Chapter 12.1: Continual Learning & Retraining
Implement closed-loop control systems for model retraining and continual learning
Continual Learning & Model Retraining
The core mental model
Models don’t “rot” because code breaks — they decay because the world changes. Continual learning is the closed-loop control system for ML:
Monitor → Detect shift/decay → Generate candidate → Test safely in prod → Promote/rollback → Log + learn → Repeat
Your north stars:
- TTD (time to detect) and TTR (time to recover)
- Value of freshness vs cost/risk (don’t retrain blindly)
1) Drift vocabulary you must keep straight
- Schema skew: inputs no longer match the expected schema.
- Distribution drift (covariate shift):
P(X)changes. - Concept drift:
P(Y|X)changes (inputs may look same; meaning changed). - Prediction drift:
P(ŷ)shifts (label-free early warning). - Training-serving skew: mismatch from day 1 (often engineering, not “drift”).
Rule: Fix data pipeline / skew before retraining. Otherwise you bake the bug into the next model.
2) Continual learning ≠ per-sample online learning
In industry, “continual learning” usually means micro-batch updates (not updating weights on every sample), because:
- per-sample updates can cause catastrophic forgetting
- batch hardware/infra is optimized for micro-batches, not per-event SGD
Heuristic: Start with daily/weekly micro-batch retraining and evolve only if you have strong evidence your domain needs faster.
3) The two retraining modes (this is the biggest decision)
| Mode | What it is | Pros | Cons | Best for |
|---|---|---|---|---|
| Stateless retraining | train from scratch on a larger window (e.g., last 3 months) | simplest mentally; robust to drift; resets accumulated mistakes | expensive; slow iteration; needs historical data | major changes: new features/arch/objective |
| Stateful training | fine-tune from the champion checkpoint using only fresh data | huge compute savings, faster convergence, adapts quickly; can reduce data retention needs | higher complexity; risk of forgetting; needs strong lineage + eval | “data iteration”: same arch/features, frequent refresh |
Rule: If you’re changing feature definitions or architecture, default to stateless. Use stateful for frequent refresh when the “shape of the model” is stable.
4) The 4-stage adoption journey (don’t skip stages)

Heuristic: Stage 2 is where most orgs should aim first (automation + governance). Stage 4 requires mature monitoring + strong evaluation discipline.
5) How often should you retrain? (Stop using gut feel)
The “value of freshness” experiment (simple + decisive)
Train multiple models on different recency windows and evaluate on the most recent data:
- Train on:
T-90d..T-1d,T-30d..T-1d,T-7d..T-1d(or similar) - Evaluate on:
T..T+Δ(the closest proxy to prod)
Plot quality vs recency window → that curve tells you whether daily retraining is worth it.
Rule: Retraining cadence should be justified by measured marginal gain per unit cost/risk.
6) Triggers: schedule vs event-driven (what to choose)
Common trigger types
- Time-based: daily/weekly (best starting point)
- Volume-based: when enough new labeled data accumulates
- Performance-based: metric drops below threshold (needs reliable labels)
- Drift-based: large sustained shift in inputs/outputs (label-free possible)
Default path: time-based → add volume-based → then performance/drift-based once your monitoring is stable and low-noise.
7) The evaluation & safety playbook (the only thing that makes CL safe)
Frequent updates increase failure opportunities; your safety system must scale with update frequency.
Offline gates (fast + automated)
- schema/DQ checks (freshness, null spikes, range, cardinality)
- golden set regression + slice floors
- calibration checks (if probabilities drive actions)
- skew checks (train vs serve parity / “next-day” tests)
Test-in-production techniques (choose by risk & feedback loop)
| Technique | Safest? | Needs user feedback? | Cost | Best for |
|---|---|---|---|---|
| Shadow | ✅✅✅ | ❌ | high (double compute) | critical systems sanity checks |
| Canary | ✅✅ | sometimes | medium | progressive exposure + rollback |
| A/B test | ✅ | ✅ | medium | measuring KPI impact |
| Interleaving (ranking) | ✅✅ | ✅ | high | recsys/ranking with position bias |
| Bandits | ✅✅ (self-correcting) | ✅ | complex | fast feedback, high opportunity cost |
Rule: If the system is high-criticality, start with shadow → canary → A/B.
8) Training-serving skew: the highest ROI fixes
These are the production “cheat codes”:
- Log features at serving time and feed them to training (strongest skew reducer)
- maximize code reuse across training and serving transforms
- snapshot slowly changing lookup tables used for features
- evaluate on future data (collected after training cutoff)
- measure skew explicitly: train vs holdout vs next-day vs live
Heuristic: If offline metrics look great but online is bad, assume skew or data issues first—not “the model got worse.”
9) Catastrophic forgetting (stateful training’s main risk)
If you fine-tune continually, you need guardrails:
- replay buffers (mix a small sample of older data into each update)
- regularization techniques (e.g., constrain important weights)
- periodic stateless refresh (hybrid approach: “reset occasionally”)
- slice floors on older-but-still-important cohorts
Rule: Never promote a stateful update without regression protection on “core historical behaviors.”
10) Continual learning pipeline blueprint (champion → challenger → promotion)
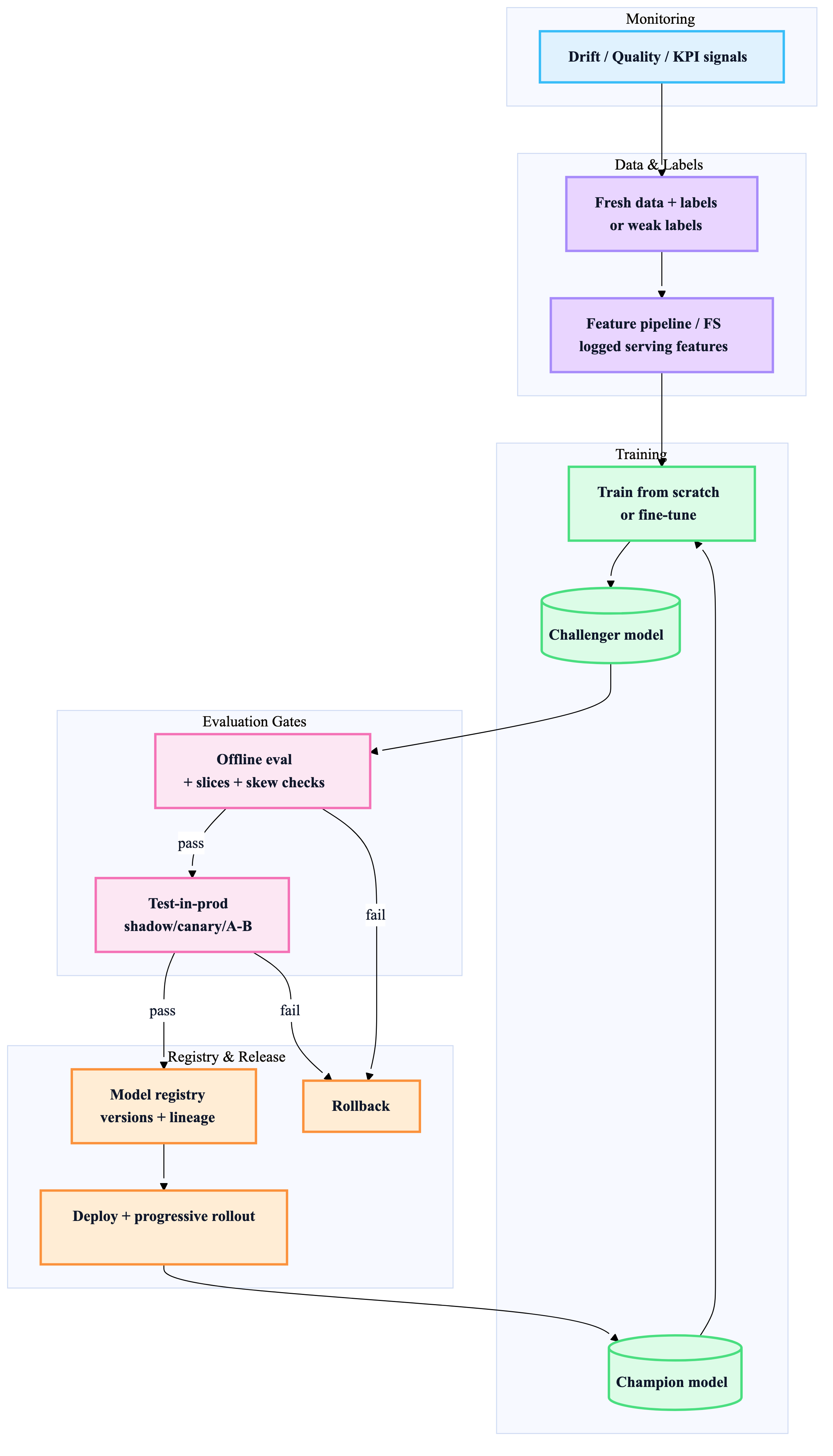
11) Lead’s decision checklist (use in reviews)
Cadence
- Have we measured value of freshness, or are we guessing?
Mode
- Are we doing data iteration (stateful ok) or model iteration (stateless)?
Safety
- What are the automated offline gates + slice floors?
- Which test-in-prod method matches our risk?
Skew
- Are we logging serving-time features and using them for training?
- Do we have parity/skew monitors?
Lineage
- Can we answer: “What data + code produced this model?” in 2 minutes?
Rollback
- Is rollback tested and fast (minutes), not theoretical?
“If you only implement 7 things”
- Stage 2 automation: scheduled retraining + model registry + metadata
- Value-of-freshness experiments to set cadence
- Strong offline gates (DQ + golden + slices + skew checks)
- Shadow/canary for safe rollout
- Serving-time feature logging (“log and wait”)
- Lineage tracking for checkpoints/data used (esp. stateful)
- Periodic stateless refresh or replay buffer to avoid forgetting