Chapter 4: Data + Models
Data-centric AI approach covering dataset engineering, data synthesis, model selection framework, and the escalation ladder from prompting to RAG to fine-tuning.
Data + Models (the real levers of production GenAI)
The mental model
Models are increasingly commoditized; data quality + system design is where you win. In production, performance is rarely limited by “not having the biggest model”—it’s limited by data quality, coverage, evaluation, and cost-aware design.
1) Data-centric AI: the moat you can actually build
Model-centric vs Data-centric (decision lens)
- Model-centric: improve performance by changing the model (bigger/better architecture, more compute).
- Data-centric: improve performance by improving the dataset (quality, coverage, labeling, synthesis).
Heuristic: If your roadmap is “switch to Model X”, you’re renting performance. If your roadmap is “build dataset + eval flywheel”, you’re building a moat.
2) Dataset Engineering: what matters (and what teams miss)
The 3 pillars: Quality, Coverage, Quantity
Your dataset is strong only if it has:
- Quality (correct, consistent, compliant)
- Coverage/Diversity (represents real usage)
- Quantity (enough to shift model behavior)
Quality (6 attributes you must enforce)
- Relevance to the task
- Alignment with task requirements (factual vs creative)
- Consistency across annotators
- Correct formatting
- Uniqueness (avoid duplicates/contamination)
- Compliance (PII/legal/policy)
Heuristics
- 100 high-quality examples can beat 100k noisy examples.
- Bad formatting is a silent model-killer (especially for SFT/fine-tune).
- Treat “compliance” as a first-class dataset dimension, not a review step.
Coverage/Diversity: mirror the real world
Include diversity across: task types, topics, instruction styles (JSON/short/long), user input styles (concise/verbose/typos).
Heuristic: Coverage should reflect production traffic distribution (not what’s easiest to collect).
Quantity: how much data do you need?
- Full fine-tuning: typically tens of thousands → millions examples.
- PEFT/LoRA: can work with hundreds → a few thousand examples.
- Better base model → fewer examples needed.
Pragmatic workflow
- Start with 50–100 carefully curated examples to validate that fine-tuning actually helps.
- If it helps, scaling data usually scales gains.
3) Data synthesis: powerful, but easy to shoot yourself with
Why use synthetic data
- Scale quantity, target coverage gaps, fix class imbalance
- Improve quality (sometimes better than humans on complex structured tasks)
- Privacy mitigation (sensitive domains)
- Distillation (teacher → student)
Risks
- Model collapse (training recursively on model outputs)
- Superficial imitation (style without real capability)
Heuristics
- Use synthetic data to cover missing edge cases, not to replace your real distribution.
- Always mix in real, outcome-labeled examples to anchor the dataset.
- Track provenance: human vs synthetic vs mixed.
4) Models: what engineers need to know (without the research rabbit hole)
Transformer dominance + attention
Transformers dominate because they process tokens in parallel via attention. (SSMs are emerging for long sequences, but production default remains transformers.)
Scaling: the 3 numbers that matter
- Parameters
- Tokens trained on
- FLOPs (training compute cost)
Scaling law heuristic (Chinchilla) Compute-optimal training often needs tokens ≈ 20× parameter count.
5) Post-training stack: why base models aren’t product-ready
Two-step alignment:
- SFT (instruction-following via high-quality instruction-response pairs)
- Preference tuning (e.g., RLHF: reward model + optimization)
Heuristic: When you complain “the model doesn’t follow instructions reliably,” you’re hitting limits of post-training or your prompt/output constraints—not pretraining.
6) Probabilistic outputs: use randomness intentionally
Probabilistic sampling causes:
- Inconsistency
- Hallucination
Knobs: temperature, top-k, top-p. (Production default: keep randomness low for extraction/structured tasks.)
Heuristic: Determinism comes from workflow constraints + validators, not from “better wording”.
7) Model selection framework (CTO-grade decision process)
Step 1: Closed API vs Open weights
| Option | Choose when | Costs/Risks |
|---|---|---|
| Closed API (Bedrock/OpenAI/Anthropic/Google) | fastest path to SOTA + low ops | vendor dependency, data governance constraints |
| Open-weight (Llama/Mistral/Qwen, etc.) | security/compliance + deep customization + control | serving/ops burden, tuning complexity |
Step 2: Reasoning model or not?
- Use reasoning-heavy models for planning/analysis.
- Don’t waste them on simple QA/summarization/extraction.
Step 3: Pick the “superpower” you actually need
- Accuracy (high-stakes)
- Speed/cost (real-time scale)
- Long context (doc synthesis)
- Multimodal (images/audio/video)
- Code-specialized
- Live web search (current events)
Step 4: Escalation ladder (avoid over-building)
- Prompting first
- RAG if knowledge is missing
- Advanced RAG (hybrid search, rerank)
- Custom evals to measure impact
- Fine-tune / distill if behavior/skill is the issue
Step 5: Workflows vs Agents
- Prefer orchestrated workflows for repeatable tasks.
- Use agents only for open-ended problems, with guardrails against runaway cost.
8) The “Prompt vs RAG vs Fine-tune” decision (repeatable and reliable)
Escalation + decision loop
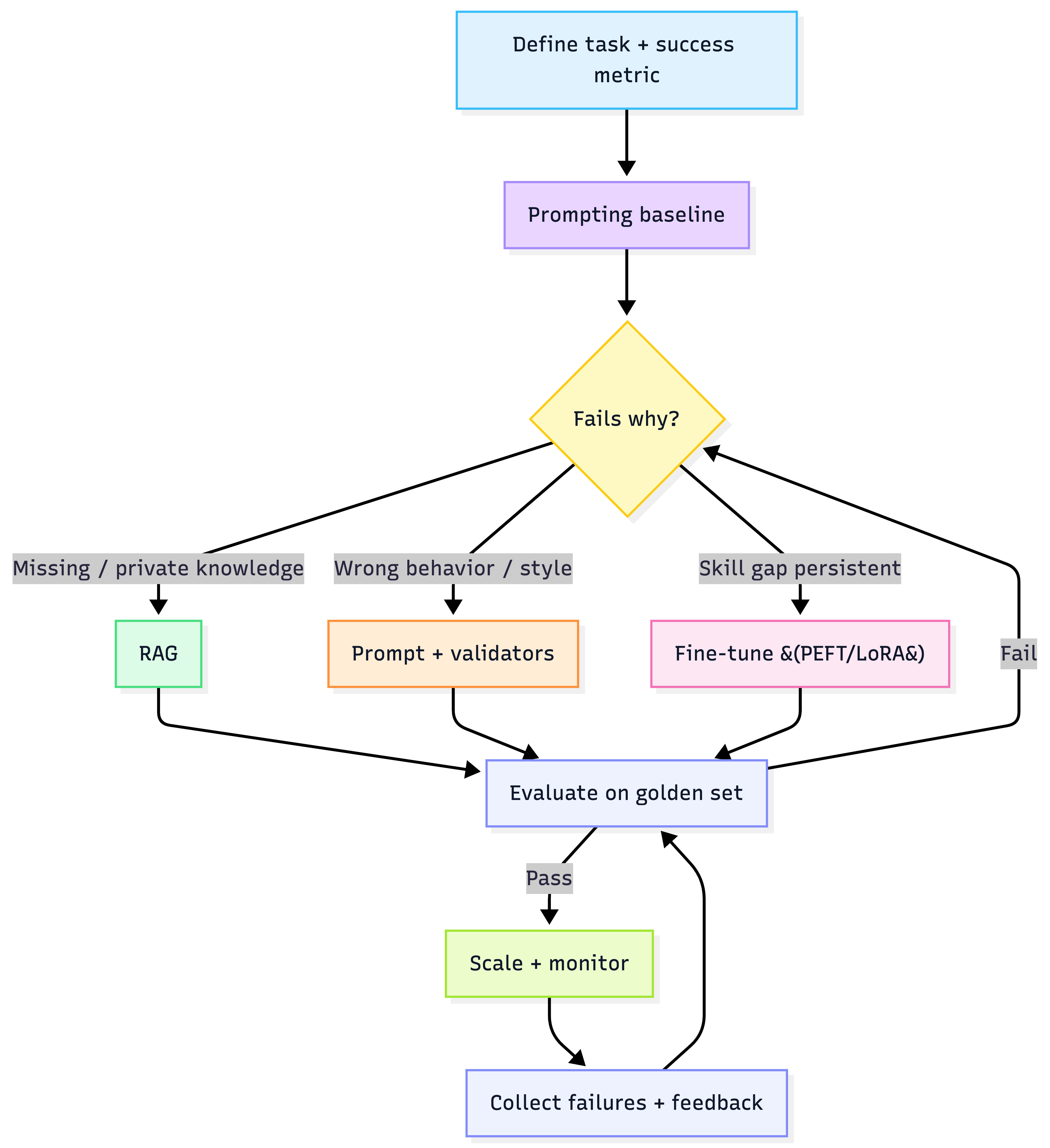
Heuristic: RAG fixes knowledge. Fine-tuning fixes behavior. Evals decide if you’re improving.
9) Production checklists (what a tech lead should enforce)
Dataset readiness checklist
- Quality: relevance, consistency, formatting, uniqueness, compliance
- Coverage: matches real traffic distribution
- Clear train/val/test split to avoid contamination
- Provenance tags (human vs synthetic) + policy docs
- A “golden set” of real failure cases
Model readiness checklist
- Model chosen for the right “superpower” (not hype)
- Cost model: cost per successful task
- Routing plan: cheap path vs strong path
- Guardrails plan: input/output + audit logs
- Eval harness: regression + offline scoring
10) Default recommendation (AWS + LangChain-friendly)
For most production teams:
- Start with a strong closed model (AWS Bedrock if AWS-first) to validate value fast.
- Build the data + eval flywheel early (this becomes your moat).
- Add RAG only when the problem is knowledge-grounding.
- Use PEFT fine-tuning when you have repeatable behavior gaps and at least a few hundred curated examples.