Chapter 9: Inference Optimization
Comprehensive guide to optimizing LLM inference covering latency (TTFT/TPOT), throughput, cost reduction, KV cache fundamentals, quantization, attention optimizations, and service-level optimization strategies.
Inference Optimization (Latency + Throughput + Cost)
The mental model
Inference optimization is a 3-layer game: Model × Service × Hardware. And for autoregressive LLMs you’re optimizing two different systems:
- Prefill (TTFT): compute-bound (parallelizable)
- Decode (TPOT): memory-bandwidth-bound (sequential)
If you don’t separate these, you’ll “optimize” the wrong thing.
1) What to optimize: the metrics that matter to CTOs
The 4 metrics that decide success
- TTFT (Time to First Token) → perceived responsiveness
- TPOT / ITL (Time per Output Token) → streaming speed
- Throughput (Tokens/sec) → cost driver
- Goodput = requests/sec that meet SLOs (prevents “throughput wins” that ruin UX)
Heuristic: Optimize for goodput, not raw TPS. That’s how you avoid “it’s fast but unusable.”
2) Foundational bottleneck: the KV cache (the silent GPU killer)
Why KV cache dominates
-
KV cache prevents recompute during decoding, but it grows with:
- batch size
- sequence length
- layers × hidden size
- precision
KV Cache size:
2 * batch_size * seq_len * num_layers * hidden_size * sizeof(dtype)
Heuristic: Most “why is my 70B slow/expensive?” problems are really KV cache pressure problems.
3) The optimization ladder (highest ROI first)
Start here (most teams get 70% of wins)
- Use a modern inference server (vLLM/TGI/TRT-LLM)
- Continuous batching (keep GPU busy under concurrency)
- KV cache efficiency (PagedAttention-like memory management)
- Quantization (INT8/INT4) to reduce bandwidth pressure
Then escalate to: 5) Fused attention kernels (FlashAttention) (esp. long context) 6) Prompt/prefix caching (reduce TTFT for repeated prefixes) 7) Speculative decoding (lower TPOT/latency; adds complexity) 8) Parallelism (tensor/pipeline) if model doesn’t fit on one GPU
4) Map symptoms → fixes (the table you’ll actually use)
| Symptom | Likely root cause | Primary fixes | Trade-off |
|---|---|---|---|
| High TTFT (slow to start) | long prompt prefill | Prompt caching, reduce prompt length, FlashAttention | cache memory + infra complexity |
| High TPOT (slow streaming) | decode bandwidth bound | Quantization, speculative decoding, MQA/GQA models | quality risk + complexity |
| High GPU bill / low TPS | poor utilization | Continuous batching, PagedAttention, raise batch size carefully | latency vs throughput tradeoff |
| Model doesn’t fit | weights + KV exceed VRAM | quantize, tensor parallelism | comm overhead, engineering time |
| RAG slow + costly | long context & repeated prefixes | prompt caching + compression + batching | caching correctness + invalidation effort |
Heuristic: If TTFT is bad, don’t waste time on decode tricks. If TPOT is bad, caching won’t save you.
5) Model-level optimizations (change the model)
Quantization (low-hanging fruit)
-
PTQ: fast, no retraining (risk: accuracy loss with naïve PTQ on LLMs)
-
QAT: more accurate but requires training
-
Transformer quantization is tricky due to activation outliers; methods like:
- SmoothQuant (shift difficulty from activations to weights)
- GPTQ (layer-wise PTQ using second-order info)
- mixed precision approaches (keep outliers in FP16)
CTO heuristic: Quantize first, then re-run your app eval suite (Chapter 6). If business metrics don’t degrade, it’s free money.
Pruning & sparsity
- Unstructured sparsity often doesn’t speed up without specialized kernels.
- Structured / N:M sparsity can be hardware-accelerated (e.g., 2:4) but increases complexity.
Distillation
- Train a smaller model to mimic a teacher’s outputs (“dark knowledge”).
- High ROI when you need to serve huge volume at low cost.
6) Attention/KV architecture optimizations (reduce cache pain)
MHA vs MQA vs GQA
- MQA: shared K/V across heads → smallest KV cache, fastest decode (possible quality drop)
- GQA: compromise: groups share K/V (near-MHA quality, smaller cache)
- Many large models adopt GQA (e.g., Llama 2 70B)
PagedAttention (vLLM-style KV memory paging)
-
KV cache stored in fixed-size blocks → reduces fragmentation
-
Enables:
- much larger effective batch sizes
- prefix sharing (copy-on-write)
Heuristic: If you serve high concurrency, PagedAttention + continuous batching is the “default modern stack.”
FlashAttention (fused kernel)
- Minimize HBM reads/writes by fusing operations and using SRAM tiling.
- Big wins for long context.
7) Break the autoregressive bottleneck (advanced)
Speculative decoding
- Draft model proposes k tokens; target model verifies in parallel.
- Speedup depends on acceptance rate.
When to use: you’ve already implemented batching + KV optimizations, and TPOT is still limiting UX.
Parallel decoding (e.g., Medusa-like)
- Multiple decoding heads predict future tokens; verify via tree-style selection.
- Higher complexity; emerging but powerful.
8) Service-level optimization (how you schedule + serve)
Continuous batching (state-of-the-art)
- Keeps the batch full by swapping in new requests as old ones finish.
- Delivers major throughput gains under real traffic.
Parallelism (when you must scale across GPUs)
- Tensor parallelism: split matrices within a layer (good latency; needs fast interconnect)
- Pipeline parallelism: split layers across GPUs (fits big models; more latency/bubbles)
- Sequence parallelism: partition along sequence dim to reduce activation memory
Prompt/prefix caching
- Cache KV for shared prefixes (system prompts, long instructions, repeated contexts).
- Reduces TTFT and cost.
Heuristic: In enterprise assistants, prompt caching is often the single biggest TTFT win.
9) A practical decision flowchart (use this in architecture reviews)
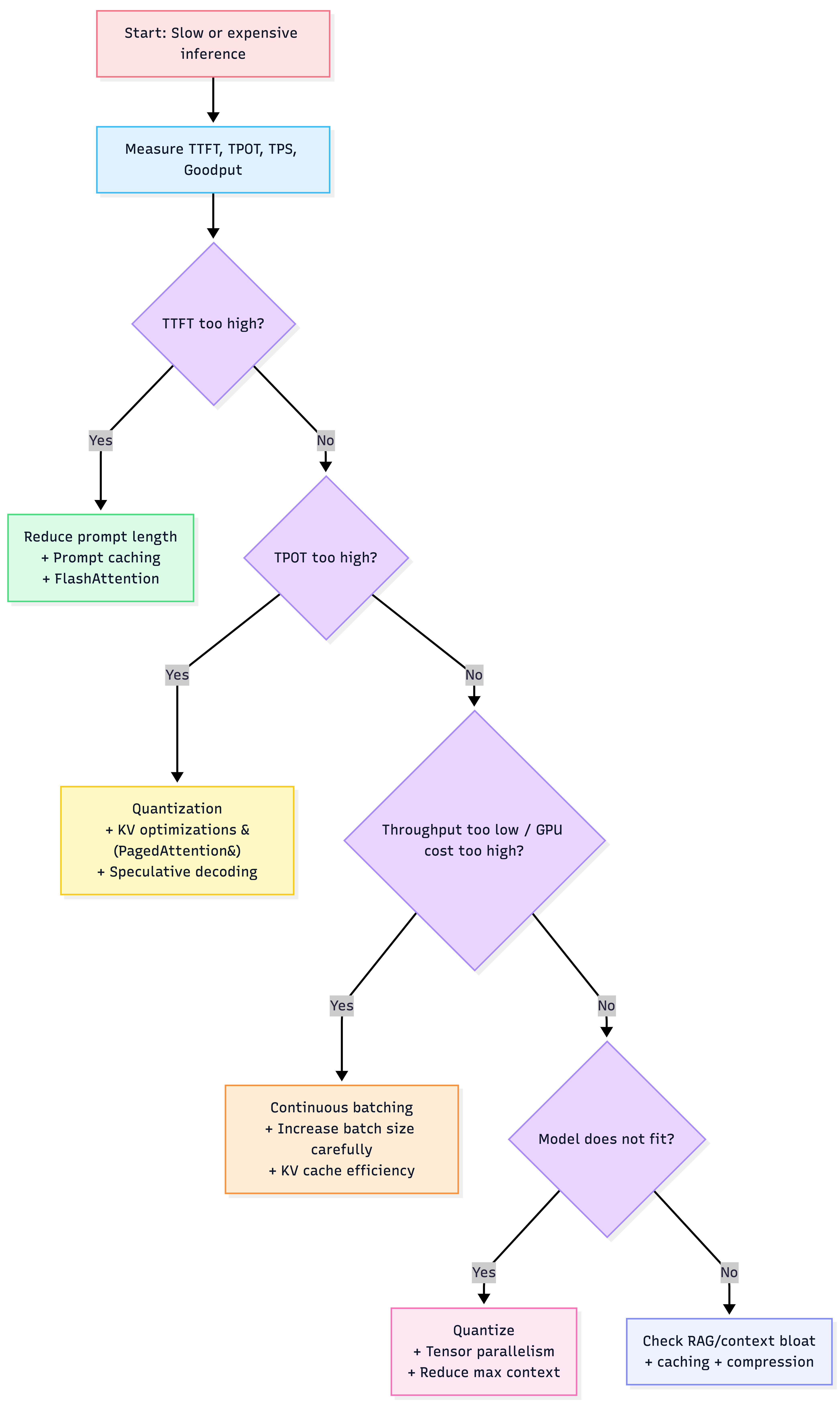
10) AWS-first “default stack” for optimized serving (practical)
MVP (fastest to ship)
- Managed model API (e.g., Bedrock/SageMaker endpoint)
- Focus on routing + caching + context reduction
- Track TTFT/TPOT + cost per successful task
Self-hosted (performance-first)
- EKS or ECS GPU + vLLM (or TGI / TRT-LLM)
- Prometheus/Grafana + CloudWatch for infra metrics
- Explicit SLOs: TTFT, TPOT, goodput, error budget
- Canary rollouts + fallbacks
Heuristic: Self-hosting only wins if you can keep GPUs highly utilized and you’ve done the above optimizations.
“If you remember 8 things”
- Prefill ≠ decode. Measure TTFT and TPOT separately.
- KV cache drives memory pressure and cost.
- Optimize for goodput, not raw TPS.
- Biggest wins: continuous batching + KV paging + quantization.
- FlashAttention helps long contexts; caching helps repeated prefixes.
- Speculative decoding is an “advanced lever” after the basics.
- Parallelism is a tax—pay it only when the model doesn’t fit.
- Every optimization must be validated with your app eval suite (quality regressions are common).