Chapter 6.1: Feature Engineering
Master feature engineering as the productized interface between raw data and model behavior
Feature Engineering
The core mental model
Features are productized interfaces between raw data and model behavior. So feature engineering isn’t “clever transformations” — it’s designing, versioning, serving, and monitoring signals with the same rigor as production APIs.
1) What “good” feature engineering looks like in production
A feature is production-grade when it has:
- Definition: what it means (business semantics), units, valid range
- Availability: computed at training + serving consistently
- Freshness: meets the latency window the use case needs
- Stability: resilient to schema changes and source quirks
- Governance: owner, lineage, access/PII tagging
- Observability: monitored for drift, null spikes, staleness
- Reusability: discoverable, shared, not reinvented per team
Heuristic: if you can’t explain why this feature should generalize, it’s probably a shortcut.
2) The feature engineering lifecycle (what to operationalize)

Rule: EDA insights must become tests + monitors, or they’ll be forgotten.
3) The “3 feature computation modes” model (most important architecture choice)
| Mode | What it is | When to use | Main trade-off |
|---|---|---|---|
| Batch | precompute on schedule | stable aggregates, long windows | staleness |
| Streaming / NRT | continuous updates from events | fraud, session recos, anomalies | state + ops complexity |
| On-demand | computed inside inference path | request-context features, last-mile joins | adds latency to serving |
Default starting point: Batch + a thin streaming layer + small on-demand set. Move to “fully online” only where ROI is clear.
4) Where transformations should live (prevents skew + tech debt)
Use this placement rule:
- Model-independent transforms (cleaning, normalization rules, reusable aggregates) → feature pipelines (batch/stream) → feature store/offline tables
- Model-dependent transforms (target encoding variants, model-specific scaling choices, post-join shaping) → training/inference pipeline (packaged with the model)
- On-demand transforms → inference pipeline and a backfill path using the same logic for training parity
Heuristic: if multiple models can reuse it, it should not live inside one model repo.
5) The “skew triangle” (training-serving skew prevention)
Skew comes from mismatched:
- Data (different sources or time ranges)
- Logic (different transform codepaths)
- Time (future leakage / wrong as-of semantics)
The strongest prevention patterns
- Single-source feature definitions (one DSL/code path for offline + online)
- Point-in-time correct training sets (“AS OF” joins)
- Log features at serving time and reuse for training (“what served is what trained”)
- Parity canaries: online feature values vs offline recompute
Rule: if you can’t backfill a feature deterministically, it’s not production-ready.
6) Feature quality: the checks that catch most problems
Pre-materialization checks (pipeline gates)
- schema/type validation
- null rate thresholds
- range/enum validity
- outlier caps (winsorize/clip) where appropriate
- duplication keys sanity
- leakage checks (timestamp discipline)
Post-materialization monitors (production)
- freshness/lag
- distribution drift
- missingness spikes
- cardinality explosions (categoricals)
- “top value” shifts (hash collisions / mapping issues)
Heuristic: track coverage (how often feature has a value) and stability (how fast distribution changes) for every top feature.
7) A compact “feature ops” lexicon (what to reach for)
Missing values (don’t blindly impute)
- delete column/rows only if justified (MCAR + low missingness)
- impute using train-only stats (avoid leakage)
- consider missingness as signal (add
is_missingflag)
Scaling & transforms (leakage alert)
- scale after split; fit scalers on train only
- clip/winsorize before scaling if outliers dominate
- log/Box-Cox for heavy skew
High-cardinality categoricals (default playbook)
- hashing trick for evolving categories + unknowns
- embeddings for dense representation (DL)
- avoid naive one-hot if cardinality is large
Cross features (interaction signals)
- only for true interaction effects
- manage cardinality explosion via hashing/regularization
Time-based features (where value often is)
- windowed aggregates (last 5m/1h/7d)
- lags, trends, seasonality
- define event-time vs processing-time explicitly
8) Feature selection: focus on generalization, not leaderboard wins
Use selection to:
- reduce overfitting
- reduce leakage risk
- reduce serving cost/latency
- improve interpretability
Practical defaults:
- start with simple filter checks (variance, correlation/MI)
- use embedded methods (L1, tree importance) for quick pruning
- use SHAP for explanation + debugging (not as the only selection tool)
Heuristic: if a feature is “important” but unstable across time slices, treat it as suspicious.
9) Feature store framing (what it’s for, not what it “is”)
A feature store is a way to operationalize:
- offline store (training, PIT correctness)
- online store (low-latency latest features)
- registry (definitions, ownership, lineage, versions)
When you need it
- multiple models reuse features
- online serving needs low-latency lookups
- skew incidents are happening
- governance/auditability is required
When you don’t (yet)
- single model, batch-only scoring, low reuse
- you can do versioned feature tables + manifests first
10) Reference architecture: batch + streaming + on-demand features
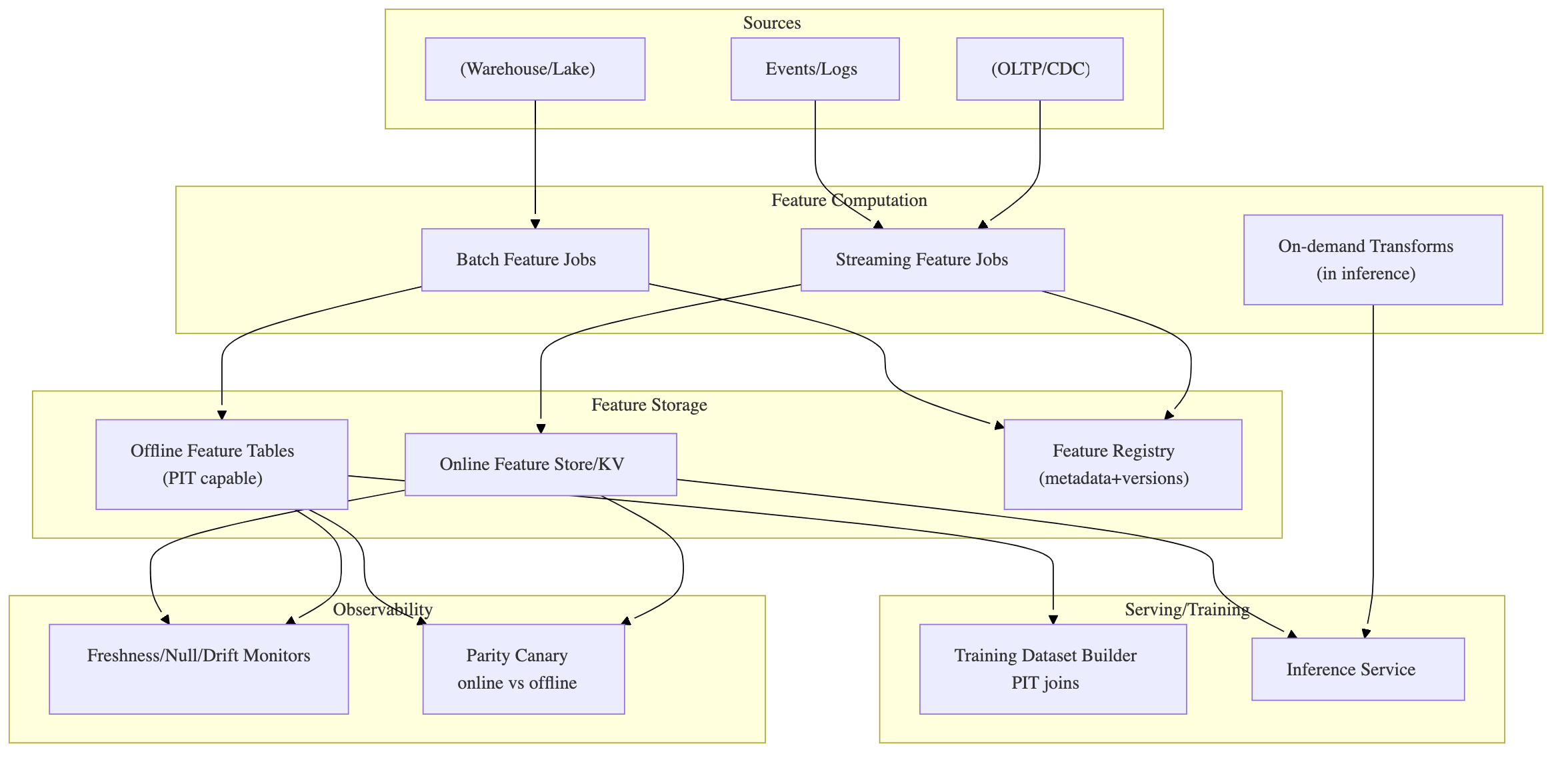
11) “Definition of Done” for a new feature (copy/paste)
A feature can be used in production only if:
- ✅ clear definition + units + valid range
- ✅ owner + documentation + lineage
- ✅ computed deterministically with versioning
- ✅ PIT training support (or explicitly not needed)
- ✅ serving availability confirmed (online/batch/on-demand)
- ✅ tests: schema/null/range + leakage checks
- ✅ monitors: freshness + drift + missingness + cardinality
- ✅ backfill/replay procedure exists
- ✅ cost/latency impact measured (esp. online)