Chapter 5.1: Data Engineering & Pipelines
Build production-grade data pipelines with correctness, freshness, and trust as core requirements
Data Engineering & Pipelines
The one-line mental model
Data pipelines are production software systems whose “correctness” includes freshness, completeness, and trust—not just successful job runs.
1) The Data Engineering Lifecycle (cradle → grave)
Think of every pipeline as moving through these stages:
- Generation (source systems)
- Storage (raw + curated)
- Ingestion (batch/stream/CDC)
- Transformation (ETL/ELT, modeling, featurization)
- Serving (BI/ML/ops consumers)
Heuristic: Most outages happen at the interfaces between stages (schema, time semantics, ownership), not inside the compute engine.
2) Requirements-first: the “Why before How” checklist
Before picking tools, lock these down:
- Consumers + SLA: who uses it? p95 freshness? uptime?
- Latency need: batch vs micro-batch vs streaming
- Correctness model: event-time vs processing-time semantics
- Data volume & skew: peaks, growth, partitions
- Failure tolerance: RTO/RPO, replay needs
- Security: PII classes, access boundaries, retention/deletion
Rule: if you don’t have SLAs and “time semantics,” you will ship a pipeline that “runs” but produces wrong answers.
3) Choose ingestion pattern (Batch vs CDC vs Stream)
| Pattern | When to use | Strengths | Traps |
|---|---|---|---|
| Batch | daily/hourly OK | simplest ops | late data/backfills painful |
| CDC | need DB changes reliably | accurate change capture | schema evolution + ordering |
| Streaming | near-real-time features/dashboards | freshness | idempotency, late events, observability burden |
Push vs Pull
- Pull (crawlers, polling): quick bootstrap, but brittle at scale.
- Push (events/metadata): fresher, scalable, requires producer discipline.
Default: hybrid: pull to bootstrap, push for steady-state.
4) Storage & formats: pick for cost + compute efficiency
Two-layer storage is the default
- Raw: immutable source-native payloads (audit + replay)
- Curated: typed, deduped, analytics/ML-ready tables
Format heuristics
- Parquet/ORC for curated (columnar, compression, predicate pushdown)
- Avro/Protobuf for event streams (schema evolution + compact)
- Arrow in-memory where performance matters (interop)
Rule: never “fix” raw by overwriting. Fix by producing a new curated version.
5) Transformation: ETL vs ELT and modeling choices
ETL vs ELT
- ELT (warehouse-centric) wins in cloud when compute is cheap and SQL is dominant.
- ETL is needed when: heavy parsing, complex enrichment, stream processing.
Data modeling choices (pick intentionally)
- Dimensional (Kimball/star): BI-friendly, stable metrics
- Normalized (Inmon): consistency, less duplication
- Wide denormalized tables: ML convenience, but risk of inconsistency
Heuristic: Don’t “optimize for ML” by making everything wide—use a semantic/metrics layer or controlled marts.
6) Cross-cutting concerns (where production wins/losses happen)
A) Data quality (DQ): shift-left, automate, and version
Minimum DQ checks:
- schema/type validation
- null-rate thresholds
- range/enum validity
- uniqueness / dedupe
- referential integrity (where applicable)
- volume/freshness checks
Heuristic: convert EDA findings into DQ tests; otherwise EDA is a one-time ritual.
B) Idempotency: the non-negotiable reliability property
Your pipeline must tolerate retries without corruption.
Patterns:
- deterministic keys (event_id / source PK + timestamp)
- upserts with versioning
- exactly-once behavior via idempotent writes + dedupe tables
- DLQs for poison messages/records
C) Time semantics (most teams get this wrong)
Track three times:
- event time (when it happened)
- ingestion time (when you received it)
- processing time (when you transformed it)
Rule: correctness for most analytics/ML features should be based on event time with clear late-arrival handling.
D) Observability is non-negotiable
Monitor:
- pipeline health (success/failure, duration, retries)
- freshness/lag
- volume anomalies
- DQ failures by rule
- cost metrics (compute, storage, egress)
Heuristic: if you can’t answer “what changed?” during an incident, you don’t have observability—you have logs.
E) Security & privacy by design
- least privilege + role separation
- encryption at rest/in transit
- PII detection + masking/tokenization
- retention + deletion workflows (GDPR/CCPA-like constraints)
7) Orchestration (DAGs) that don’t melt in real life
Orchestrators coordinate dependencies and backfills.
Practical rules
- make backfills a first-class operation (not a hack)
- use idempotent tasks so reruns are safe
- separate compute from orchestration (orchestrator triggers, engines compute)
- treat DAG definitions as code with CI tests
8) Architecture principles that keep pipelines evolvable
From the chapter’s “lead thinking framework”:
- Modularity & loose coupling: components replaceable
- Plan for failure: retries, DLQs, partial failures, replay
- Reversible decisions: avoid lock-in without an escape plan
- FinOps: monitor cost like latency—continuously
- Incremental delivery: ship MVP pipeline, then harden
Anti-pattern: “resume-driven data stacks” that maximize tools, not outcomes.
9) A reference pipeline blueprint (batch + streaming compatible)
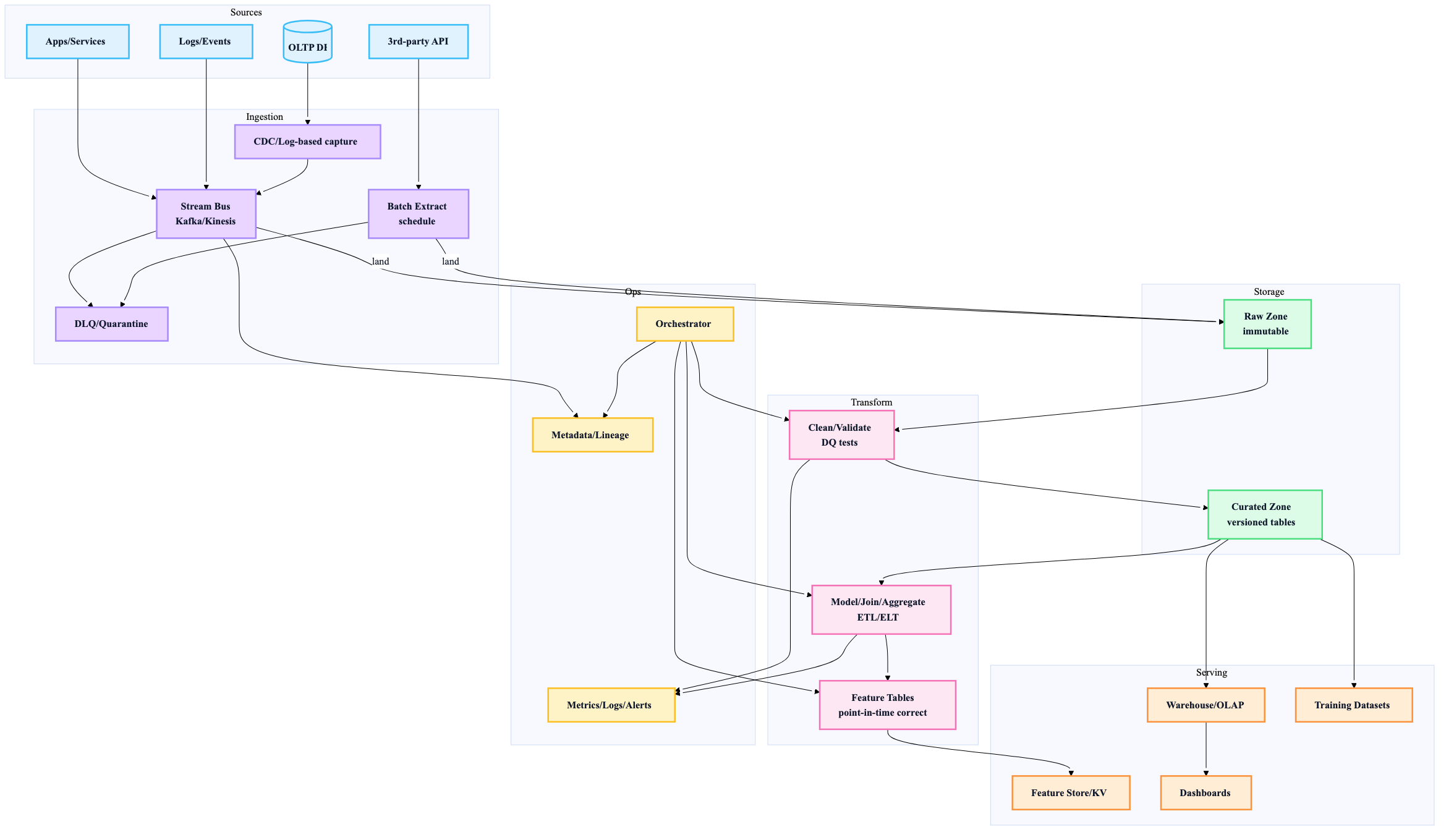
10) Decision table: pick tools like a lead (not a hobbyist)
| Decision | Default | Choose alternative when… |
|---|---|---|
| Batch vs streaming | Batch | product requires minutes-level freshness |
| ETL vs ELT | ELT | heavy parsing/enrichment or streaming transforms |
| OSS vs managed | Managed | you have strong infra team + unique needs |
| Monolith vs modular | Modular | integration cost becomes the bottleneck |
| “Schema on write” | Yes for curated/events | exploratory raw ingestion is needed temporarily |
11) “Done” criteria for a production pipeline
A pipeline isn’t production-ready until:
- ✅ data contract / schema versioning exists
- ✅ idempotent processing + safe retries
- ✅ DLQ/quarantine path exists
- ✅ DQ tests are automated + alerting wired
- ✅ backfill/replay procedure exists
- ✅ lineage/metadata recorded
- ✅ cost + freshness dashboards exist
- ✅ clear ownership + oncall/runbook