Chapter 6: Evaluating Production GenAI Apps
Comprehensive evaluation framework covering the eval flywheel (design/pre-prod/post-prod phases), evaluation methods, RAG metrics, CI/CD for LLMs, and LLM-as-a-judge techniques.
Evaluating Production GenAI Apps (Evals Flywheel)
The mental model
LLMs aren’t deterministic software → “unit tests” aren’t enough. Production GenAI requires an evaluation system that continuously turns failures into measurable test cases. This eval flywheel is the #1 difference between “cool demo” and “reliable product.”
1) What you’re evaluating: Model vs System (don’t confuse these)
- LLM eval = academic benchmarks (MMLU, etc.) → measures general model capability.
- LLM system eval = your app end-to-end (prompt + RAG + tools + guardrails + data) → measures your product reliability.
Heuristic: A model leaderboard score does not predict your RAG chatbot performance. Build your own benchmarks.
2) The Eval Flywheel: 3 phases you must run
A) Design phase: “in-app” real-time correction
Goal: cheaply catch common failures during runtime (fast assertions + one retry).
Examples:
- Codegen: import check → execute → if error, loop once with traceback.
- RAG: grade retrieval relevance → generate → grade faithfulness → retry/regenerate if needed.
B) Pre-production: offline eval + regression tests
Goal: benchmark changes before shipping; prevent regressions. Start small: 50–100 high-quality examples is enough to begin.
C) Post-production: online eval + monitoring
Goal: score live traffic (reference-free), capture real failures, and bootstrap them back into the offline dataset.
The eval flywheel

3) Evaluation methods: pick the right tool for the job
| Method | Best for | Pros | Cons |
|---|---|---|---|
| Human eval | nuanced/subjective quality | gold standard | slow, costly, inconsistent |
| Code/heuristic eval | format/schema/invariants | fast, cheap, deterministic | rigid, misses nuance |
| LLM-as-a-judge | scalable nuanced scoring | flexible, automatable | judge bias/flakiness; needs calibration |
Heuristic: Use humans to define quality; use automation to enforce it repeatedly.
4) Pre-prod dataset: how to build it fast (without boiling the ocean)
Data sources
- Manually curated (domain experts) → best to start
- App logs → most realistic
- Synthetic → expand coverage and edge cases
Synthetic generation that doesn’t suck (practical recipe)
- chunk docs
- build context (similar chunks)
- generate query from context
- “evolve” query to add complexity (Evol-Instruct)
- generate expected output based only on context
Heuristics
- Synthetic data is best for coverage gaps, not replacing real data.
- Always keep a human-curated “golden core”.
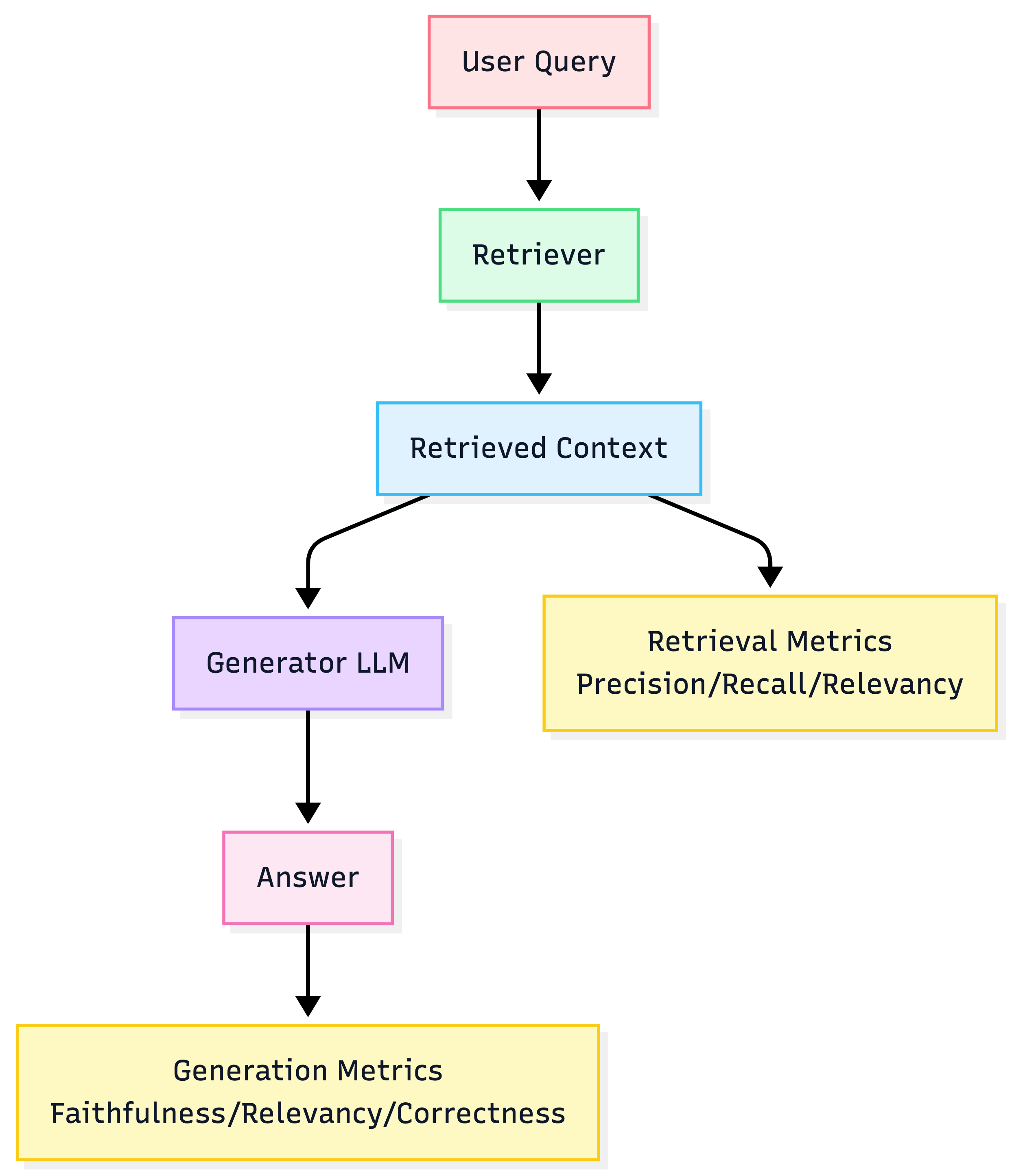
5) Metrics that matter (especially for RAG)
Retrieval metrics
- Contextual Precision: retrieved docs that are relevant (penalizes noise)
- Contextual Recall: did you retrieve all necessary docs (penalizes missing info)
- Contextual Relevancy: overall relevance of context to query
Generation metrics
- Faithfulness: grounded in retrieved context (anti-hallucination)
- Answer Relevancy: answers the question
- Answer Correctness: aligns with expected output (when you have reference)
Note on BLEU/ROUGE: fast but often poorly correlated with humans for open-ended text. Use cautiously.
RAG evaluation map
6) CI/CD for LLM systems (how to keep it shippable)
Best practices
- Two-tier test suites: small critical subset on every PR; full suite nightly/for releases
- Cache LLM calls for unchanged inputs to cut cost
- Plan for flaky judges: human review queue for failures (don’t block merges forever)
Heuristic: Treat eval cost like cloud cost—budget it, optimize it, and put guardrails on it.
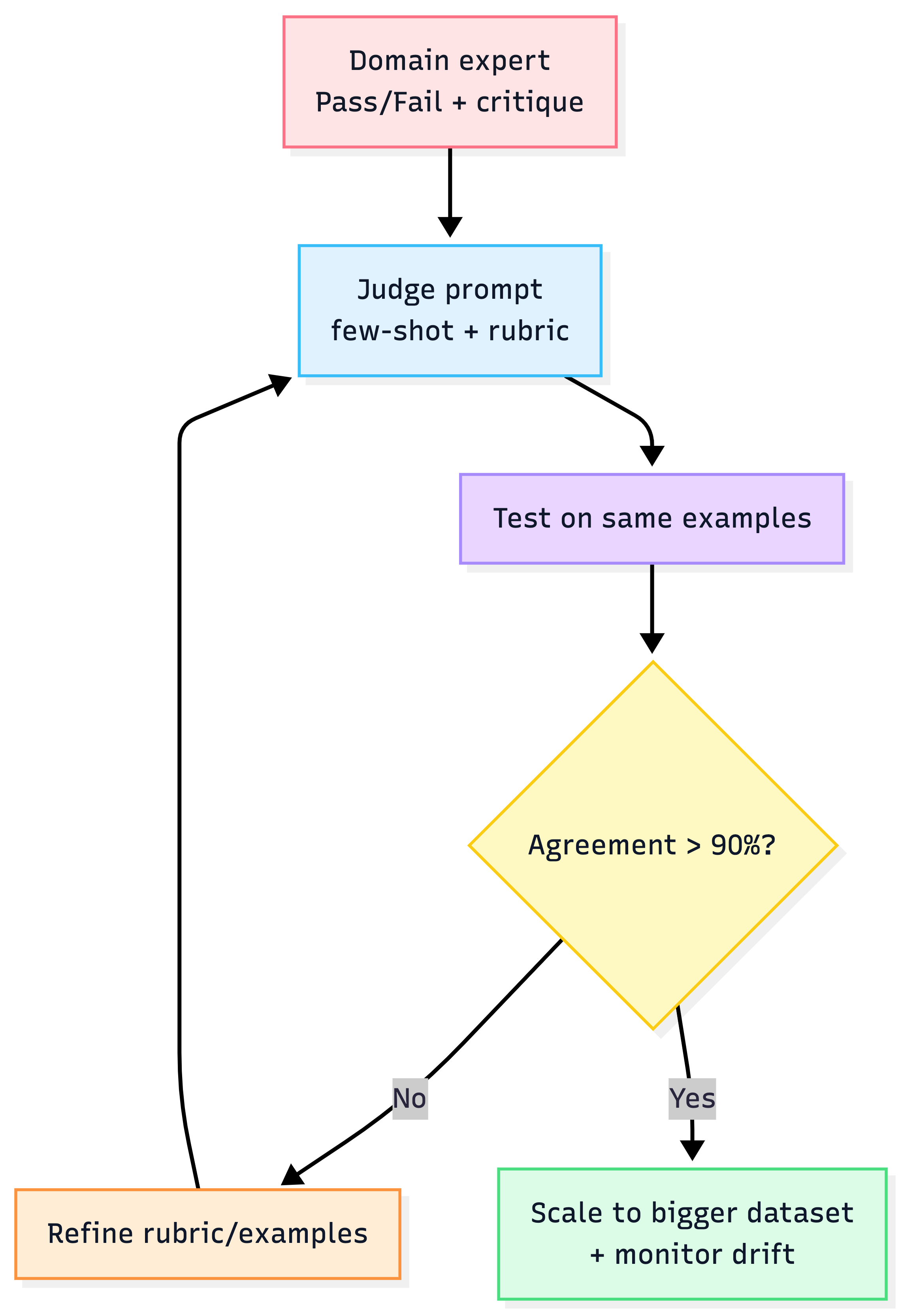
7) LLM-as-a-Judge: how to make it reliable (Critique Shadowing)
The most common failure mode is “rate 1–10” prompts that produce garbage. The fix is judge alignment with your domain expert.
Critique Shadowing process
- pick one principal domain expert (source of truth)
- collect 30–50 examples with pass/fail + critique
- build judge prompt with few-shot critiques
- iterate until >90% agreement with expert
- error analysis → reveals where your system needs work
Judge best practices
-
Start with binary Pass/Fail (more actionable than 1–10)
-
Use pairwise comparisons for subjective criteria (style/helpfulness)
-
Mitigate biases:
- positional bias → swap A/B order and rerun
- verbosity bias → instruct concision preference / normalize length
- self-enhancement bias → avoid judging with same model family if possible
-
Use a strong judge model even if your app model is cheaper
Judge calibration loop
8) Post-production: online eval + bootstrapping (where you actually win)
What to do in prod:
-
Tracing: log full lifecycle (input → retrieval → tool calls → output)
-
Feedback signals
- explicit: thumbs up/down
- implicit: immediate rephrase, abandon, copy-paste
-
Reference-free scoring using LLM judges (faithfulness, toxicity, relevancy)
-
Bootstrapping: convert failures into new offline test cases
Heuristic: Every incident is a gift—turn it into a regression test.
9) Tools landscape (what to pick when)
| Tool | Best for | Notes |
|---|---|---|
| LangSmith | tracing + datasets + evals | strong LangChain-native workflow |
| DeepEval | open-source eval + Pytest | good CI integration |
| RAGAS | RAG metrics | retrieval + generation metrics |
| Arize Phoenix | observability + eval | open-source stack |
| TruLens | tracing + feedback functions | lightweight option |
Default (AWS + LangChain): LangSmith for tracing/evals + RAGAS-style metrics where applicable.
10) Risk-adjusted quality bar (CTO sanity check)
Perfect eval is impossible; calibrate to risk:
- High-stakes (medical/finance/legal): very high bar for faithfulness + safety, human review, strict guardrails
- Low-stakes (internal summarization): tolerate higher error rate, rely on review workflows
Heuristic: Don’t chase perfection—chase a measured, improving system.
“Minimum viable eval stack” (what I’d ship first)
- A golden set (50–100) + regression suite
- RAG metrics (precision/recall/faithfulness) if retrieval exists
- LLM judge calibrated via critique shadowing
- Prod tracing + feedback + bootstrapping pipeline
- CI policy: critical subset per PR, full suite nightly