Chapter 2: GenAI Product Architecture
Production architecture patterns covering orchestration layers, decision flows for Prompt vs RAG vs Fine-tune, guardrails, agents, performance optimization, and evaluation frameworks.
GenAI Product Architecture
The core mental model
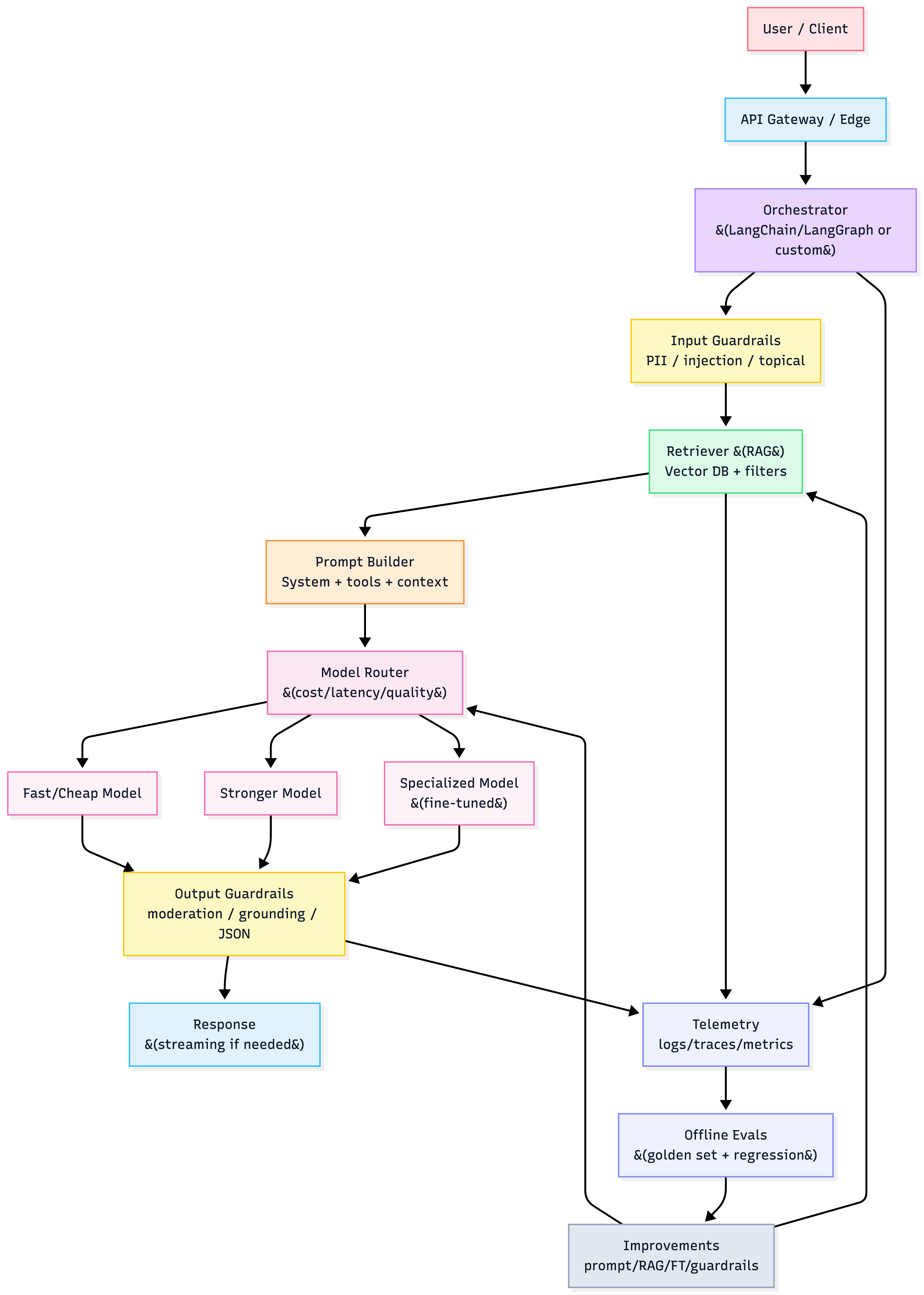
GenAI apps are distributed systems where every user request is a probabilistic compute job. So architecture isn’t “model + UI”—it’s data → context → orchestration → safety → serving → observability → feedback loop.
1) The new full-stack (what you must design)
Functional layers (production view)
- Data processing (clean, chunk, embed, index)
- Model layer (select/serve/adapt models)
- Orchestration (routing, prompt assembly, tool calls, retries)
- Deployment & integration (APIs, auth, rate limits, isolation)
- Monitoring & observability (latency/cost + quality/safety)
- Feedback & continuous improvement (flywheel: logs → evals → fixes)
Canonical production architecture
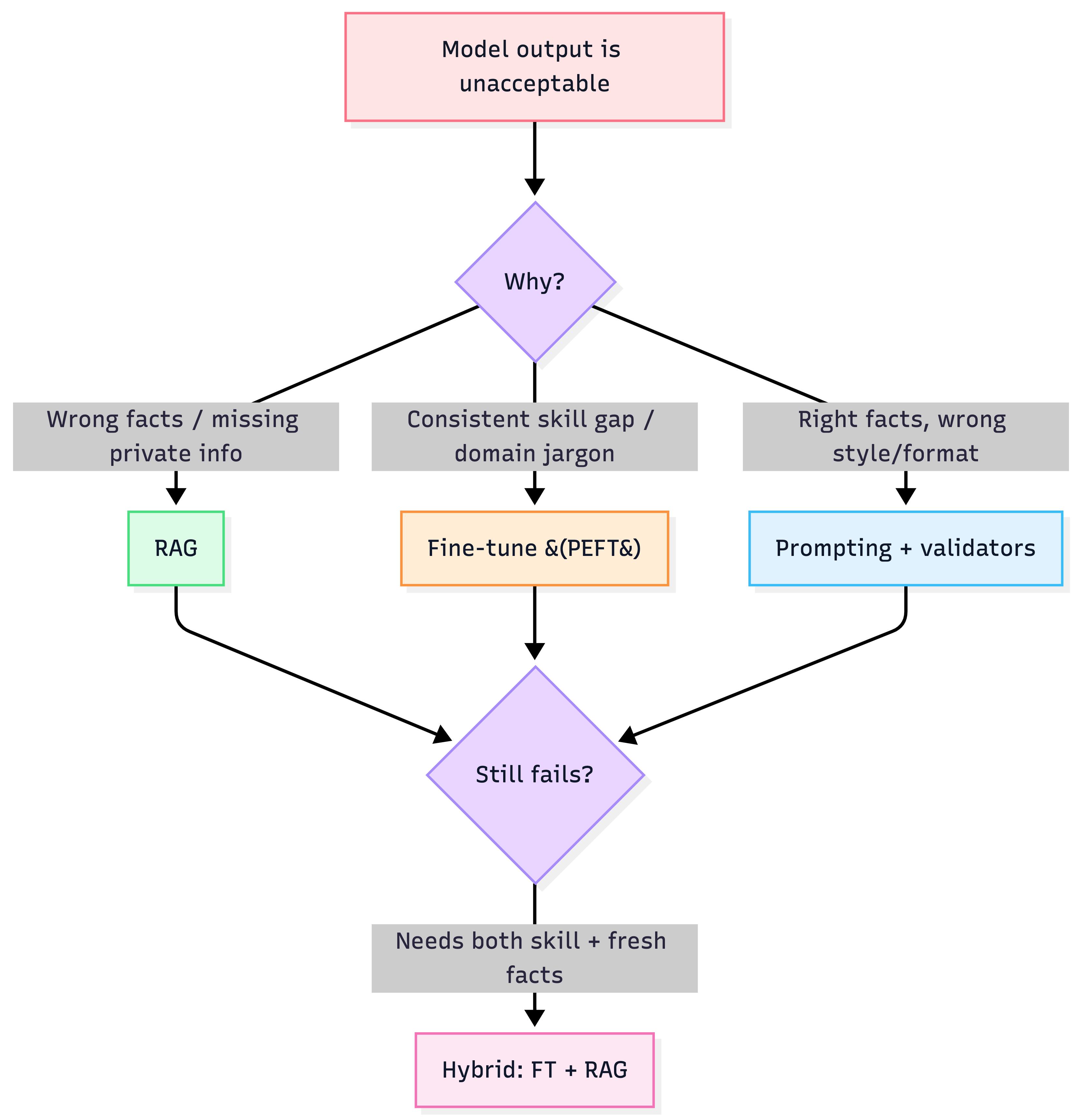
2) The big strategic decision: Prompt vs RAG vs Fine-tune
Choose based on the reason the model fails
| Technique | Use when you need… | Typical failure it fixes | Hidden cost |
|---|---|---|---|
| Prompting | steering behavior/format | inconsistent style, bad structure | brittle prompts, edge cases |
| RAG | correct/up-to-date/private knowledge | hallucinations, stale facts | latency + token bloat (“RAG tax”) |
| Fine-tuning (PEFT/LoRA) | new skill, consistent behavior | domain jargon, strict style | dataset curation, training ops |
| Hybrid (FT + RAG) | skill + fresh facts | expert assistant | orchestration complexity |
Heuristics
- Fine-tune for skill, RAG for knowledge (best default for “expert assistants”).
- If failures are “wrong facts” → RAG first.
- If failures are “right facts but wrong behavior” → FT or better prompting.
- If failures are “too slow/expensive” → routing + caching + smaller models before anything else.
Decision flow
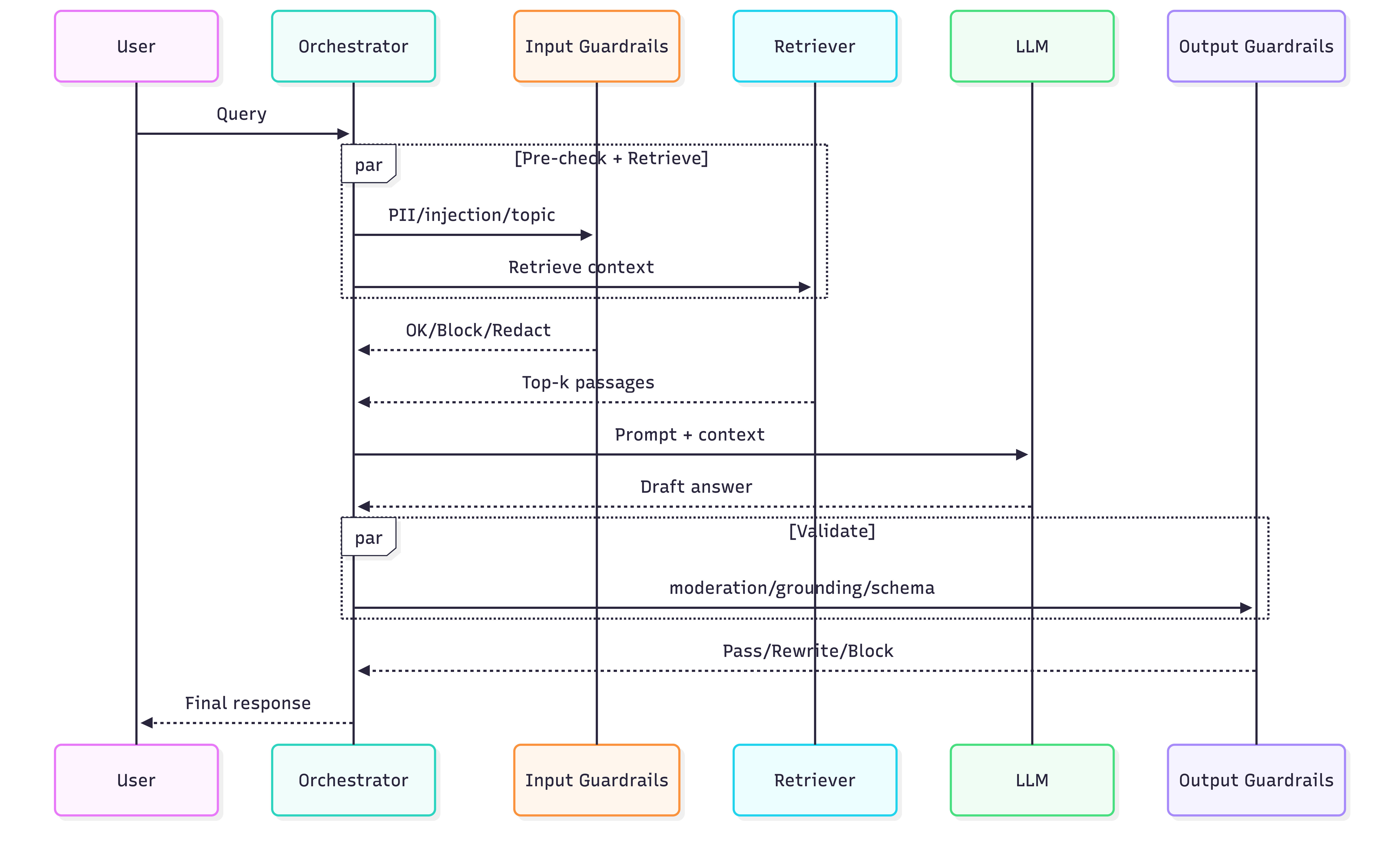
3) Guardrails are architecture, not prompts
Guardrail coverage map
Input guardrails (protect system)
- PII detect/redact
- prompt injection detection
- domain/topic gating
Output guardrails (protect user/business)
- moderation/toxicity
- grounding / factual consistency (esp. RAG)
- schema checks (JSON, tools, code formatting)
Key implementation trick
- Run guardrails asynchronously/parallel where possible to reduce latency; block only when triggered.
Parallel guardrail execution
Anti-patterns
- “All safety in system prompt” (won’t hold under attack or drift).
- No audit trail for enterprise workflows.
- Guardrails that silently “modify” answers with no trace (destroys trust/debuggability).
4) Agents & orchestration: pick the simplest that works
Pattern selection
| Pattern | When it’s best | Risk |
|---|---|---|
| Deterministic chain | repeatable workflows (extract → validate → respond) | low flexibility |
| Single agent + tools | exploration + tool use with bounded scope | tool misuse, loops |
| Multi-agent | complex tasks w/ specialized roles | cost + coordination failures |
Heuristics
- Start deterministic. Add agent autonomy only where it creates measurable user value.
- Put budget + step limits + tool permissions around agents.
5) Performance engineering: win before you scale
The latency/cost levers (in order)
-
Reduce tokens (shorter context, better chunking, compression)
-
Cache
- exact match cache (cheap)
- semantic cache (bigger win, more complexity)
-
Route models (cheap path for common queries; strong model for hard ones)
-
Optimize serving (quantization, vLLM/TensorRT-LLM, batching)
Rule of thumb
- Don’t pay the “RAG tax” on every request—route only queries that need retrieval.
6) Evaluation + Observability: non-negotiable for “production”
What to measure (beyond latency)
- TTFT / p95 latency, throughput, cost per request
- Cost per successful task (the metric that matters)
- Hallucination/grounding rate
- Guardrail trigger rate
- User feedback (explicit + implicit regeneration/abandon)
- End-to-end traces across retriever → model → validators
Eval toolbox
- automated metrics (task-dependent)
- LLM-as-a-judge with rubric (scalable)
- human eval (gold standard for nuanced quality)
Heuristic: every production incident should become a test case in a regression suite.
7) AWS-first reference mapping (defaults, framework-agnostic)
(Use as a starting point—swap as needed.)
- API/Edge: API Gateway + WAF
- Orchestration: ECS/Fargate or Lambda; Step Functions for workflows
- RAG store: OpenSearch / Aurora pgvector / DynamoDB+vector option / managed vector DB
- Cache: ElastiCache (Redis)
- Models: Bedrock or SageMaker (or external providers)
- Observability: CloudWatch + X-Ray (plus LangSmith if using LangChain)
- Feedback/eventing: Kinesis/SQS + S3 for logs + Athena/Glue for analysis
8) “Minimum viable production” checklist (what you ship first)
Architecture essentials
- model router (at least 2 tiers)
- retrieval (only if needed) + citations
- input/output guardrails
- request timeouts + retries + circuit breaker
- structured logging + traces
- eval harness + small golden set + regression tests
Defensive UX
- set expectations, show sources, allow edits, “regenerate”, feedback buttons