Chapter 10: Industry Patterns & Case Studies
Production patterns from winning GenAI products covering vertical co-pilot architecture, trust stack design, controller-delegate patterns, economics of intelligence, and CTO decision frameworks.
Industry Patterns & Case Studies (How Winning GenAI Products Actually Win)
The mental model for CTOs
Models commoditize. Winners compound advantage through:
- Vertical Co-Pilot workflow embedding
- A defensible Trust Stack (data + grounding + security + guardrails)
- A shift from single-call apps → agentic / multi-step workflows
- Economics of Intelligence (prove ROI with numbers, not vibes)
1) Pattern #1: Vertical Co-Pilot (augment experts, don’t replace them)
What it is
The most successful products are not “general chatbots.” They’re domain co-pilots embedded in the daily tools of experts—automating low-value tasks and accelerating high-judgment work.
Examples mentioned in the chapter
- Med-PaLM 2 (clinical summaries), Harvey (legal drafting/summarization), GitHub Copilot (boilerplate/code assist), Morgan Stanley’s internal wealth assistant (grounded on proprietary research).
Why it wins (the business mechanics)
- Lower adoption friction: lives inside the tool (IDE / internal platform)
- Sticky: switching costs become workflow costs
- Clear ROI: time saved per task is measurable
Heuristic
If your product requires users to “go to the AI app,” you’re already losing to products that embed in the workflow.
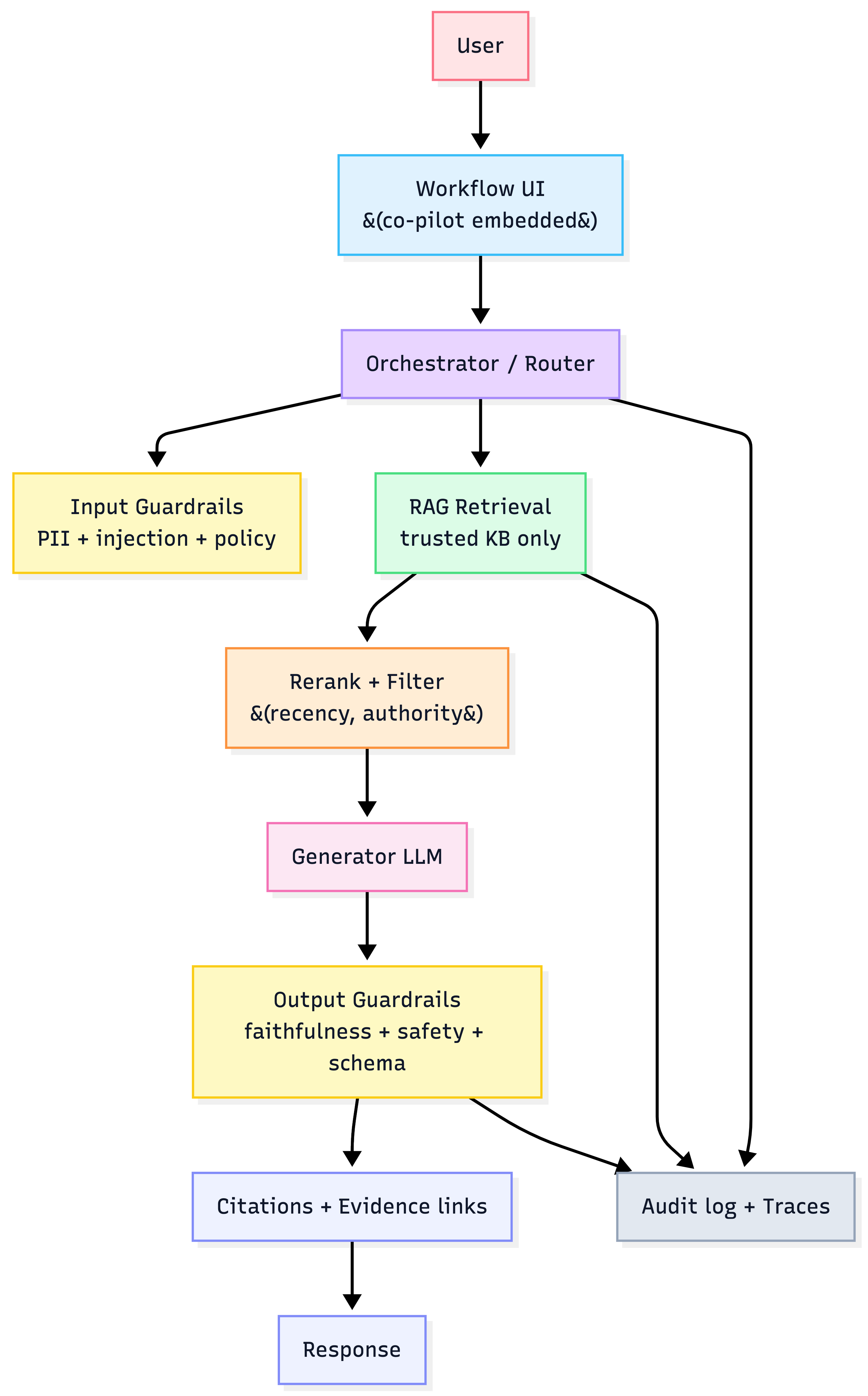
2) Pattern #2: Trust Stack = the durable moat
What “Trust Stack” means in practice
Winners build architecture that makes outputs verifiable, data controlled, and actions safe—because hallucinations + privacy are enterprise deal-killers.
Trust Stack layers
- RAG on controlled data (grounding)
- Verifiability by design (citations to sources)
- Security/privacy-first (stateless, no training on customer data; VPC/on-prem options)
- Guardrails (PII checks, stop rules, human approval for sensitive actions)
Trust Stack architecture (portable)
Heuristic
In enterprise GenAI, trust is a feature, not an internal engineering concern.
3) Pattern #3: From “augmentation” → “agency” (multi-step workflows)
What changed
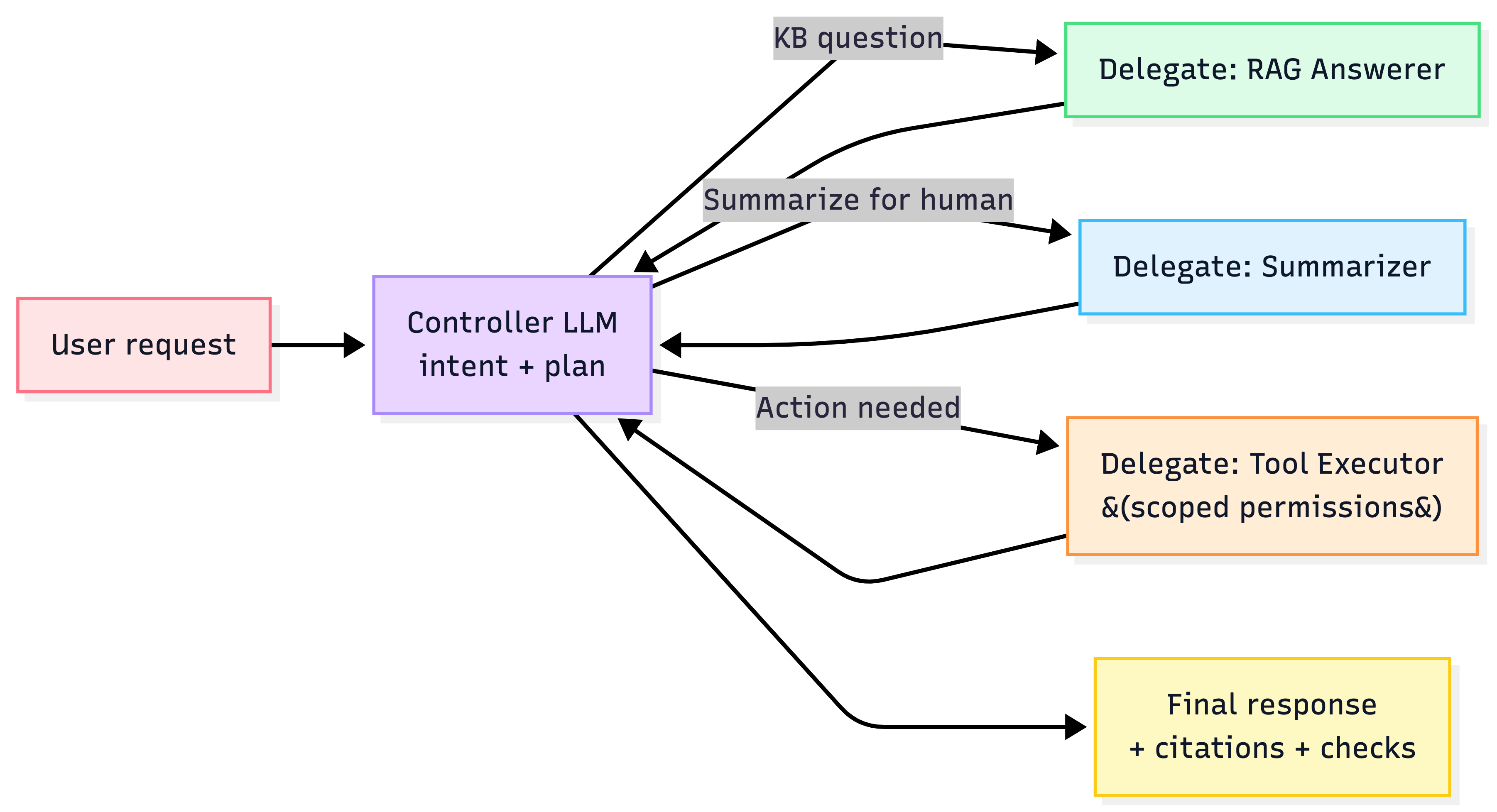
As products expand, “one mega prompt” becomes bloated and unstable. Winning teams move to multi-prompt / multi-step architectures: a controller routes tasks to specialized subprompts/agents.
Examples in the chapter
- GoDaddy pivoted from a single-prompt system to a Controller–Delegate multi-prompt architecture for accuracy and token efficiency.
- LinkedIn uses a routing agent to pick specialized downstream agents.
Controller–Delegate pattern
Heuristics
- Add “agency” only when it unlocks measurable workflow value (time saved, fewer steps, fewer handoffs).
- Bound it: step limits, tool allowlists, budgets, human approval gates.
4) Pattern #4: Economics of Intelligence (the actual adoption driver)
What enterprises buy
They don’t buy “LLM capability.” They buy:
- Time saved (seconds/minutes per workflow step)
- Cost reduced (support costs, ops costs)
- Revenue lift (conversion, retention, upsell)
Cost discipline patterns
The chapter highlights common winning tactics:
- Model tiering / adaptive selection (cheap model for simple tasks, expensive for complex)
- Fine-tune smaller open-source models for narrow tasks (e.g., distill from a stronger model)
- Token optimization (tight prompts + control outputs)
Heuristic
Your “best customers” are your most expensive users. If unit economics isn’t designed early, success becomes a cost crisis.
5) The modern RAG blueprint (the reference architecture)
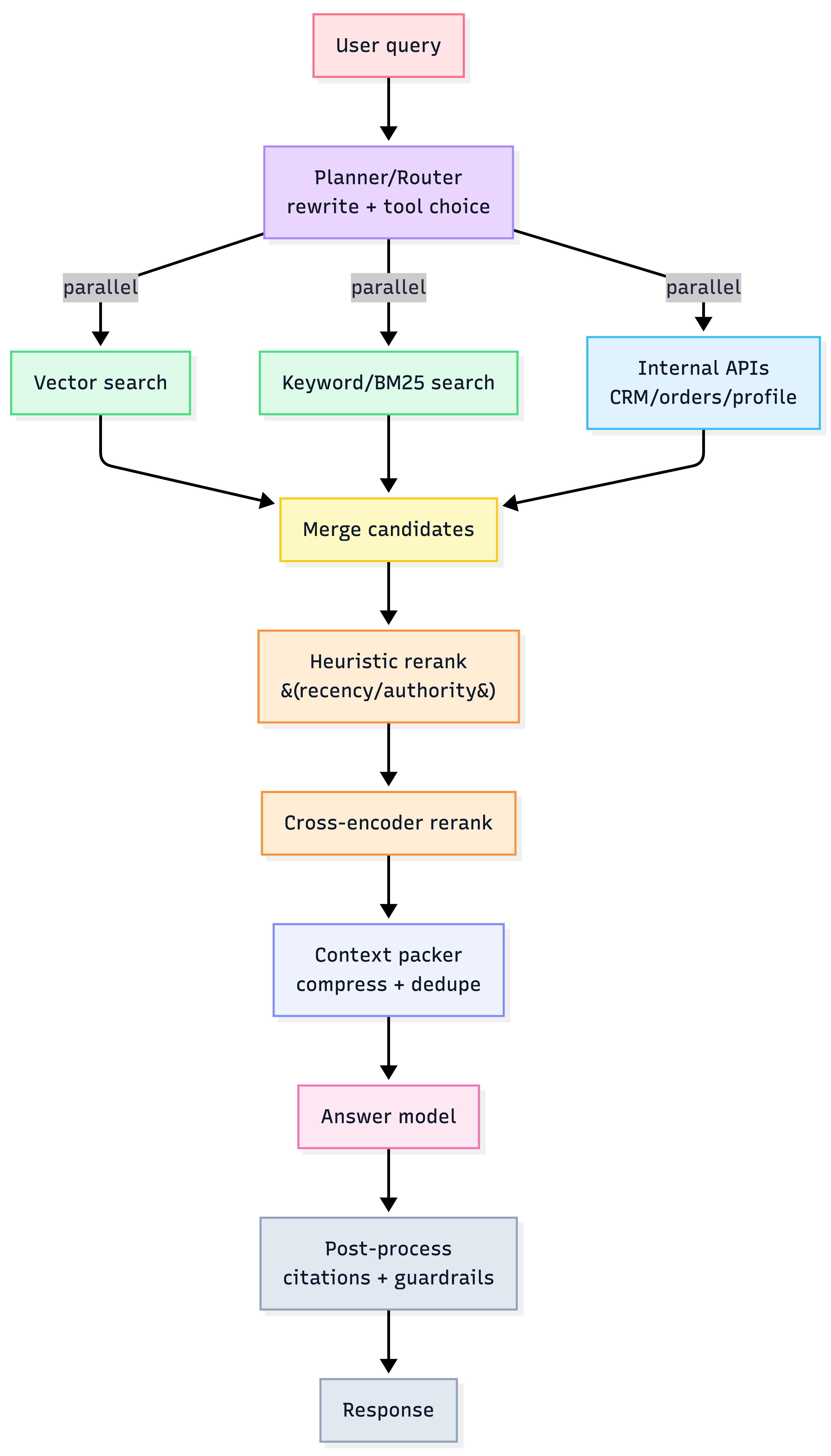
The chapter’s reference blueprint emphasizes:
- Planning/routing (fast model decomposes query, chooses tools)
- Parallel retrieval (vector + keyword + internal APIs)
- Synthesis & reranking (heuristics then cross-encoder)
- Generation & post-processing (citations + formatting + guardrails)
Full RAG pipeline (production)
Heuristic
Retrieval is recall-first; reranking is precision-first. If you skip reranking, hallucinations look like “LLM issues.”
6) CTO Decision Matrix (how to decide like winners)
| Decision area | Default winning move | Why |
|---|---|---|
| Model strategy | Hybrid multi-model | cost control + quality where needed |
| Knowledge strategy | RAG-first for factual domains | reduces hallucinations; keeps data controlled |
| Output reliability | Assume failure + defensive parsing | structured output breaks in prod; guard it |
| Performance | Streaming + async + retries | better UX + resilience to provider blips |
| Testing | LLM judge + golden set + human calibration | scalable quality control |
| RAG data | Tune your corpus (dedupe/summarize) | reduces noise + token cost |
7) Due diligence checklist for “winning GenAI products”
Use this to evaluate product ideas (or vendors):
- Workflow-first: does it embed where users already work?
- ROI proof: can you quantify time/cost/revenue impact?
- Defensibility: is there a proprietary data flywheel?
- Trust stack: citations, auditability, security, guardrails
- Architecture realism: latency + cost + reliability plan exists
- Risk profile: demand vs risk (high-demand/low-risk wedges first)
If you remember 6 things
- Build vertical co-pilots, not general chat.
- Defensibility = data + trust stack, not “best model.”
- Move from mega prompts to controller–delegate architectures as scope grows.
- RAG is the enterprise default for factual work.
- Model tiering + token discipline keeps unit economics sane.
- Evals + traces turn incidents into compounding advantage.