Chapter 5.2: Real-Time & Streaming Pipelines
Handle real-time ML with fresh features, low-latency retrieval, and SLA discipline
Real-Time & Streaming Data Pipelines — Challenges + Solutions
The core mental model
Real-time ML isn't "streaming because it's cool." It's fresh features + low-latency retrieval + SLA discipline. The hard parts are:
- stateful stream processing (correctness + cost)
- online serving (tail latency under spike)
- consistency (training/serving skew + backfills)
1) The “why real-time” bar (only do it when it clears this threshold)
Real-time is justified when…
- the environment changes faster than your batch refresh (fraud, session recos, pricing, ETA, anomaly detection)
- feature delay meaningfully degrades model performance (e.g., rapid ROC-AUC decay with stale features)
- users/items are frequently “new” (cold start) and need in-session adaptation
The best “compromise” most teams start with
Online inference + batch features + a thin real-time layer (e.g., recent actions, session stats), then iterate toward fully online features only where needed.
2) SLA-first design (what you must define upfront)
For real-time pipelines, define and monitor these as first-class SLAs:
- Feature freshness: event → available-to-serve latency (seconds)
- Serving latency: p95/p99 for
get_features(ms) - Availability: uptime target (99.9–99.99%+)
- Correctness: duplication bounds, ordering guarantees, late-event policy
- Data quality: schema validity, null spikes, distribution anomalies
Heuristic: If you can’t measure freshness end-to-end, you don’t have real-time—just “fast uncertainty.”
3) Challenge → solution map (what breaks, what fixes it)
A) Stateful streaming is hard
Symptoms
- OOM crashes, RocksDB state blowups, hot-key skew
- unstable latency, long recoveries, checkpoint stalls
Solutions
- design state intentionally (keys, TTLs, window sizes)
- mitigate skew: salting, partial aggregations, shard hot keys
- tune watermarks + checkpoint intervals (trade recovery time vs overhead)
- choose a state backend that matches scale (embedded vs externalized)
Heuristic: every windowed aggregation is a state liability. Treat it like owning a database.
B) Fresh feature retrieval at low latency is hard
Symptoms
- ingestion spikes cause serving p99 regressions
- “write-heavy” workloads starve reads
- multi-key fetches for recommenders blow up tail latency
Solutions
-
decouple ingestion and serving (separate compute paths; avoid shared hot storage contention)
-
pick online store by access pattern:
- point lookups → Redis/DynamoDB/Cassandra-style KV
- recent-actions query + analytics-ish slicing → Pinot-like stores
-
cache carefully; batch fetch APIs; cap candidate counts; prefetch where possible
Heuristic: online store choice is mostly about tail latency under fanout (not just median latency).
C) SLAs at scale are hard
Symptoms
- thousands of streaming jobs each needing bespoke tuning
- alert fatigue; inconsistent SLO adherence
Solutions
- multi-tenancy isolation (resource quotas, per-job runtime isolation)
- standardized templates (SQL/YAML-based declarative pipelines)
- per-job dashboards with standardized SLA panels (freshness/lag/errors/state size)
D) Training/serving skew is hard
Common causes
- time travel (late data makes training “see the future”)
- different transformation logic in batch vs stream
- drift (production distributions diverge)
Solutions
- single-source feature definitions (same code/DSL compiles to offline + online)
- point-in-time correct training dataset generation
- “log and wait” / log computed features during serving to reuse for training
- parity canaries: compare online feature values vs offline recompute
Heuristic: skew debugging cost grows superlinearly with the number of independent transformation codepaths.
E) Backfills are hard
Why
- stream retention is limited (days/weeks)
- new features need history; bug fixes need reprocessing
Solutions
- maintain an offline mirror of raw events (lake/warehouse)
- design replay/backfill paths from offline source + forward-fill from stream
- support rewind/replay and source switching where feasible
Rule: a real-time system without a backfill story is a temporary system.
4) The 3-stage evolution path (use this to avoid over-building)
| Stage | What you do | When it’s enough | Biggest risk |
|---|---|---|---|
| 1) Batch predictions | precompute all | slow-changing domains | stale personalization |
| 2) Online inference + batch features | real-time inference with mostly offline features | most teams start here | limited in-session adaptation |
| 3) Online inference + online features | streaming features + on-demand features | high-frequency domains | complexity explosion |
Practical guidance: stage 2 + a small set of streaming features gets you most ROI, fastest.
5) Architecture blueprint (streaming features → online store → inference)
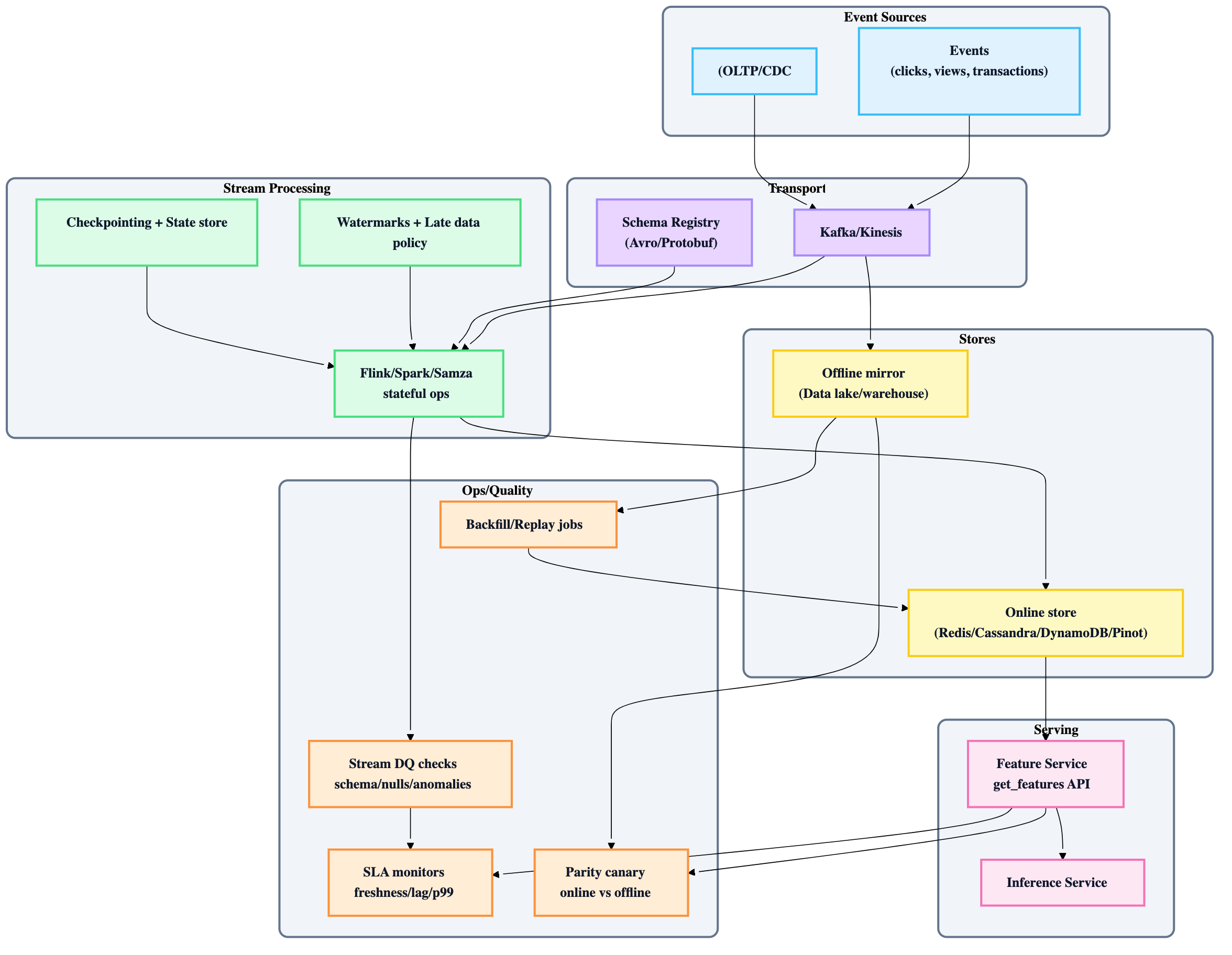
6) Key design choices (with defaults)
A) Streaming engine choice (how to decide)
Pick based on:
- stateful processing maturity + ops tooling
- SQL support / DSL ergonomics
- checkpoint/state backend robustness
- team familiarity and oncall capacity
Default heuristic: prefer the engine your org can operate at 3am.
B) Online store choice (how to decide)
Pick based on access patterns:
- KV point reads + TTLs + high QPS → Redis/Dynamo/Cassandra
- recent activity query patterns → Pinot-like
- need managed simplicity → managed KV where possible
C) Feature computation modes (don’t force everything into streaming)
- Batch features: stable aggregates, long windows
- Streaming features: near-real-time incremental updates
- On-demand features: require request-time context (computed inside inference path)
Rule: streaming is not mandatory for every feature. Use it where freshness matters.
7) The “tiled time-window aggregation” pattern (the scalable answer for long windows)
When you need long-window aggregates with high freshness:
- write recent projected events continuously
- compact into tiles (e.g., 5-min/1-hour aggregates) periodically
- serve by combining relevant tiles + head/tail raw events at request time
- use same structure offline for point-in-time correct training data
Why it works: avoids unbounded state in streaming jobs and makes backfills feasible.
8) Testing & releases for streaming systems (minimum viable discipline)
Tests (in order of ROI)
- unit tests for transforms (pure functions / SQL logic)
- integration tests with mocked sources/sinks
- staging E2E with replayed production-like streams
- performance/load tests (spikes + hot keys)
- data parity canary (online vs offline recompute)
Deployment rules
- progressive rollout for pipeline changes (canary/blue-green for jobs)
- rollback plan: previous job version + checkpoint recovery + data correction path
- avoid “definition drift” (feature definitions are versioned and promoted)
9) Lead’s operational checklist (copy/paste)
- ✅ freshness SLA defined and measured end-to-end
- ✅ late events + duplicates policy documented
- ✅ schema registry + evolution rules in place
- ✅ idempotent writes + dedupe strategy
- ✅ state sizing, hot-key strategy, and checkpointing policy
- ✅ online store isolated from ingestion contention
- ✅ backfill/replay from offline mirror exists
- ✅ parity canaries for skew
- ✅ dashboards: lag, freshness, p99, state size, DQ violations
- ✅ oncall runbooks for common failures (OOM, lag, schema break, store throttling)