Chapter 7: Deployment & Serving
Production LLM infrastructure covering API vs self-hosting decisions, inference fundamentals (TTFT/TPOT), performance engineering, cost modeling, orchestration patterns, and three-horizon migration roadmap.
Deployment & Serving (From prototype to production LLM infra)
The mental model
Serving an LLM is a cost-and-latency business disguised as an ML problem. Your job is to maximize: tokens/sec/$ while meeting TTFT + TPOT SLOs and reliability.
1) The first strategic decision: API vs Self-hosting
CTO-grade trade-off table (the only one you need)
| Vector | API (OpenAI/Anthropic/Bedrock-like) | Self-host (open weights) |
|---|---|---|
| Unit economics | predictable OpEx, linear scaling | lower variable cost at scale, but pay for idle GPUs |
| Latency control | black box + network | full control: batching, kernels, routing |
| Customization | limited | deep: fine-tune + serving optimizations |
| Privacy/security | data leaves boundary (policy dependent) | keep data in VPC / controlled env |
| Ops complexity | low | high: GPUs, autoscaling, rollout, monitoring |
| Speed to market | fastest | slower initial setup |
Heuristics
- Start with API to validate value fast.
- Consider self-hosting when (a) data boundary demands it, (b) you need strict latency/throughput control, or (c) you’re at meaningful scale and can keep GPUs highly utilized.
Decision path: API vs self-hosting
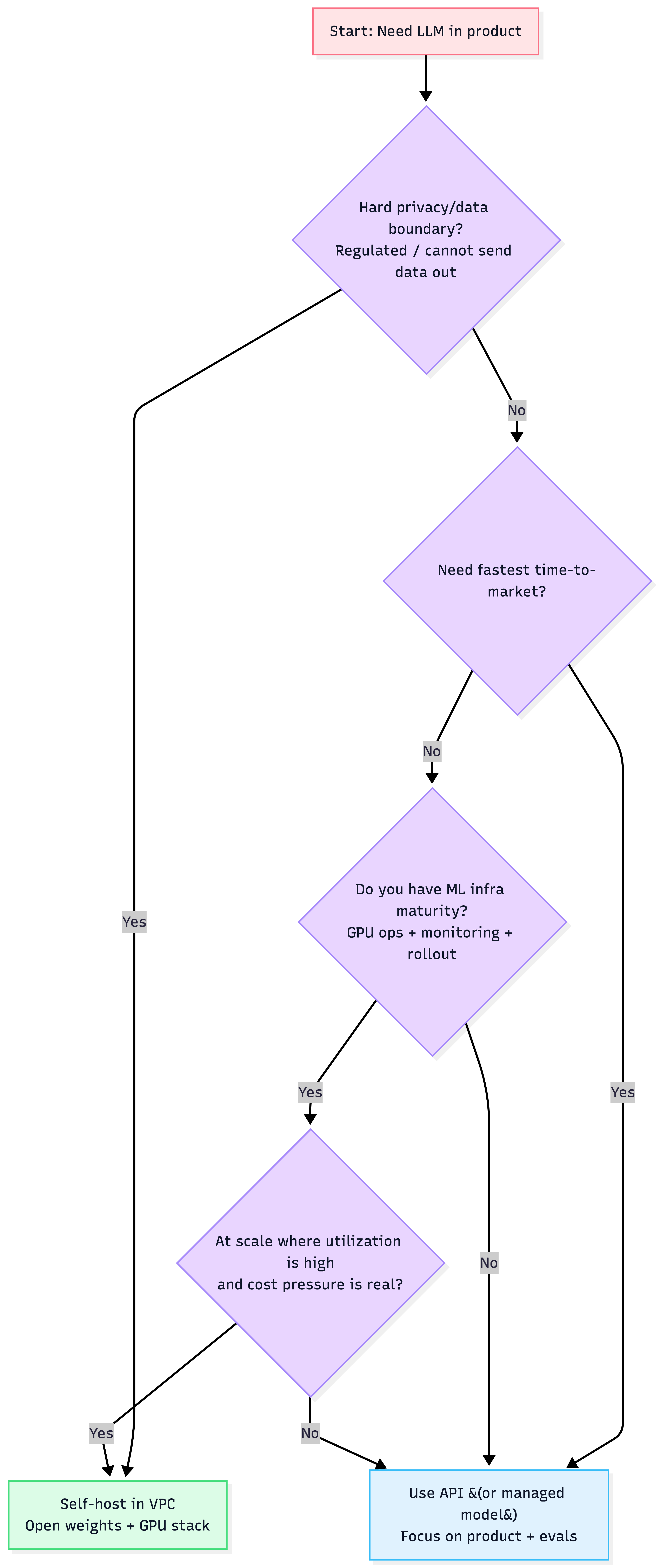
2) Inference fundamentals you must internalize
Two phases, two bottlenecks
- Prefill (prompt processing): parallel, typically compute-bound
- Decode (token generation): sequential, typically memory-bandwidth-bound
Metrics that matter (production)
- TTFT (time to first token): “feels responsive?”
- TPOT (time per output token): “streaming speed”
- Total latency =
TTFT + TPOT * (# output tokens) - Throughput: tokens/sec across all requests (primary efficiency metric)
Heuristic: Your product may be decode-heavy (chat) or prefill-heavy (summarization). Optimize accordingly.
Request lifecycle
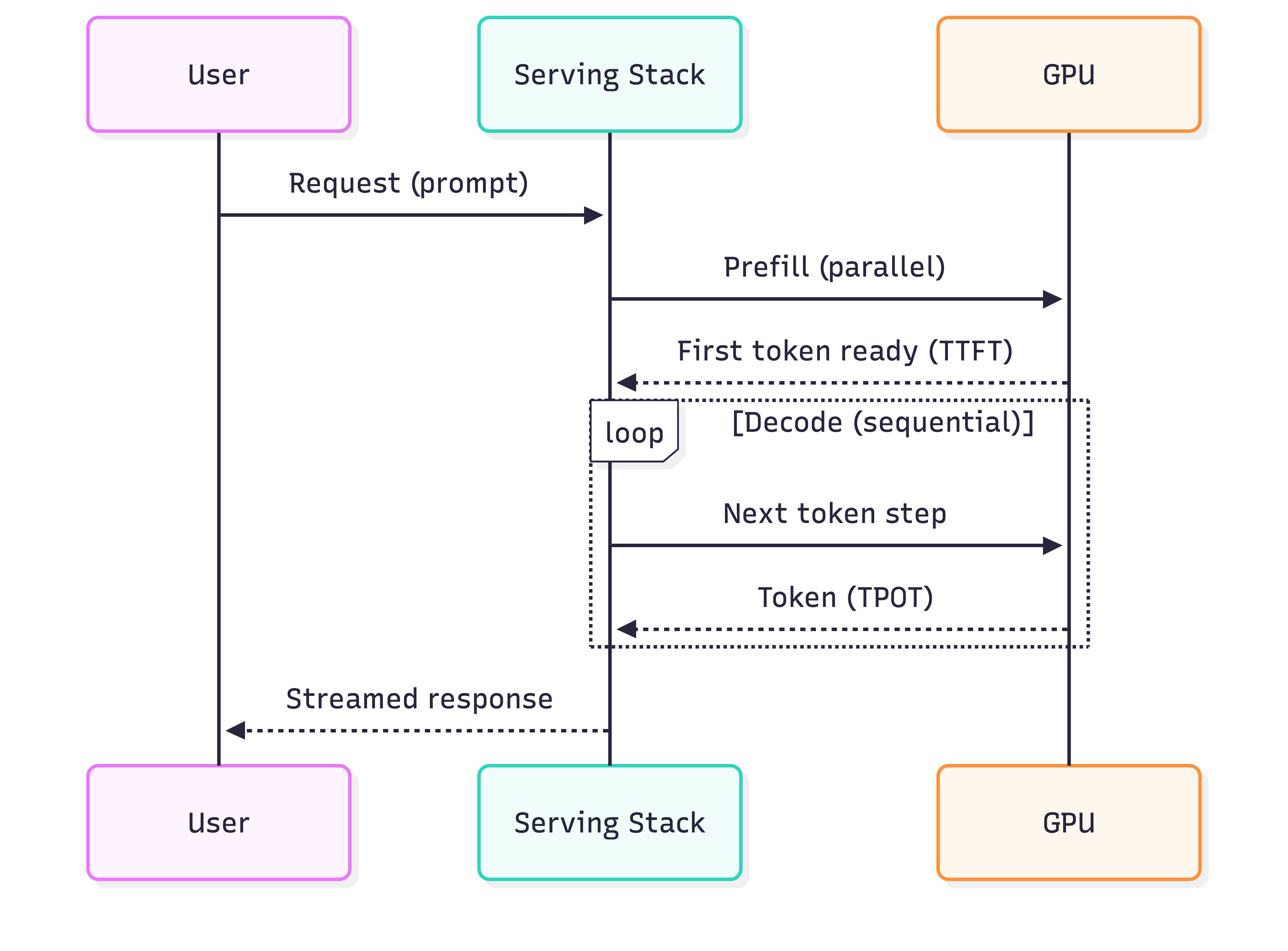
3) Performance engineering: what actually moves the needle
Primary bottleneck: memory bandwidth (most real-time serving)
Track:
- MBU (Model Bandwidth Utilization): how close you are to saturating VRAM bandwidth
- MFU (Model FLOPs Utilization): more relevant for compute-heavy prefill/large batches
Heuristic: If MBU is low, you likely have software/serving inefficiency (batching/KV-cache/paging), not “need a bigger GPU”.
The “serving optimization stack” (in order)
- Continuous batching (biggest throughput win under concurrency)
- KV-cache efficiency (PagedAttention-like approaches)
- Quantization (INT8/INT4) to reduce memory traffic
- FlashAttention / optimized kernels (long-context wins)
- Speculative decoding (latency wins; watch throughput trade-off)
- Tensor/Pipeline parallelism (when model doesn’t fit on one GPU)
Heuristic: Most teams should get 70% of wins from (1) batching + (2) KV cache + (3) quantization.
4) Cost modeling: avoid “success = bankruptcy”
API cost reality
- Costs scale linearly with usage (great for MVP, scary at scale)
- Output tokens often cost far more than input tokens
Self-hosting cost reality
- GPU is a fixed hourly cost → utilization determines unit economics
- You must budget VRAM for weights + KV cache (concurrency)
Heuristic: Self-hosting only “wins” financially when you can keep GPUs busy and your stack is optimized for high tokens/sec.
5) The modern self-hosted serving stack
Choose an inference engine (core performance layer)
| Engine | Strength | Best for |
|---|---|---|
| vLLM | throughput + KV cache efficiency (PagedAttention) | high-concurrency serving |
| HF TGI | production robustness + prefix caching + guided output | RAG/tool apps, long prompts |
| TensorRT-LLM (+ Triton) | maximum performance on NVIDIA via compilation/kernel fusion | ultra-low latency / enterprise perf |
Choose an orchestration layer
- Kubernetes + KServe: best if you already run K8s (autoscaling, canary, model mgmt)
- Ray Serve: Python-native “model composition” scaling (great for multi-model pipelines)
Serving stack layers
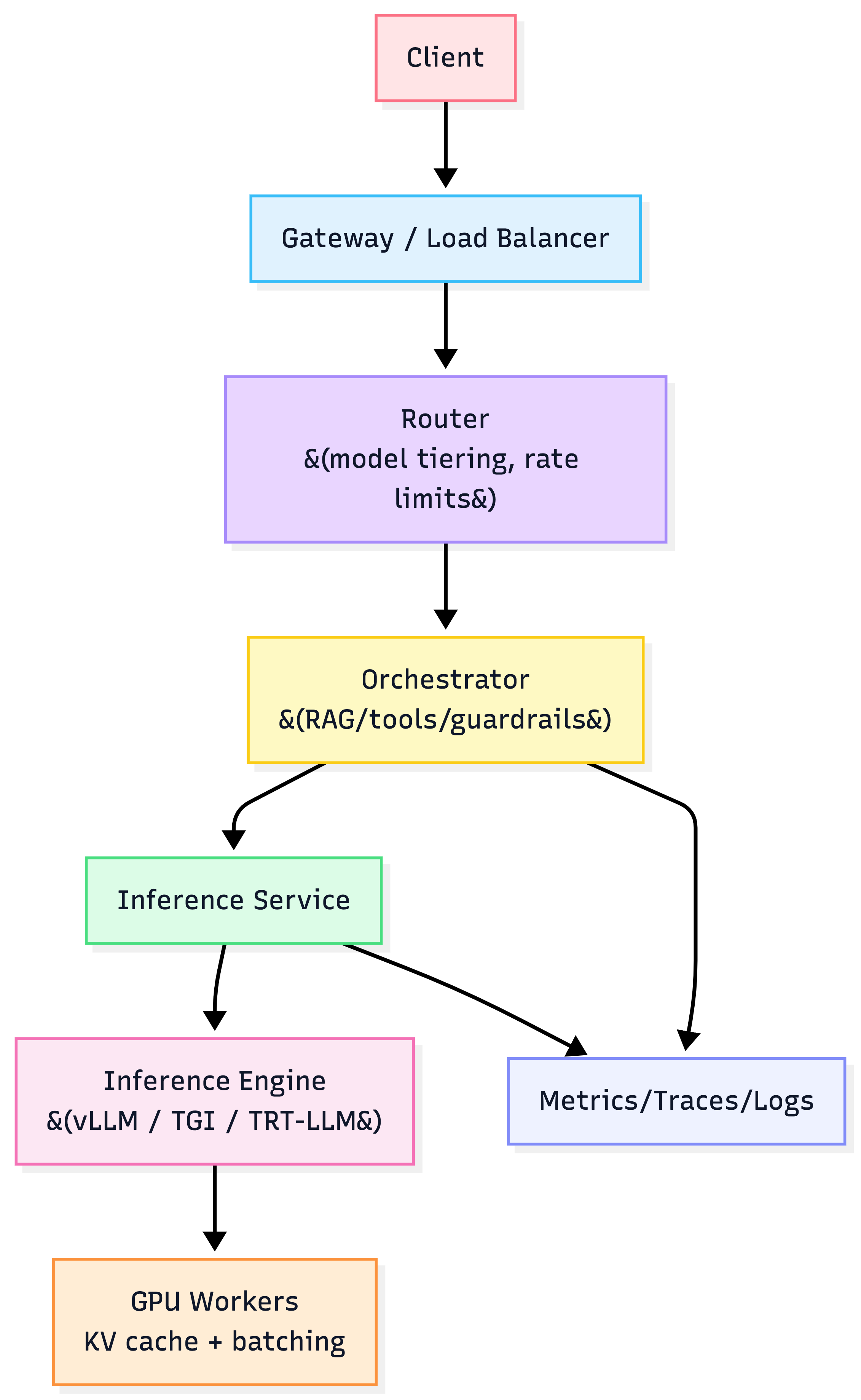
6) The “cold start” problem (why autoscaling is hard)
Cold starts can take minutes because:
- provisioning instances
- pulling images/weights
- loading weights into GPU memory
Mitigations
- keep a warm pool of standby replicas
- optimize image/weight fetching (streaming / caching / P2P)
- use memory-mapped weight formats where applicable
Heuristic: For interactive apps, treat scale-from-zero as an exception path, not the default.
7) Production rollout strategy (how leaders avoid outages)
Minimum viable reliability controls
- strict timeouts (TTFT and total)
- bounded retries (with backoff)
- circuit breaker on provider/cluster failures
- graceful fallback (smaller model / API / cached answer)
- load shedding (reject early vs melt down)
Rollouts
- Canary: 1–5% traffic, watch TTFT/TPOT/error/cost
- Shadow: mirror traffic to new stack, don’t serve results
- Blue/Green: switch over when stable
8) Three-horizon strategy (the sane roadmap)
Horizon 1 (Now): MVP
- use APIs/managed models
- instrument TTFT/TPOT + cost per successful task
- build eval flywheel (Chapter 6)
Horizon 2 (Next 6–12 months)
- add routing cascades (cheap vs strong)
- start benchmarking self-hosted baselines
- harden observability and perf testing
Horizon 3 (12+ months)
- self-host if TCO + moat justify it
- invest in deep serving optimization + custom model strategy
Migration roadmap: Three horizons
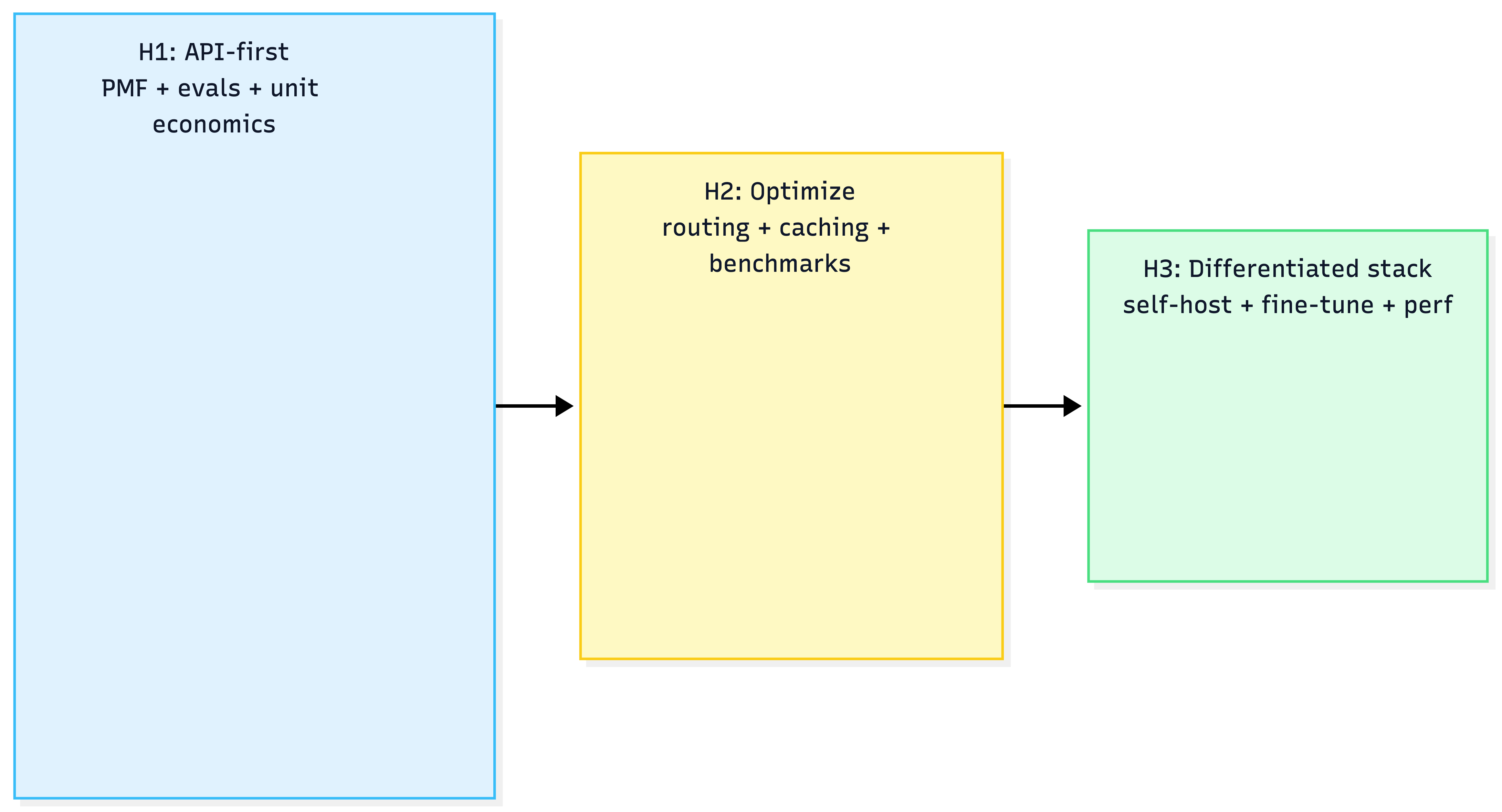
9) AWS-first mapping (default, framework-agnostic)
Fast path (managed-ish):
- Bedrock / SageMaker endpoints for inference
- API Gateway + WAF at edge
- CloudWatch + X-Ray + LangSmith (if LangChain) for tracing
- Auto scaling + alarms on TTFT/TPOT
Self-host path:
- EKS (KServe) or ECS on GPU instances
- inference engine pods/services (vLLM/TGI/TRT-LLM)
- ECR for images, S3/EFS/FSx for weights (with caching strategy)
- Prometheus/Grafana + CloudWatch integration (or equivalent)
“If you remember 7 things”
- Decide API vs self-host using privacy + latency control + utilization economics.
- Optimize separately for TTFT (prefill) and TPOT (decode).
- Throughput wins come from continuous batching + KV-cache efficiency.
- Quantization is often the highest ROI “GPU unlock”.
- Cold start is real—design around it.
- Reliability is timeouts + fallbacks + rollouts, not “hope”.
- Serving is a business lever: tokens/sec/$ is your north star.