Chapter 8: RAG - Advanced Strategies
Advanced RAG techniques covering default architecture, multilingual strategies, multimodal approaches, failure modes and fixes, and minimum viable RAG checklist.
RAG (Advanced Strategies, Multilingual, Multimodal)
The mental model
RAG is a ranking system + a synthesizer.
- Retrieval is an information retrieval problem (chunking, indexing, ranking, filtering).
- Generation is a grounded synthesis problem (faithfulness, citations, formatting). Most “RAG failures” are actually retrieval failures or context packing failures, not “bad LLMs.”
1) Default architecture (what "good" looks like)
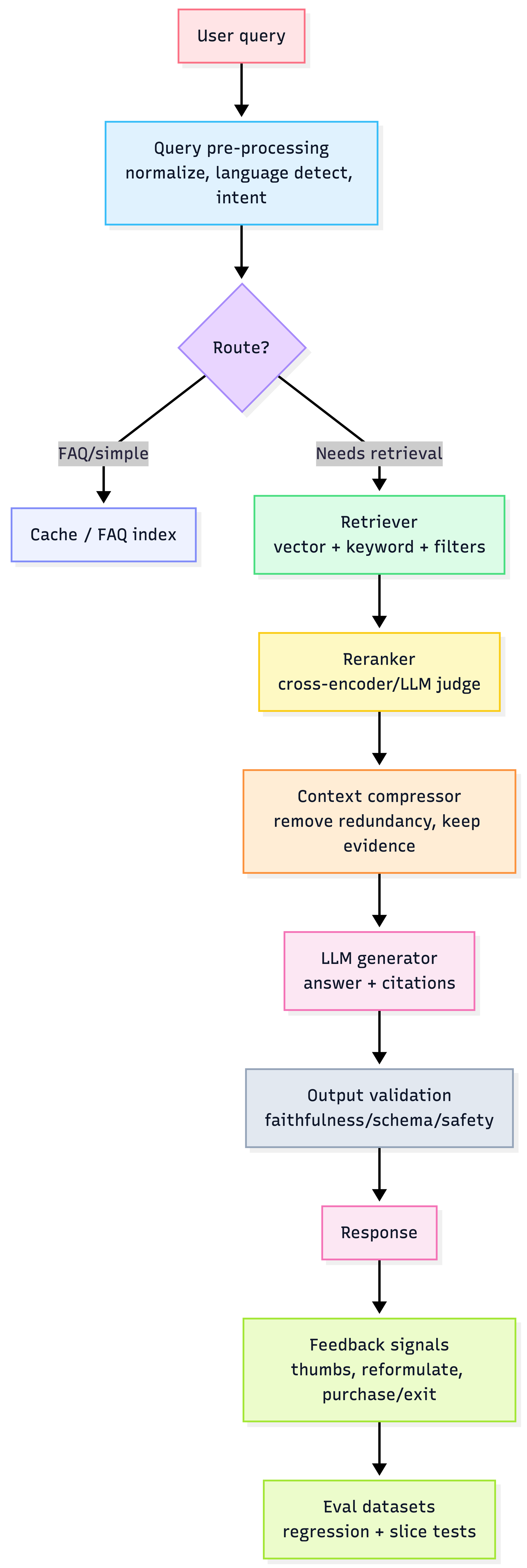
Heuristic: If you don’t have reranking + compression + eval slices, you’re running “RAG v0,” not production RAG.
2) The “Advanced RAG” menu (what to add, and when)
Add-ons by phase (use this as your roadmap)
| Phase | Technique | Use when | Trade-off |
|---|---|---|---|
| Indexing | Semantic chunking + metadata | generic chunking misses meaning; filtering matters | ingestion complexity; tuning required |
| Indexing | Embedding model fine-tuning | domain terms (“inseam”, “drop”, “GSM”) aren’t captured | needs curated pairs + MLOps overhead |
| Query | Query expansion | queries are short/ambiguous (“black shoes”) | can add noise + latency |
| Query | Query rewriting (LLM) | user intent unclear; messy queries | cost/latency + prompt brittleness |
| Query | Query routing | different intents need different indices | routing mistakes become failures |
| Retrieval | Hybrid search (BM25 + vectors) | product search needs exact matches + semantic | infra complexity + fusion tuning |
| Retrieval | Parent / small-to-big retrieval | you need tight matching but large context | more complex mapping/packing |
| Post-retrieval | Reranking | top-k contains noise; hallucinations | extra latency/cost; reranker quality critical |
| Post-retrieval | Context compression | long contexts inflate cost + distract model | risk of removing key evidence |
| System | Semantic caching | repeated/near-duplicate queries at scale | invalidation + threshold tuning |
| System | Agentic / multi-step RAG | multi-hop Qs (compare, troubleshoot, bundle) | orchestration risk + loops + cost |
| System | Fine-tune generator for context usage | model ignores context / poor citation habits | needs high-quality training triples |
Practical ordering (the 80/20)
- Metadata + semantic chunking
- Hybrid search
- Rerank
- Compress
- Only then: routing, query rewrite, agentic RAG, fine-tuning
3) Multilingual RAG playbook (EU reality)
You effectively have 3 strategies:
Strategy A — Multilingual / cross-lingual embeddings (recommended default)
- Embed all product text and user queries directly in their native languages using a multilingual embedding model. Why it wins: simplest operationally (one index), strong cross-lingual retrieval, avoids translation drift. Risk: model complexity and weaker performance for niche/rare languages depending on coverage.
Strategy B — Translate → monolingual embeddings (pivot language)
- Translate all catalog + queries into a pivot (often English) and embed with a strong monolingual embedder. Why it’s attractive: can use the “best” English embedding model. Risk: translation errors become retrieval errors; nuance loss hurts ecommerce (“fit”, “style”, “material”).
Strategy C — Hybrid: Translate + multilingual embeddings
- Translate to pivot, then embed using multilingual embeddings. Often a strong practical compromise, especially for rare languages. Risk: you pay both translation + embedding latency/complexity.
Multilingual routing
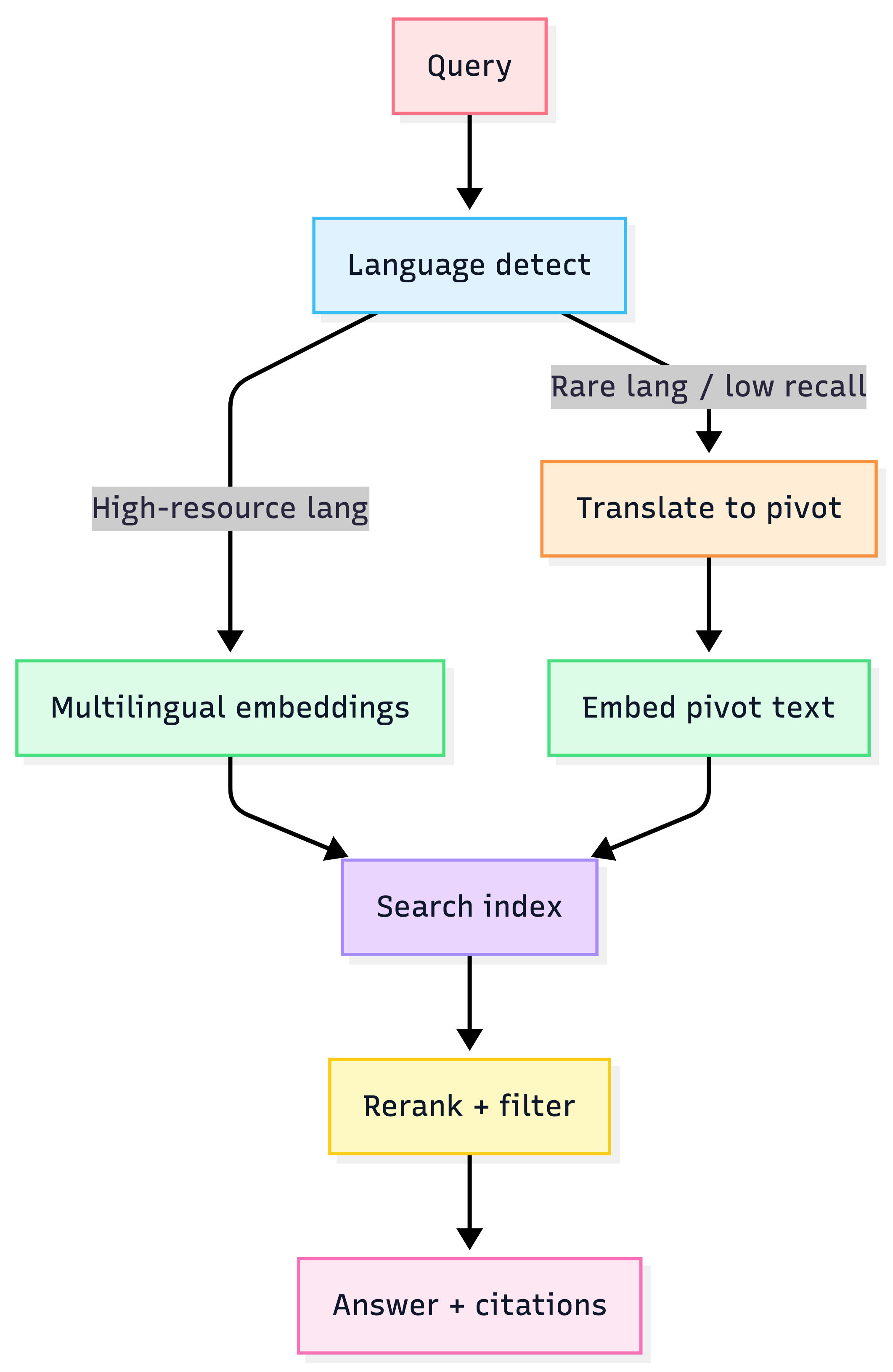
CTO heuristic: Default to multilingual embeddings. Add translation only when you observe measurable recall gaps for specific languages/slices.
4) Multimodal RAG playbook (text + images + tables)
You have 4 main approaches:
Option 1 — Flatten everything to text (fastest v0)
- Images → captions/descriptions; tables → serialized text; then standard text RAG. Best for: MVP, low complexity. Risk: loses fine visual/table structure; weaker for “show me similar style” or spec-heavy queries.
Option 2 — Separate modality indices (most practical production default)
- Text index + image embedding index (+ tables as structured store or text), unified by product_id metadata. Best for: ecommerce (text queries + image similarity + spec tables). Risk: routing complexity (which index to hit?)
Option 3 — Unified multimodal embeddings (conceptually elegant)
- One embedding space for text+images; one index. Risk: heavily dependent on embedding quality; tables are still awkward.
Option 4 — Multi-vector / hybrid (highest quality, highest complexity)
- Store multiple representations: text chunks, image embeddings, table structures, plus summaries; retrieve best-of-breed per query. Best for: mature systems with clear ROI. Risk: complex ingestion + fusion + latency.
Practical multimodal architecture (Option 2)
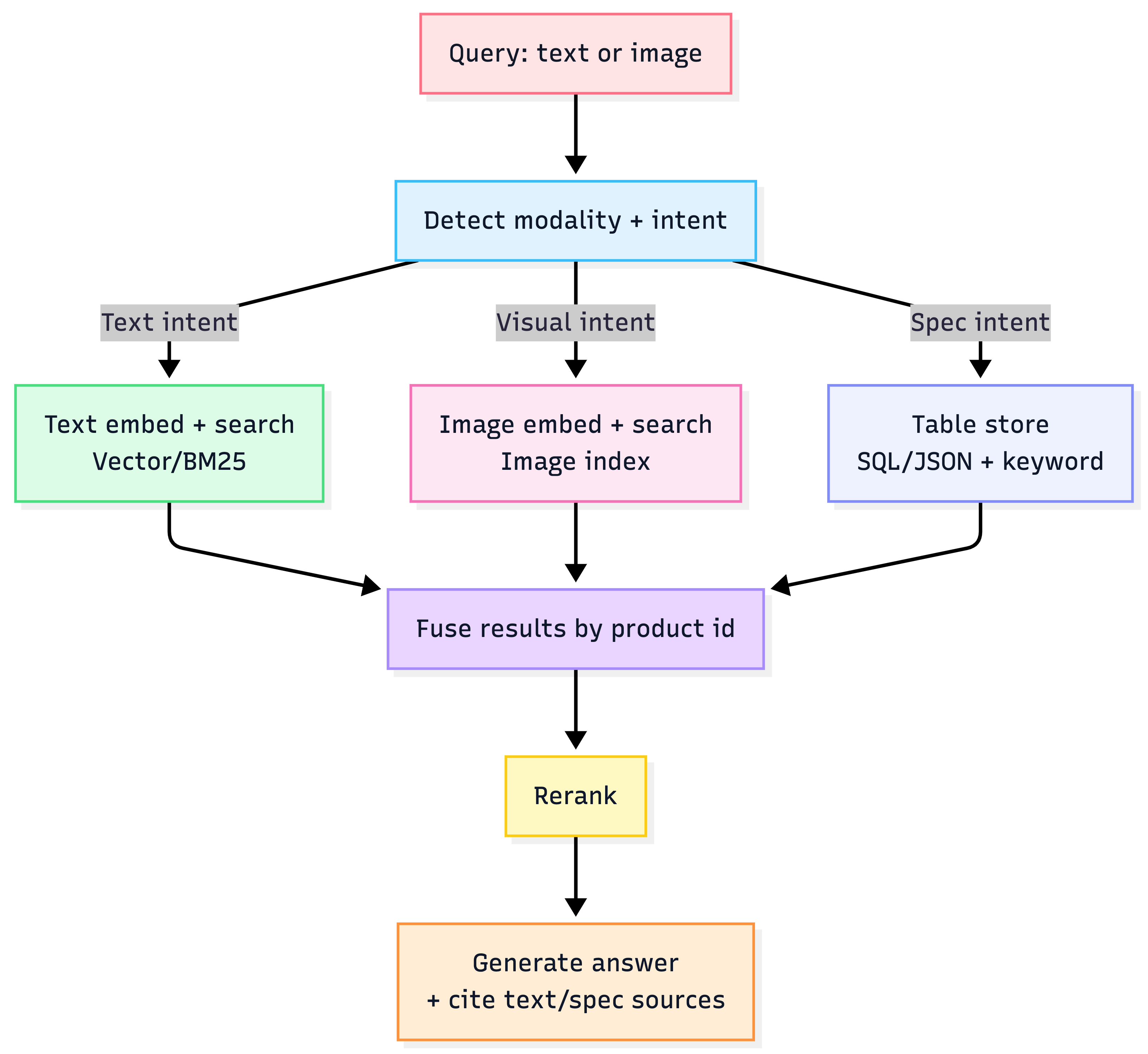
Heuristic: Start with Separate modality indices. Move to multi-vector only when you can point to revenue-impacting query classes (e.g., “find similar style”, “compare specs”, “compatibility”).
5) Failure modes (and the fix that actually works)
| Symptom | Root cause | Fix |
|---|---|---|
| “Hallucinations” | retrieval noisy / missing evidence | rerank + better chunking + hybrid + stricter “NOT_FOUND” |
| Wrong product recommended | intent mismatch | query rewrite/routing + metadata filters |
| Too slow / too costly | context bloat | compression + reduce k + caching + “RAG only when needed” |
| Works in English, fails in German/French | cross-lingual recall gap | multilingual embeddings + language-slice evals; targeted translation fallback |
| Tables/specs wrong | table treated as text | structured table store + spec-aware generator formatting |
6) AWS-first reference mapping (defaults)
- Vector store: OpenSearch (hybrid) or Aurora pgvector
- Cache: ElastiCache (Redis) for semantic/exact caching
- Translation (if used): Amazon Translate
- Embeddings: Bedrock embeddings (or hosted embedding model on SageMaker)
- Reranker: lightweight cross-encoder on SageMaker/ECS (or LLM judge for premium route)
- Multimodal embeddings: image encoder on SageMaker (CLIP-like) or managed option depending on your stack
- Orchestration: ECS/Fargate (steady traffic) or Lambda (spiky) + Step Functions for offline ingestion
7) The “minimum viable advanced RAG” checklist
If you ship only these, you’ll beat most teams:
- semantic chunking + metadata filters
- hybrid retrieval (BM25 + vector)
- reranking
- context compression
- multilingual: one default approach + language-slice evals
- multimodal: separate indices + product_id fusion
- eval harness: retrieval precision/recall + faithfulness (Chapter 6)