure, and Deployments
This chapter is really about one production truth:
You don’t “deploy ML.” You deploy (1) code + infra changes and (2) model artifacts—on different cadences, with different risk controls.
1) The 2 deployment lanes mental model
Lane A — Deploy the pipeline/system
You deploy: DAGs/workflows, feature code, data processing jobs, infra changes, API changes.
Triggered by: code change (merge to main). Risk: breaks training/data/serving behavior.
Lane B — Deploy the model
You deploy: a specific trained artifact version (plus its metadata).
Triggered by: a pipeline run producing a validated candidate (registry event / manual approval). Risk: silent quality degradation (even if infra is stable).
Heuristic: treat “pipeline deploys” like software releases, and “model deploys” like controlled experiments.
2) Environment strategy (Dev / Staging / Prod) that actually works
Dev
Purpose: fast iteration, local tests, cheap experimentation.
Rules
- dev can be messy, but must be reproducible (container/devcontainer).
- you should be able to run a “mini pipeline” locally (sample data, mocked services).
Staging (pre-prod)
Purpose: catch integration + operational issues before users see them.
Rules
- staging should mirror prod in topology and config, not necessarily scale.
- use representative data (synthetic or scrubbed), and realistic traffic simulation.
Prod
Purpose: stability + observability + safe rollouts.
Rules
- deployments are gated (approvals, canary, rollback).
- everything emits metrics/logs/traces, and has runbooks.
Heuristic: staging is where you validate system behavior; prod is where you validate business impact.
3) Branching strategy: optimize for “always deployable main”
This chapter uses GitHub Flow-like thinking:
main= always production-ready and deployable- short-lived
feature/*branches + PRs - CI blocks merge if quality gates fail
Practical rules
- keep PRs small (one intention)
- avoid long-lived branches (merge pain + drift)
- require CI checks + review for
main
Heuristic: in MLOps, long-lived branches are extra dangerous because data/labels drift while you’re “still developing.”
4) CI vs CD (what belongs where)
CI (on PR / feature branch)
Goal: catch mistakes early, cheaply.
Typical CI gates
- lint/format/typecheck
- unit tests
- security scans
- build container images (optional)
- basic data/contract checks (schemas, sample batch)
CD (on merge to main)
Goal: safely release to environments.
Typical CD stages
- Deploy pipeline/system to staging
- Run integration/E2E + infra tests
- Manual approval gate
- Promote same artifacts to prod
- Smoke tests + monitor + rollback plan
Rule: avoid rebuilding artifacts in prod deploy. Promote the exact artifact tested in staging.
5) Deployment flow (end-to-end) in one diagram
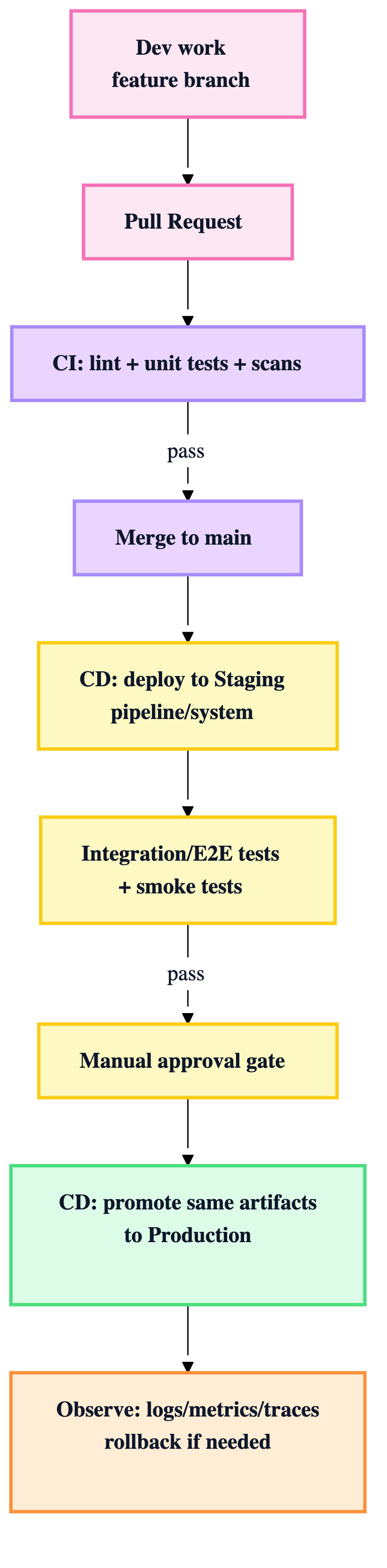
6) How model deployment fits (separate but connected)
Model release should be registry-driven (or at least model-version-driven), not “whatever just trained.”
Model promotion chain
- Training pipeline runs (often in prod or dedicated training env)
- Offline validation passes (metric floors, leakage checks, etc.)
- Candidate registered in model registry
- Deploy candidate to staging serving
- Operational validation in staging (latency/load/integration)
- Approve + progressive rollout in prod (canary/shadow/A-B)
- Promote to “champion” if online signals are good; otherwise rollback

Heuristic: Offline validation answers “is it statistically good?” Operational validation answers “does it run safely?” Online validation answers “does it improve the business?”
7) Repo / directory structure: “separate concerns, align to lifecycle”
A production-friendly structure tends to isolate:
- pipeline code (DAGs/workflows)
- training code
- serving code
- shared libraries (feature transforms, schemas)
- infra-as-code (Terraform)
- tests by type (unit/integration/e2e/load)
- configs per environment
A simple conceptual map:
| Area | What belongs here | Why |
|---|---|---|
pipelines/ |
orchestration definitions | deployed on code change |
training/ |
training scripts, eval | run by orchestrator/CT |
serving/ |
inference API, model loading | deployed as service |
shared/ |
feature logic, schemas, utils | consistency + reuse |
infra/ |
Terraform, IAM, networking | repeatable environments |
tests/ |
unit + integration + e2e | shift-left quality |
Rule: organize code to match deployment lanes: pipeline deploy vs model deploy.
8) The “production rules” checklist (use as guardrails)
Environment & release rules
- ✅ staging mirrors prod config (as much as practical)
- ✅ promote artifacts from staging to prod (don’t rebuild)
- ✅ explicit rollback plan for every prod deploy
Pipeline deploy rules
- ✅ CI blocks merge on failed tests
- ✅ CD deploys to staging automatically
- ✅ integration/E2E tests run in staging
- ✅ approvals for prod
Model deploy rules
- ✅ model registry is source of truth (versioned artifacts)
- ✅ offline gates + operational gates before prod
- ✅ progressive rollout (canary/shadow/A-B)
- ✅ monitoring includes model + data signals, not just infra