Chapter 7.1: Model Development
Transform experiments into production-ready model candidates through systematic development
Model Development (From Experiments → Production-Ready Candidates)
The core mental model
Model development is a closed-loop engineering discipline:
- define success (one metric + constraints)
- build a baseline fast
- iterate via diagnostics (bias/variance/mismatch)
- prove robustness (slices, invariances, calibration)
- produce a deployable, reproducible candidate (artifact + metadata + gates)
1) Define success like a lead (one metric + constraints)
A) Single-number metric (move fast)
Pick one optimizing metric you will improve (AUC/F1/MAE/logloss/etc.).
If multiple things matter, don’t average chaos—use:
B) Optimizing vs satisficing metrics (production reality)
- Optimizing metric: accuracy/quality objective
- Satisficing metrics: “must meet” constraints
Examples:
p99 latency < 200ms,model size < 50MB,fairness gap < X,cost/request < $Y
Rule: define thresholds before you run big experiments. Anything failing satisficing metrics is rejected even if it “wins” offline.
2) Dataset strategy (dev/test sets are product decisions)
The non-negotiables
- Dev and test must match the distribution you care about in production.
- Dev and test should come from the same distribution.
- Compute preprocessing statistics only on train, apply to dev/test (avoid leakage).
The “eyeball vs blackbox” split (high leverage)
- Eyeball dev set: small slice you manually inspect for error analysis
- Blackbox dev set: untouched slice used for model selection/HPO
Heuristic: if you do manual analysis on your tuning set, you’ve effectively overfit it.
3) Baselines are mandatory (or you don’t know if you’re winning)
Baselines to include (choose what fits):
- zero-rule / mean predictor
- simple heuristic
- current production system
- human-level performance (when applicable)
Rule: if your “fancy model” doesn’t beat the baseline reliably, stop and debug the pipeline/data/labels.
4) The iterative loop (what to standardize early)
Standard evaluation routine (framework-agnostic)
A reproducible “evaluate()” should output:
- optimizing metric + satisficing metrics
- slice metrics (critical subgroups)
- calibration stats (if probabilities drive decisions)
- latency/throughput/cost (or at least estimates)
Track every experiment (no exceptions)
Store:
- code version (commit)
- data version (snapshot id)
- feature set version
- hyperparameters + random seeds
- training curves + system metrics
- sample predictions
Heuristic: if you can’t reproduce your best run in < 30 minutes, you’re not doing production model development.
5) Debugging via diagnostics (stop guessing)
Use this decision loop to prioritize work:
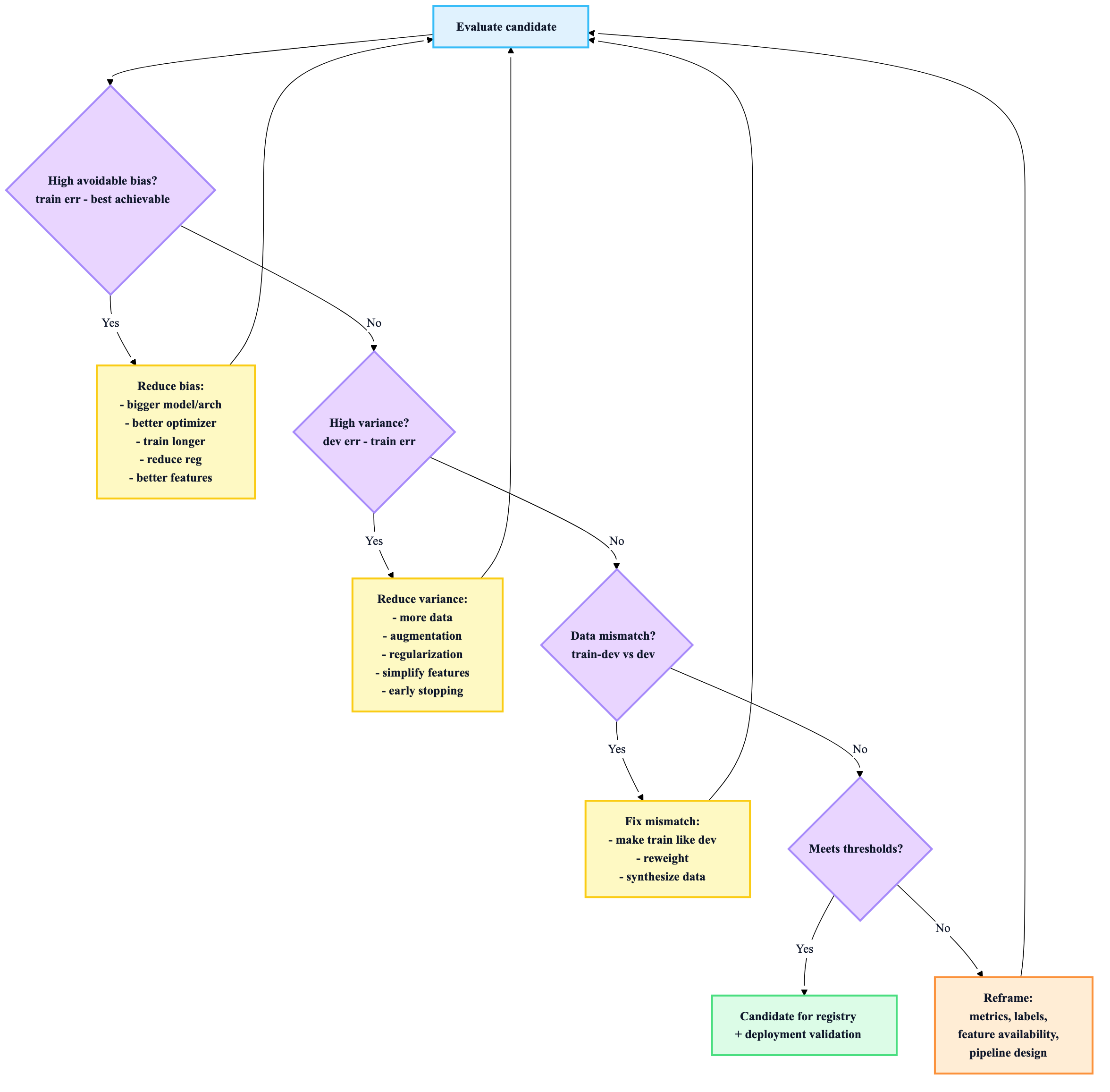
Learning curves (quick “will more data help?” test)
- low train error + big gap to dev → variance → more data helps
- high train error and dev close → bias → more data won’t fix much
Sanity checks that catch many bugs
- Overfit one small batch: if you can’t drive loss near zero on tiny data, suspect bugs.
- check NaNs/Inf in loss/weights; inspect gradient norms (NNs)
- verify consistency between training & serving scoring code paths
6) Error analysis (turn mistakes into roadmap)
Do manual review on ~100 mispredictions from eyeball dev set:
- categorize error types (blur, label noise, rare class, OOD, etc.)
- quantify % in each category
- prioritize fixes by “% of total error” × “fix cost”
Rule: if you can’t name your top 3 error slices, you’re flying blind.
7) Training-serving skew (the silent killer) — prevention patterns
Best practices (in order of leverage):
- Log serving-time features and feed them back to training
- Reuse transform code between training and serving (shared library/feature store)
- Guard against join-table drift (slowly changing dimensions, time travel)
- Measure skew explicitly (offline vs next-day vs live)
Heuristic: “Works offline but fails online” is often skew or mismatch, not model choice.
8) Offline evaluation beyond a single metric (robustness toolkit)
Slice-based evaluation
Always report metrics for critical slices (segments, rare cases). This prevents Simpson’s paradox “wins”.
Robustness tests
- Perturbation tests: add noise, corruptions, missing fields
- Invariance tests: changes that shouldn’t change output (e.g., synonym swap)
- Directional expectation tests: changes that should change output (e.g., bigger house → higher price)
Calibration (when scores drive decisions)
If you threshold probabilities, ensure predicted probabilities reflect true likelihoods:
- reliability diagrams / ECE
- Platt scaling / isotonic regression (fit on validation only)
Rule: uncalibrated probabilities lead to bad thresholds and broken business policies.
9) Advanced moves (use only when justified)
Ensembles
- often help, but serving complexity grows fast
- keep ensembles simple (avoid nested ensembles)
Transfer learning
- small data → feature extraction or partial fine-tuning
- similar domain + more data → fine-tune deeper
Distributed training
Use when model/data scale forces it; plan for:
- communication overhead
- stragglers
- batch size effects
AutoML/HPT
Use when:
- the project matters enough
- hyperparameters are sensitive
- you can afford compute and want reproducible search
Heuristic: automate once you’ve stabilized the evaluation routine and data splits—otherwise you just scale confusion.
10) Production readiness checklist for a “model candidate”
A model is a deployable candidate only if:
- ✅ optimizing metric improved vs baseline on blackbox dev
- ✅ satisficing metrics meet thresholds (latency/size/cost/fairness constraints)
- ✅ slice metrics are acceptable (no hidden regressions)
- ✅ calibration validated (if probabilities used for actions)
- ✅ feature availability confirmed at serving time
- ✅ skew risk addressed (shared transforms / feature logging / parity checks)
- ✅ reproducibility: code+data+params+env recorded
- ✅ artifacts packaged: model + preprocessing + schema + signature
- ✅ rollback plan exists (champion/challenger)