Chapter 7.2: Model Development Lessons
Production lessons and best practices from mature ML organizations
Model Development — Lessons from Production Systems
The meta-lesson
In mature orgs, “model development” is business-aligned iterative systems engineering, not a modeling exercise. Winning teams optimize the loop: hypothesis → build → validate offline → validate online → monitor → retrain.
1) Production mindset shifts (what top teams do differently)
A) Business value first (offline is only a health check)
- Define success with stakeholders (KPI + timeframe), not just AUC/F1.
- Translate offline gains → expected KPI lift (even if rough).
- Size impact (“TAM” of the decision being improved) before over-investing.
Heuristic: if you can’t explain how a 1% metric gain becomes $$ or user value, you’re probably optimizing the wrong thing.
B) Iterative, hypothesis-driven development
- Start simple (heuristic / basic model) to learn fast and create a baseline.
- Every iteration starts with a hypothesis (“Feature X will fix failure mode Y in slice Z”).
- “Prototype → scale → revisit & improve” beats “big bang perfect model”.
Heuristic: model iterations without a named failure slice are usually noise.
C) Humans are part of the system
At scale, best systems are often hybrids:
- ML + rules + human-in-the-loop (HITL)
- humans for cold start, ambiguity, rare/critical cases, taxonomy evolution
Heuristic: add HITL where the marginal cost of a mistake is high or labels are ambiguous—not everywhere.
2) Data lessons (the unyielding foundation)
A) Data is messy: plan for sparsity, censoring, bias
Common realities:
- sparse and imbalanced outcomes
- non-stationary data (seasonality/trends)
- censoring/selection bias (you don’t observe the true outcome)
Playbook
- monitor feature coverage (how often values exist) and build fallbacks
- explicitly model time semantics (event vs ingestion vs processing time)
- if censoring exists, don’t naïvely train on observed outcomes without adjustment
B) Labeling is a system design problem
Winning patterns:
- unsupervised → supervised: discover structure first, then label with humans
- taxonomy design matters (objective tags, mutually exclusive where possible, “other” bucket)
- active learning for efficient labeling
- weak supervision for bootstrapping labels
- golden datasets + inter-rater agreement loops to stabilize definitions
Heuristic: if label definitions aren’t stable, model quality will plateau no matter how fancy the architecture is.
C) Preprocessing is production work
Real systems spend a lot of effort on:
- denoising, template stripping, normalization
- PII scrubbing
- missingness strategies (impute + missingness indicators; avoid “future leaks” via backfilling)
Rule: treat preprocessing pipelines as first-class deployable artifacts with tests.
3) Feature lessons (what actually moves the needle)
Embeddings are a repeat winner
Teams repeatedly use embeddings to:
- densify sparse behavior signals
- represent high-cardinality entities (users/items/tags)
- enable candidate expansion (similarity search)
Coverage and freshness dominate feature value
- High-coverage “good enough” features often beat sparse “high signal” ones in production.
- Real-time features are expensive; many teams win with batch features + thin real-time layer.
Heuristic: prefer features with stable semantics + broad coverage, then add specialized ones for the hardest slices.
Interpretability tooling is used for debugging, not just storytelling
- SHAP/attribution is used to find leakage, shortcut features, and business insight.
- Segment-level feature importance often matters more than global.
4) Model choice lessons (what top teams default to)
Start simple, earn complexity
Common progression:
- linear / tree models (fast, robust, great baselines)
- then deep learning when justified by data scale, representation needs, or multimodality
Heuristic: if you can’t beat a strong XGBoost baseline, the bottleneck is usually data/labels/features or evaluation mismatch.
Multi-stage architectures are standard at scale
- cheap model filters many candidates
- expensive model re-ranks top-N This improves latency/cost while maintaining quality.
Heuristic: use multi-stage whenever candidate set is large and p99 matters.
Specialized formulations show up in real data
- ranking (pointwise/pairwise/listwise)
- censored outcomes (survival-ish problems)
- multi-label classification
- mixture-of-experts / segment models for heterogeneous populations
5) Evaluation lessons (offline ≠ online)
A) Golden sets + changing sets
Strong orgs evaluate on:
- fixed golden dataset (detect regressions over time)
- rolling test set (matches current reality)
B) Backtesting and ecosystem effects
- replay historical traffic to estimate system-level effects and interactions
- handle network effects with specialized experiments (e.g., switchbacks)
C) “Label-free” health checks
When true labels are delayed/rare:
- monitor prediction score distributions over time to detect pathologies and drift
Heuristic: if labels arrive late, you still need early warning signals—distribution shift is one of the best.
6) Deployment & iteration lessons (how winners ship)
Online vs batch is a business decision
- online for strict latency/freshness
- batch for cost, simplicity, and stability
Safe rollout patterns repeat
- shadow mode to compare behavior safely
- A/B testing is the arbiter of “impact”
- control for latency effects (perf regressions can masquerade as “model got worse”)
Retraining is not one-size-fits-all
Cadences range from hourly → daily → weekly → monthly depending on drift and cost. A common pattern:
- retrain on last N days
- validate on golden + rolling sets
- publish snapshot only if it passes gates
7) The “hybrid systems” rule (ML + rules + humans)
This shows up again and again:
- rules for high-volume obvious cases / guardrails
- ML for nuance and scale
- HITL for ambiguity, cold start, QA, and continuous improvement
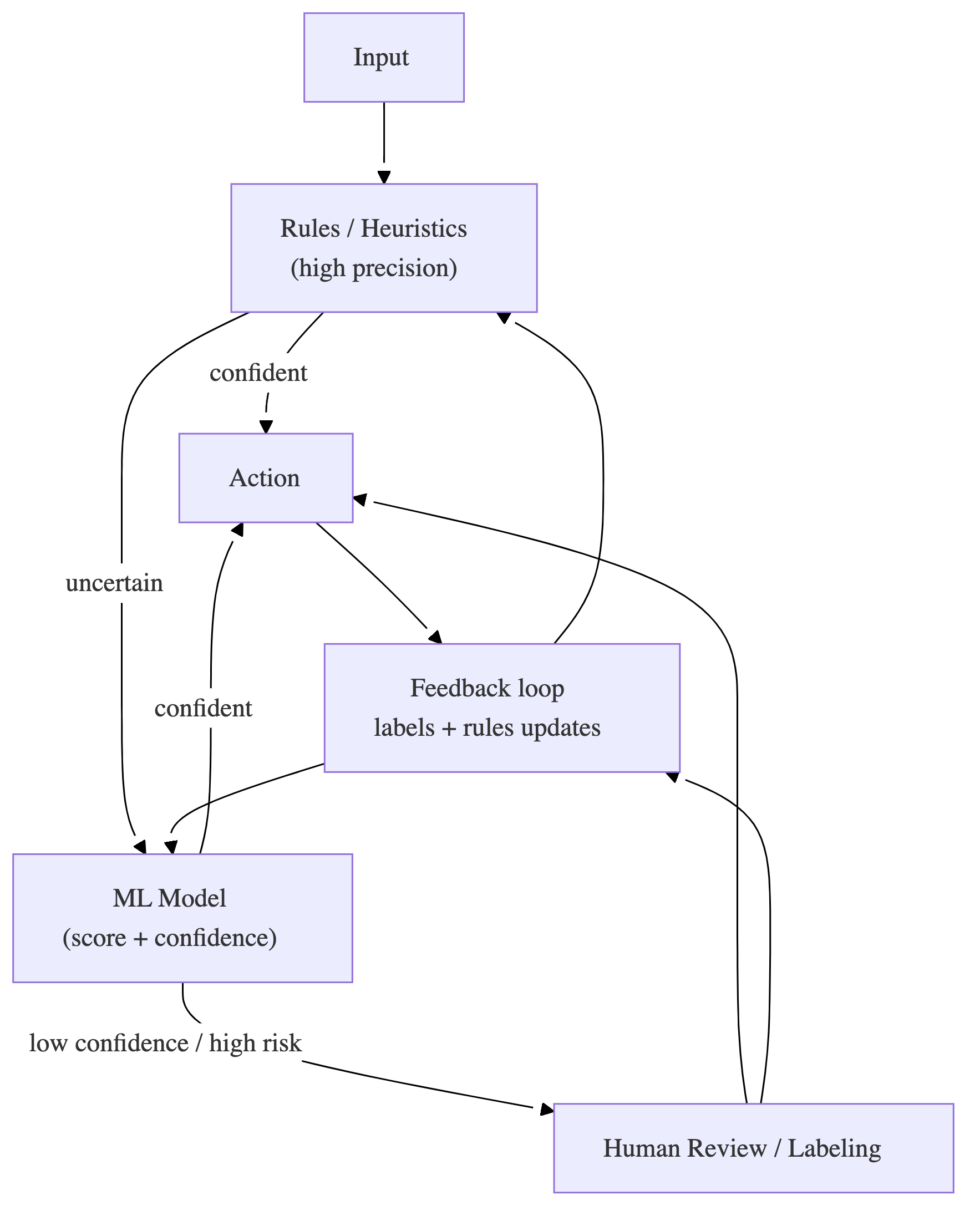
Heuristic: the best production system is often the one that fails gracefully (fallbacks) rather than the one with the highest offline metric.
8) Lead’s starter questions (use these to kick off any model project)
Problem & value
- What KPI moves, by how much, and what’s the TAM?
Data & labels
- What’s the data quality, bias/censoring risk, and labeling plan?
Modeling
- What’s the simplest baseline and the expected latency/cost limits?
Production
- Batch vs online? rollout strategy? monitoring signals? rollback plan?
Human loop
- Where do humans add leverage (labels, QA, exceptions, rules)?
“If you only remember 7 things”
- Offline metrics are a health check, not proof of value.
- Start simple; ship baseline; iterate with hypotheses.
- Labels/taxonomy are product design—invest early.
- Monitor coverage + freshness; build fallbacks.
- Multi-stage + hybrid (ML+rules+HITL) systems win at scale.
- Use golden + rolling evaluation; add label-free health checks.
- Retraining + rollout is the product—build the loop, not just the model.