Chapter 5: Fine-Tuning LLMs
Comprehensive guide to fine-tuning LLMs covering PEFT vs full SFT, LoRA details, alignment strategies (SFT vs RLHF vs DPO), dataset requirements, and production workflow.
Fine-Tuning LLMs
The mental model
Fine-tuning is how you teach the model “how to behave,” not “what to know.” If the model is failing due to missing or changing facts → RAG. If it’s failing due to tone/format/style/domain behavior → fine-tune.
1) The escalation ladder (don’t fine-tune too early)
A pragmatic production sequence:
- Prompting (few-shot / structure / validators)
- RAG (if missing private/up-to-date info)
- Fine-tuning (behavioral adaptation; consistent format/style; domain style)
- Preference tuning (alignment to “what users prefer”)
"Should we fine-tune?" decision tree
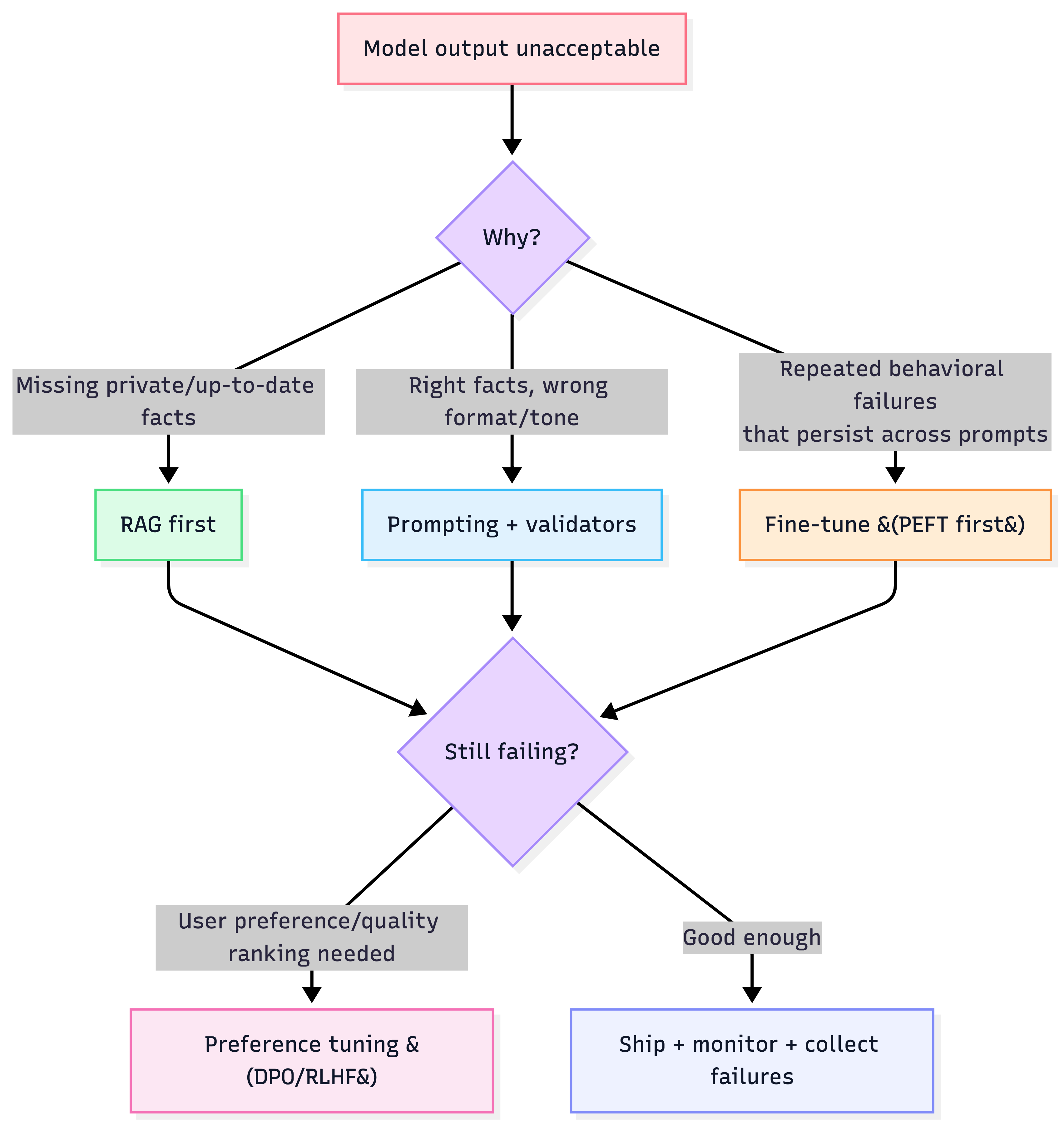
Heuristic: If your “fix” is mainly new knowledge, fine-tuning is usually the wrong tool.
2) Fine-tuning spectrum: Full SFT vs PEFT (default to PEFT)
Trade-off table (CTO-grade)
| Choice | What changes | Pros | Cons | When to choose |
|---|---|---|---|---|
| Full fine-tuning (SFT) | update all weights | max flexibility/performance | expensive, slow, risk of catastrophic forgetting, heavy deployment | only if PEFT can’t hit target + you can afford GPU/ops |
| PEFT (LoRA/Adapters/Prompt tuning) | train <1% params | cheap, fast, multi-task friendly, lower forgetting | can be sensitive to hyperparams; some methods add latency | default for most teams |
| QLoRA | LoRA + 4-bit base weights | enables big models on limited GPUs | slower training; quantization complexity | when compute/memory is tight |
Default recommendation: Start with PEFT → LoRA → QLoRA if needed.
3) PEFT cheat sheet (what actually matters)
LoRA (production favorite)
- Learns a low-rank update to weight matrices (train A & B).
- Key benefit: can be merged into base weights → no inference latency overhead.
Knobs (high-leverage)
- Rank (r): capacity vs params (typical 4–64).
- Alpha (α): update scaling; common heuristic: α ≈ 2r.
QLoRA (when GPU memory is the bottleneck)
- Quantize frozen base to 4-bit (NF4) + train LoRA adapters in higher precision.
- Adds tricks like double quantization and paged optimizers to fit large models.
Other PEFT options (use selectively)
- Adapters: strong, but may add inference latency.
- Prompt tuning / Prefix tuning: tiny params; can be less powerful than LoRA.
Heuristic: If you care about “no serving complexity surprises,” LoRA wins because merging is clean.
4) Alignment: SFT vs RLHF vs DPO (production lens)
What each stage solves
- SFT: teaches baseline “helpful assistant” behavior.
- RLHF: optimizes outputs using human preference signals via reward model + RL (powerful, complex/unstable/costly).
- DPO: simpler alternative that directly optimizes preferred vs dispreferred responses without reward model/RL.
Decision rule
- If you’re a small team: SFT + DPO is usually the sweet spot.
- RLHF is for orgs that can afford the pipeline complexity.
Alignment pipeline
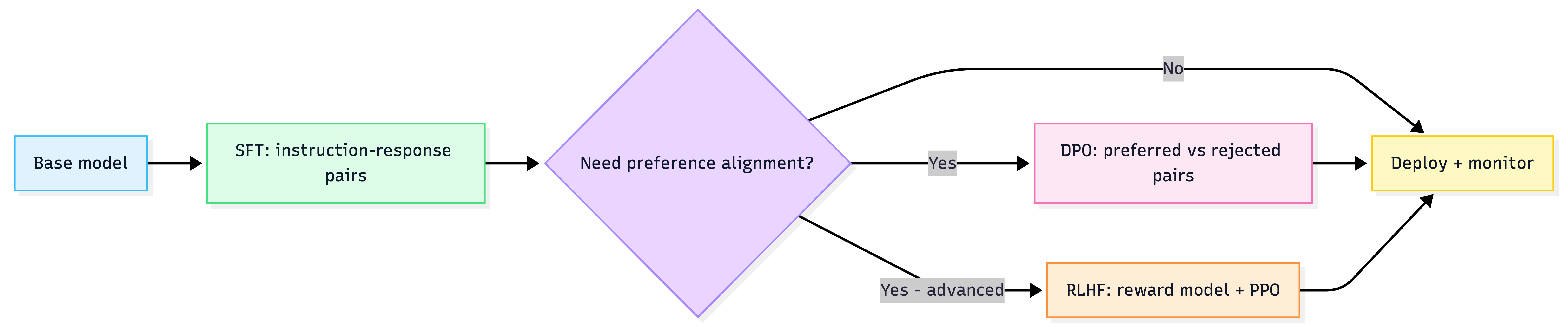
5) Data is the real bottleneck (dataset engineering rules)
Dataset requirements that actually move metrics
- High-quality instruction/response pairs (format consistency matters a lot).
- Coverage of real production inputs, including messy user text.
- A holdout eval set that mirrors production.
Heuristics
- Start with a small curated set to prove that fine-tuning helps before scaling.
- Watch for overfitting: multiple epochs can degrade instruction tuning; many teams start with ~1 epoch.
6) Synthetic data: use it, but don’t poison your model
Two common uses
- Distillation: big teacher (e.g., strong proprietary model) → generate training pairs → train smaller student.
- Self-improvement: model generates, critiques, filters, retrains (powerful but bounded by initial capability).
Risks
- “Model collapse” / feedback loops if you train too much on your own generations.
- Synthetic style without genuine correctness.
Heuristic: Synthetic is best to fill coverage gaps + edge cases, but keep real outcome-labeled data as the anchor.
7) Practical production workflow (end-to-end)
The 8-step fine-tuning playbook
- Define task + success metric (what changes after tuning?)
- Choose base model (fit for task + license + serving plan)
- Prepare dataset (format, compliance, splits)
- Pick strategy: PEFT/QLoRA first, full SFT last
- Set hyperparams (small LR, fit batch, consider 1 epoch)
- Train + validate (monitor loss + eval metrics)
- Evaluate (offline eval + human/LLM-judge as needed)
- Deploy with rollback + monitoring
Production fine-tuning loop
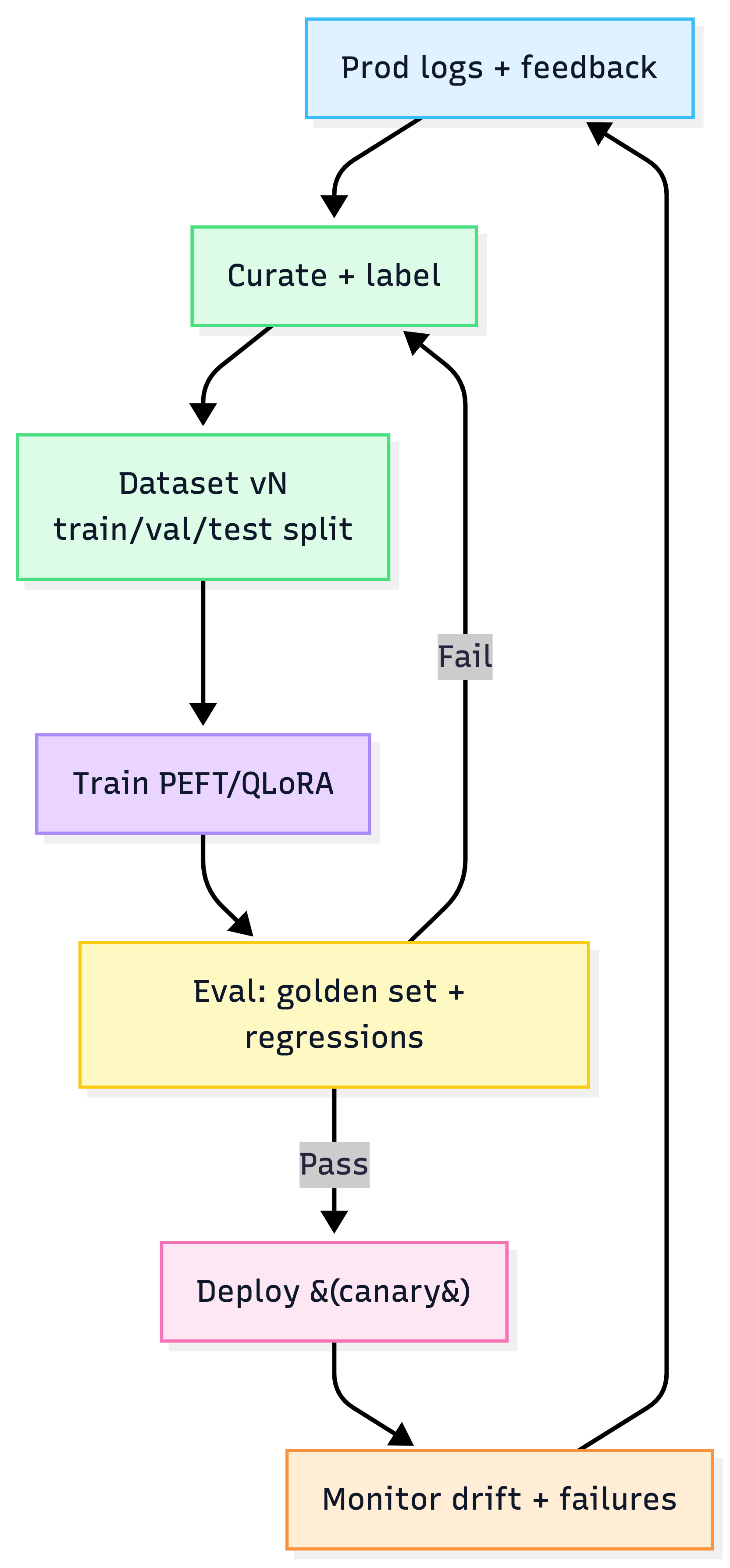
8) AWS-first reference implementation (defaults)
(Framework-agnostic; LangChain-friendly serving/orchestration)
Training plane
- Data in S3
- Training jobs on SageMaker (or ECS/Batch for custom)
- Experiment tracking via CloudWatch (+ your preferred tracker)
- Workflow orchestration via Step Functions
Serving plane
- Base model + merged adapters hosted on SageMaker endpoint (or ECS with vLLM)
- Route requests through your orchestrator (LangChain/LangGraph or custom)
- Monitor cost/latency + quality with centralized logging
Heuristic: Keep training artifacts + dataset versions immutable (S3 prefixes with hashes).
9) Failure modes & anti-patterns (what hurts teams)
- Fine-tuning to fix knowledge freshness (should be RAG).
- No eval harness → “it feels better” launches that regress silently.
- Training on messy/invalid formats → model learns the mess.
- Over-training (too many epochs) → reduced general capability / overfit.
- Shipping many task-specific full models → storage + deployment nightmare (PEFT solves this).
Default recommendation (for most CTOs/teams)
- Start with prompting + validators.
- Add RAG if failures are factual/knowledge-related.
- If behavior is the problem: LoRA PEFT, and merge adapters for serving.
- If you need preference alignment: DPO before RLHF (simpler, often effective).
- Build the dataset + eval flywheel — that’s your durable moat.