Chapter 1: GenAI Product Planning & Strategy Playbook
Practical guide to choosing defensive moats, evaluating product wedges, running disciplined AI experiments, and establishing unit economics for GenAI products.
GenAI Product Planning & Strategy Playbook
The mindset shift
Traditional software: deterministic features, near-zero marginal cost. GenAI products: probabilistic systems, marginal cost per interaction, and fast commoditization.
3 production realities
- Costs scale with success → your best users are your most expensive users.
- Overnight commoditization → “API wrapper” advantages evaporate.
- Defensibility matters → pick and build a moat deliberately.
Heuristics
- If you can’t explain unit economics in one slide, you’re not ready to scale.
- If your differentiation is “we use Model X”, you have no differentiation.
- If you can’t show why users trust outputs, you’ll stall in enterprise adoption.
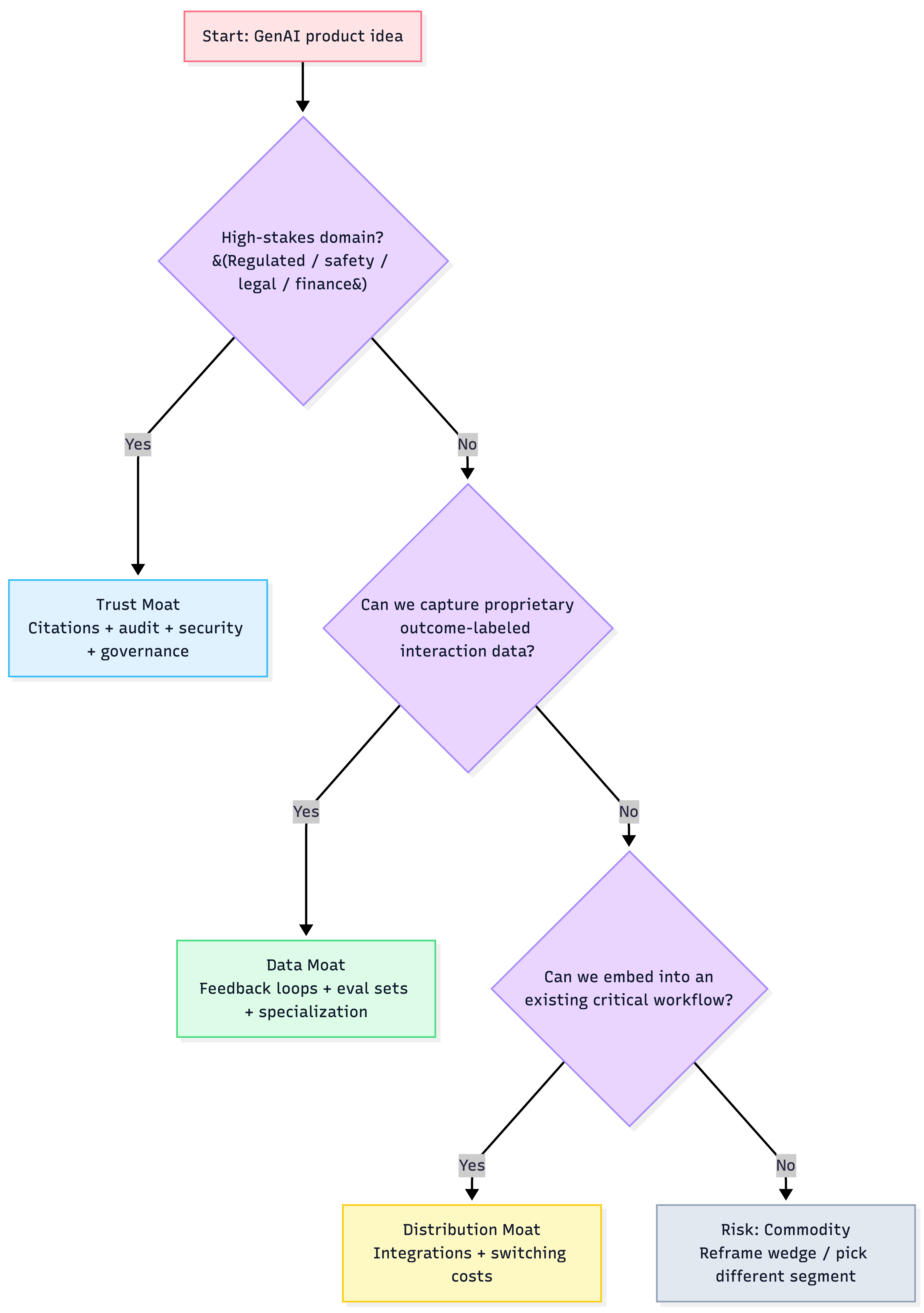
Phase 1 — Direction: Choose your moat (before writing code)
The 3 moats (and what you’re really building)
| Moat | What it means in practice | What to instrument from day 1 |
|---|---|---|
| Data moat | Interactions produce proprietary data that improves quality over time | prompts, contexts, outputs, feedback, outcome labels, eval sets |
| Distribution moat | Deep embed into workflows → high switching costs | integrations, APIs, SSO, approvals, audit trails |
| Trust moat | Most reliable + secure for a high-stakes domain | citations, policy checks, PII controls, monitoring, incident process |
Decision rules
- Choose Data moat if you can capture unique labeled outcomes at scale (not just chat logs).
- Choose Distribution moat if you can become the default UI/API inside an existing business process.
- Choose Trust moat if the domain is regulated/high-risk and reliability + compliance is the buying criteria.
Moat selection tree
Phase 2 — From idea to roadmap: choose high-impact wedges
Opportunity discovery (where GenAI wins)
- Repetitive, low-value work (automation)
- Skill bottlenecks (augmentation)
- Ambiguity navigation (ideation/research kickstart)
Heuristic: If the task has no measurable outcome, it’s an “AI demo”, not a product.
Idea evaluation rubric (score 1–5 each)
| Criterion | What “5” looks like |
|---|---|
| Sharp value hypothesis | Clear user pain + “10x” improvement claim |
| Technical feasibility | Current models reliable enough; data for RAG/finetune exists |
| Moat potential | Strengthens chosen moat (data flywheel, workflow embed, or trust) |
| ROI & unit economics | Cost-per-successful-task fits pricing & margins |
| Risks & ethics | Failure modes known; mitigation plan exists |
Fast filter (kill early)
- No clear user pain → kill
- No measurable success metric → iterate on definition
- No moat tie-in → re-scope wedge
Roadmap heuristic
- Start with 2–3 quick wins to create buy-in + baseline data.
- Run 1 strategic bet only if you have (a) metrics, (b) eval harness, (c) cost model.
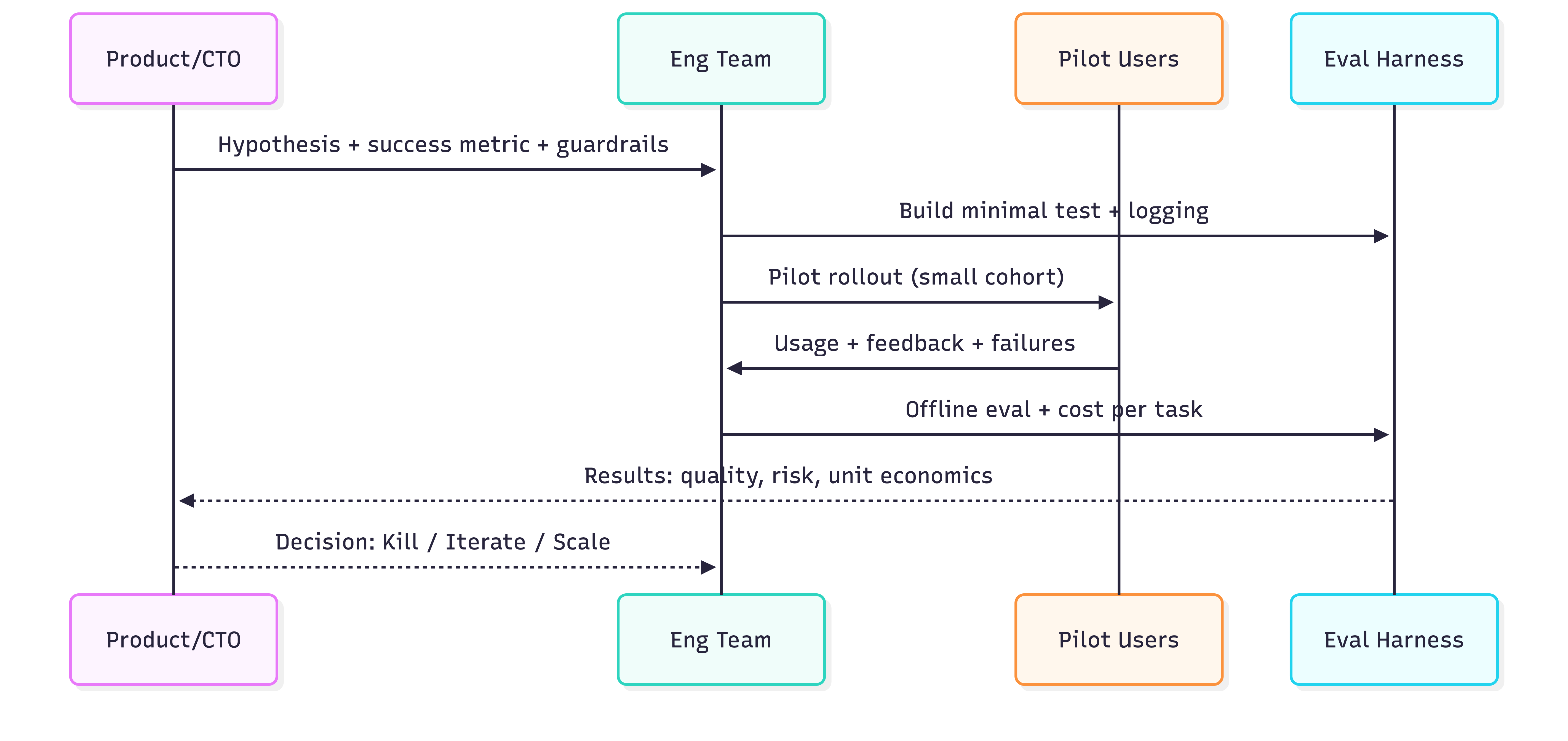
Phase 3 — Disciplined AI experiments (the core loop)
2-week AI sprint playbook (non-negotiable)
- Sharp hypothesis (business outcome + constraint)
- App-specific metric (not generic “accuracy”)
- Smallest test (prompt hack / Wizard-of-Oz / hardcoded RAG)
- Real users (internal-only gives false positives)
- Decision: kill / iterate / scale
- Artifact: write down learnings (institutional memory)
Heuristics
- If you can’t decide kill/iterate/scale after 2 weeks, your hypothesis was vague.
- Optimize workflow correctness before model sophistication.
- Treat LLM calls like distributed systems calls: timeouts, retries, fallbacks.
Experiment loop
Unit economics: your “must-have” early spreadsheet
Track these from prototype stage:
- Cost per successful task (not per request)
- Tokens per session (p50/p95)
- Model mix (cheap vs expensive routing)
- Retrieval tax (latency + token bloat from RAG)
- Gross margin at expected usage (before scale)
Rule of thumb
- Design for cost ceilings (budgets) before adding features.
- Your system should have a clear “cheap path” for common queries and a “premium path” for hard ones.
“Enterprise reality” implications for architecture
Key implications from the chapter:
- Expect multi-model usage (model-agnostic routing).
- Enterprises often build in-house unless you offer deep workflow integration + trust.
- Control/privacy are primary adoption drivers → trust moat gets amplified.
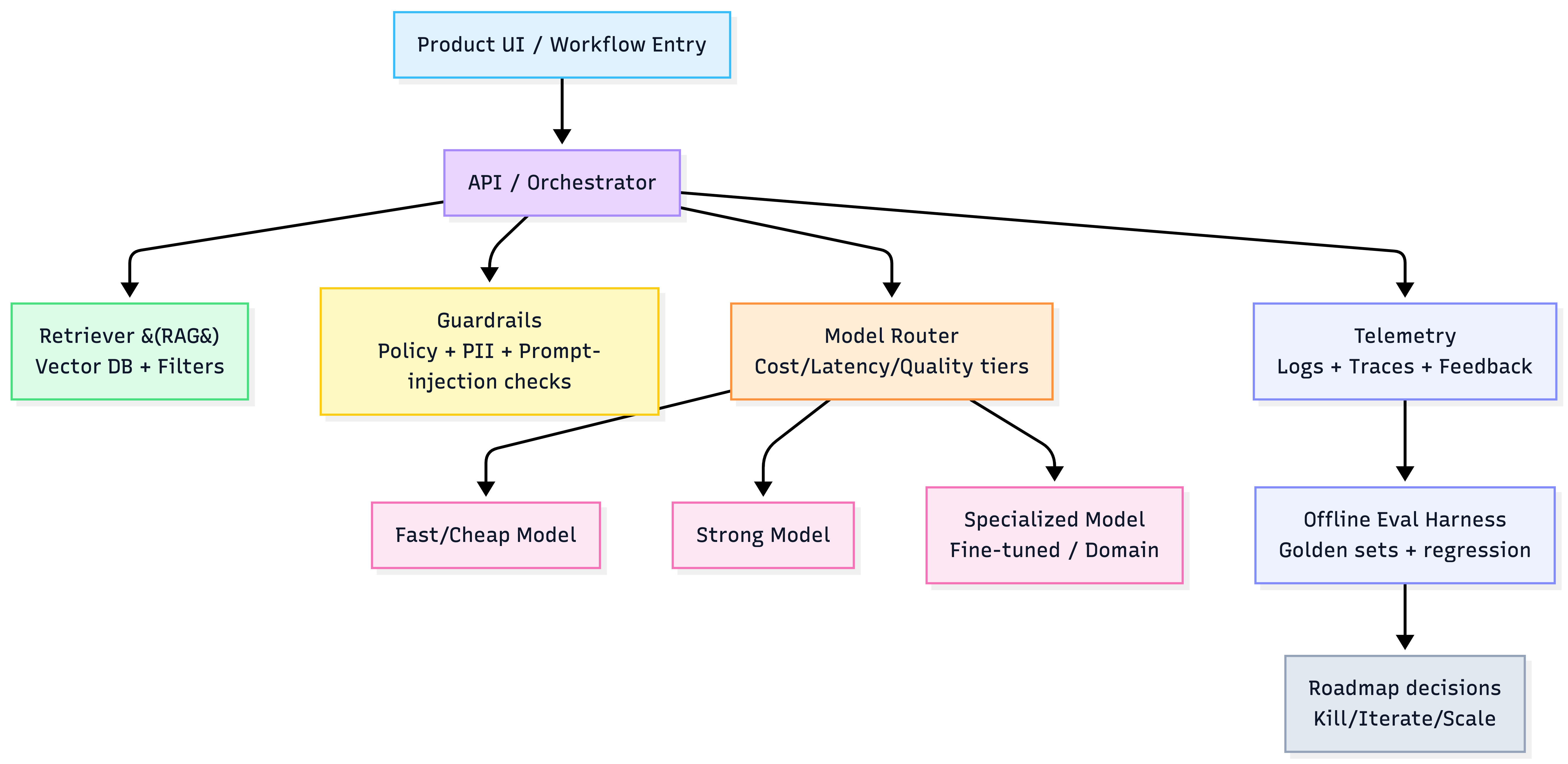
Practical architecture principle (AWS + LangChain default)
- Keep a model abstraction layer (swap Bedrock/OpenAI/Anthropic/open-source).
- Separate evaluation + telemetry pipeline from serving.
- Bake in trust UI primitives: citations, audit logs, and policy checks.
Model-agnostic product stack (high-level)
“Trust UI” checklist (your product moat in the UI)
If you target enterprise or high-stakes domains, ship these early:
- Citations / source links (for RAG outputs)
- Uncertainty signaling (“I’m not sure” + ask clarifying questions)
- Audit trail (who asked, what context used, what model responded)
- Policy & redaction (PII, secrets, prohibited data)
- Human approval gates for sensitive actions
Templates you can reuse (copy/paste)
1) One-paragraph value hypothesis
“If we use AI to [do X] for [user], we will improve [metric] by [Δ] while keeping [risk/cost constraint] below [threshold].”
2) Sprint decision memo (1 page)
- Hypothesis:
- Success metric + threshold:
- Cohort + duration:
- Results (quality, risk, cost/task, p95 latency):
- Top failure modes:
- Decision: Kill / Iterate / Scale
- Next action:
3) “Moat alignment” sanity check
- What data do we collect that competitors can’t?
- What workflow do we embed into that creates switching costs?
- What trust guarantees do we provide that reduce buyer risk?
What to do next (recommended order)
- Pick one moat (explicitly).
- Generate 10 candidate wedges, score them with the rubric.
- Run 2 quick-win sprints to establish logging/evals + cost model.
- Choose 1 strategic bet only after you have repeatable eval + unit economics.