Teaching an Open-Source LLM to Write The Office
Fine-tuning a reasoning-first LLM to generate sitcom screenplays with on-brand humor, character voice, and multi-step setups.
Why This Project?
Most LLM demos focus on generic chat or coding. I wanted to show something different:
Specific Domain
A single sitcom (The Office) with strong, recognizable character voices.
Reasoning-Heavy Format
Each sample includes both a planning / reasoning trace and the final screenplay.
Production Pipeline
Data curation, SFT, RFT, automated evaluation, and visualization.
This case study doubles as:
- A product demo: "What if you could auto-generate new The Office episodes?"
- A skills demo: End-to-end fine-tuning of open-source LLMs for a narrow, stylistic generation task.
System Overview
Goal: Given a high-level sitcom situation (e.g., "Michael uses Pam's post-its to avoid work calls"), generate:
- A reasoning trace that plans beats, character goals, and comedic engines.
- A full screenplay scene consistent with The Office tone.
Reasoning Trace Structure
The training dataset uses a structured reasoning-first approach where each sample includes a comprehensive creative blueprint before the screenplay. The reasoning trace contains:
1. Storyline Goal
Defines the narrative purpose, core conflict, and comedic goal.
2. Character Objectives
Each character's immediate want or need.
3. Character Dynamics
Interpersonal conflicts and alliances.
4. Meta Reasoning
Writer's room approach—why this is funny.
5. Primary Comedy Engine
Cringe, Dramatic Irony, Absurdity, Escalation.
6. Beat Sheet
Inciting Incident → Rising Action → Climax → Resolution.
7. Talking Head Strategies
How characters use confessionals for comedy.
8. Comedy Tropes Applied
Specific comedic devices used.
This structured approach teaches the model to think like an Emmy-winning TV writer before generating the final screenplay.
Models Compared
Base Model
Gemma-3 1B — Original LLM (no domain fine-tuning)
SFT
CoT Reasoning — Supervised fine-tune on reasoning + screenplay
RFT
Model Grader — Reinforcement fine-tune using LLM-as-judge rewards
LLM-as-Judge Evaluation Criteria
The judge evaluates each generated screenplay using eight weighted metrics that capture both technical quality and stylistic authenticity:
| Metric | Weight | Focus |
|---|---|---|
| Character Consistency | 25% | Does dialogue perfectly align with each character's established persona? |
| Humor Quality & Specificity | 25% | Is the humor effective and consistent with The Office's comedic DNA? |
| Narrative Coherence | 15% | Does the screenplay follow a logical comedic progression? |
| Style Fidelity | 15% | Authentic mockumentary techniques (talking heads, camera glances)? |
| Dialogue Plausibility | 5% | Natural and conversational while being witty? |
| Creative Plausibility | 5% | Fresh ideas that fit within the show's reality? |
| Formatting Accuracy | 5% | Strict adherence to structure? |
| Relevance to Storyline | 5% | Reflects the provided scenario? |
The final score is a weighted average with the highest weights on Character Consistency and Humor Quality—the two elements that define The Office's unique voice.
Training & Results
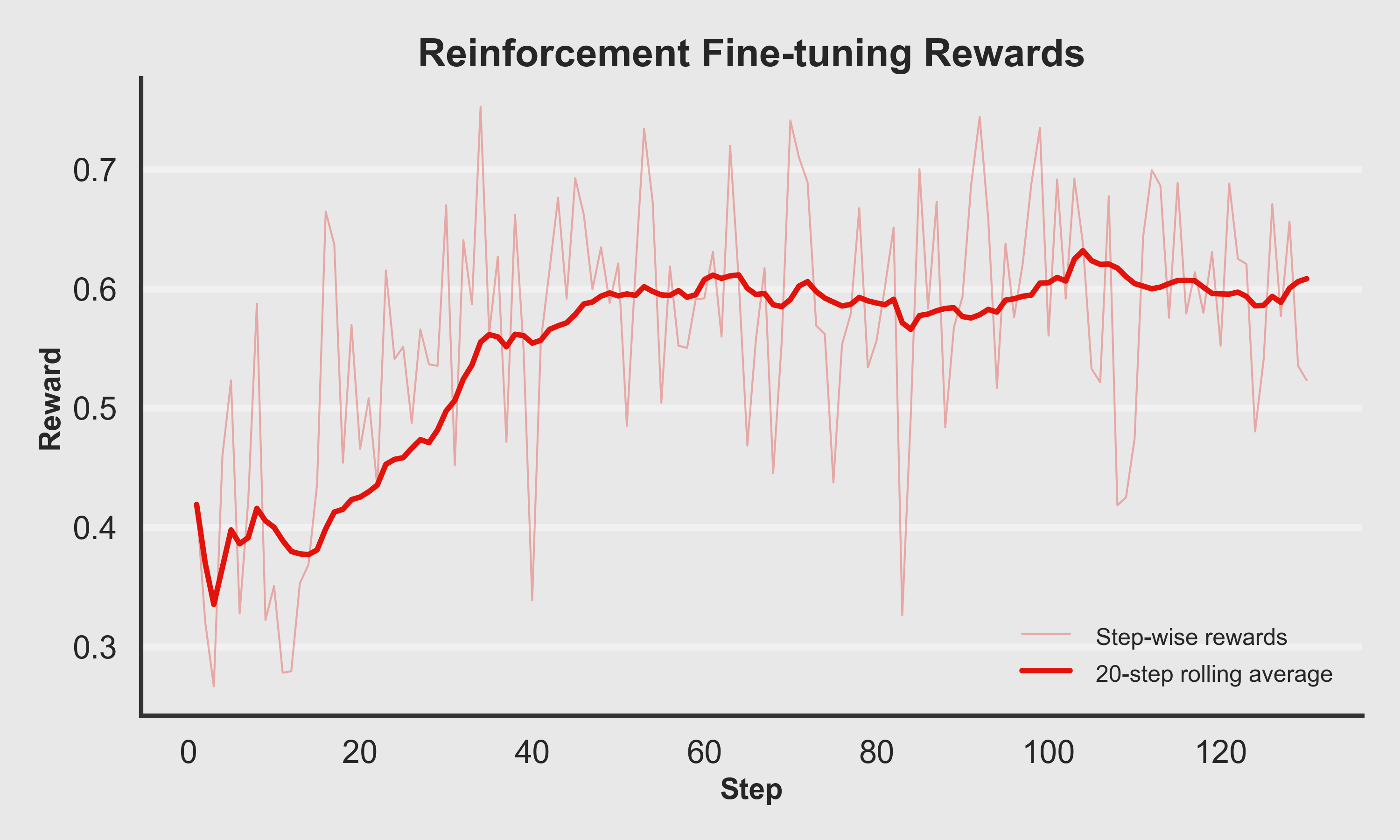
Reinforcement Fine-Tuning Rewards
How quickly does the policy learn to please the sitcom-style judge?
The reward progression plot shows step-wise rewards (light red) and a 20-step rolling average (bold red):
- Early steps show high variance and lower average rewards.
- The rolling average climbs steadily as the policy learns, then plateaus as it reaches a stable style that the judge prefers.
- Occasional dips reflect exploration and noisy judge scores, but the overall trajectory trends upward.
You can think of this as the model gradually learning: "Don't just be coherent—be character-consistent, witty, and structurally Office-like."
Quantitative Evaluation
I evaluated all three models on a held-out set of sitcom prompts, scoring each output with a domain-tuned LLM-as-judge (0–1 scale, normalized).
Score Distribution by Model
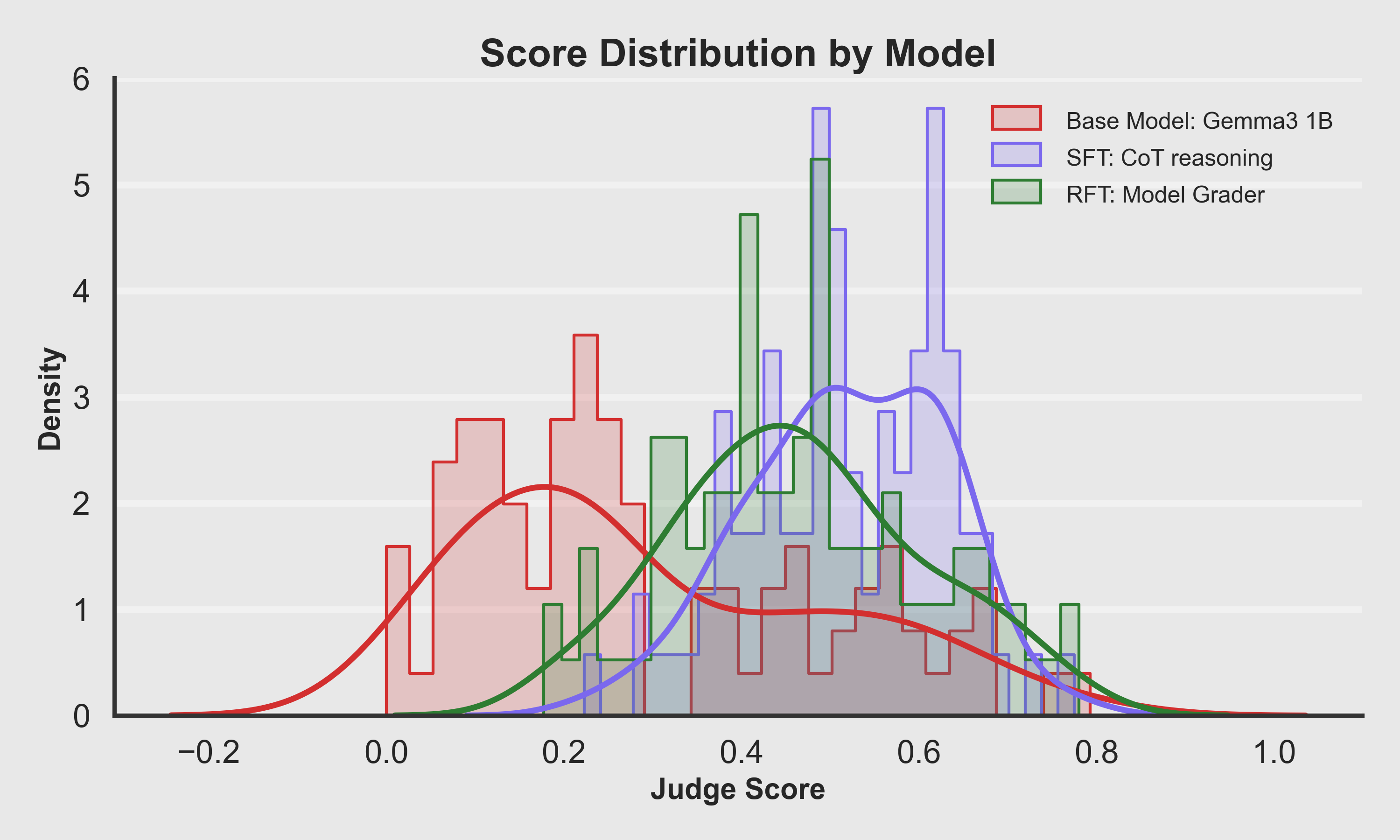
- The Base Model is concentrated at lower scores, with most samples clustered toward the left.
- SFT Model shifts the distribution right: more samples in the mid-to-high range.
- RFT Model also lives in the higher band, trading a bit of spread for more consistently good outputs.
Visually, you can see the "cloud" of scores moving to the right as training progresses from Base → SFT → RFT.
Boxplot Comparison
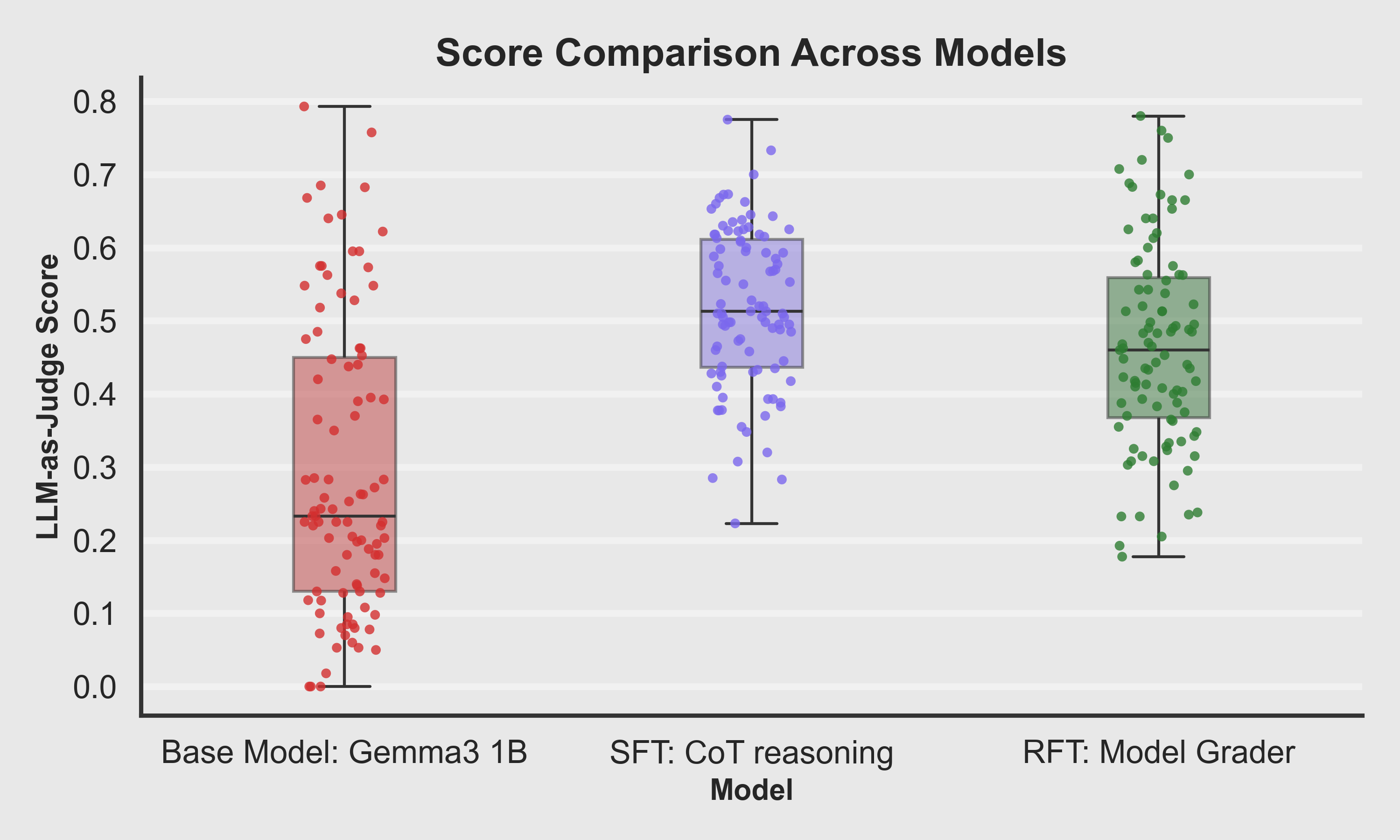
- Median score jumps significantly from Base → SFT.
- RFT retains a higher median than the base model, and its interquartile range sits above most of the Base distribution.
- Outliers reveal that:
- Base occasionally gets lucky with a good scene.
- SFT and RFT more reliably hit decent quality, with fewer catastrophic failures.
Key Takeaway: Fine-tuning doesn't just help a few cherry-picked cases—it shifts the overall quality level up.
Hero Examples
Compare the output of the Base model, SFT model, and the final RFT model. Notice how the RFT model captures the specific "mockumentary" style and character voices much better. Each model column includes a qualitative analysis showing the progressive improvement from Base → SFT → RFT.
Model Comparison
Michael Fakes Productivity with Pam's Post-its
Michael uses Pam’s Post-It notes to avoid work calls and appear busy in his office.
Michael, Pam, Oscar, Kevin, Ryan, Jan
Dunder Mifflin Scranton branch, Michael's office area
Analysis
Base model stays in meta 'reasoning' mode instead of delivering a scene.
Analysis
SFT introduces a playable scene with Michael dodging responsibility using Post-its.
Analysis
RFT sharpens Michael's voice, adds better visual gags around the notes, and leans into Pam's dry reactions and Oscar's grounded commentary.
Click on a column to highlight it. The final model typically shows the best performance.
Detailed Training Specifications
Training Pipeline Overview
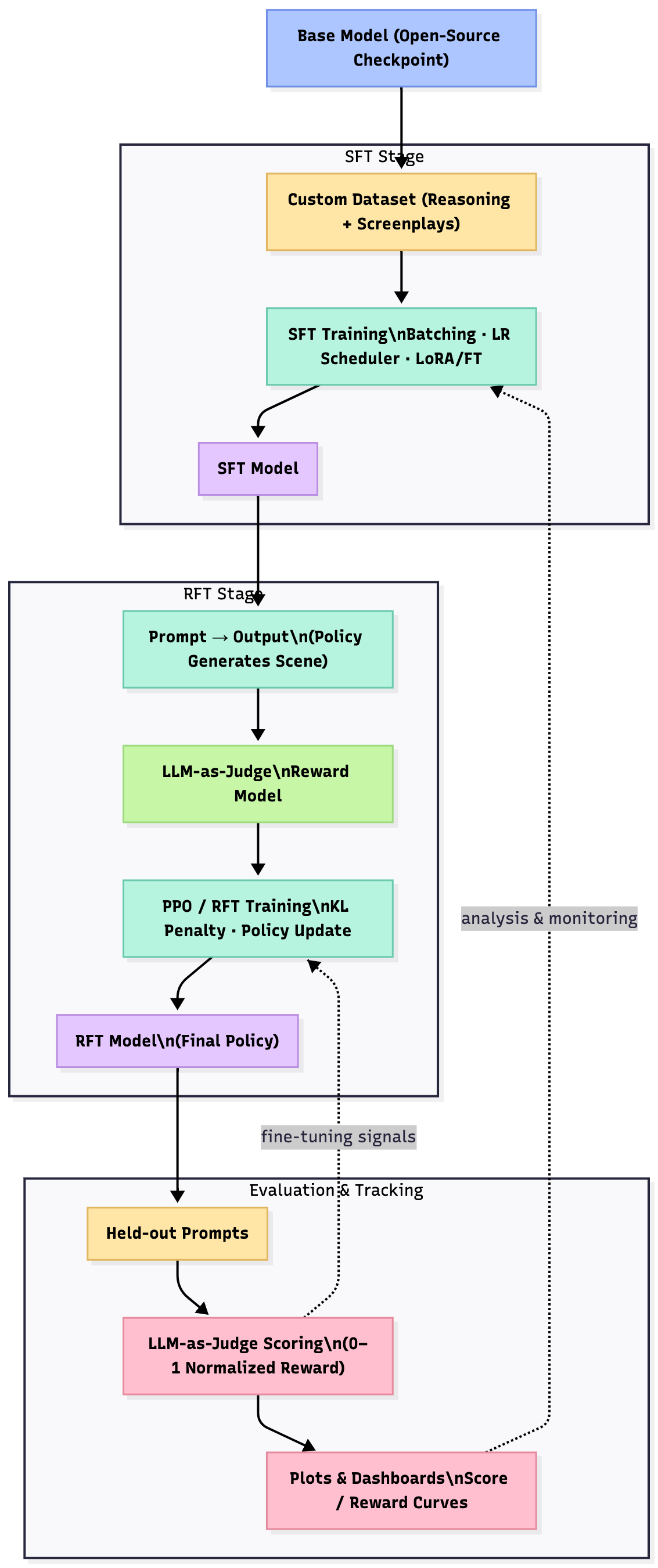
The complete training pipeline flows from a base open-source model through SFT (supervised fine-tuning on custom reasoning + screenplay data) to RFT (reinforcement fine-tuning with PPO using LLM-as-judge rewards). Continuous evaluation and monitoring ensure quality improvement at each stage.
Data Preparation
Training Dataset
Total Scenes
500 reasoning-chain + screenplay pairs
Evaluation Set
100 held-out prompts
Format
Structured reasoning trace + screenplay
SFT (Supervised Fine-Tuning)
Training Epochs
3
Total Steps
48
Batch Size
8
Learning Rate
5e-05 → 1.16e-06
Optimizer
AdamW
Best Checkpoint
Step 45
Fine-tuning Method
LoRA (r=128, α=128)
Training Loss
2.558 → 2.161
Eval Loss
2.478 → 2.311
Hardware
1 x A40 [48 GB VRAM]
Frameworks
TRL, Unsloth, PyTorch
RFT (Reinforcement Fine-Tuning with PPO)
Reward Model
LLM-as-judge (GPT-5)
Training Steps
130
Batch Size
4
Learning Rate
3.8e-06 → 2.78e-06
KL Divergence
0.15 - 0.46
Reward Progression
0.419 → 0.523
Completion Length
182-878 tokens
Total Tokens
~2.88M
Gradient Clipping
Applied
Key Learnings
This project touches most parts of the modern LLM lifecycle:
Problem Framing
Turn a fuzzy idea ("Office-style scenes") into a concrete objective with measurable rewards.
Custom Data Design
Design a reasoning + screenplay schema. Build prompts and reference scripts to teach the model structure and style.
Supervised & Reinforcement Fine-Tuning
Run SFT to anchor the model in domain behavior. Layer RFT on top to align with a style-aware judge.
Evaluation & Visualization
Implement LLM-as-judge scoring. Visualize distributions (boxplots, histograms) and training reward curves. Curate hero examples that connect metrics to human-perceived quality.
Storytelling & Product Thinking
Package the work as a case study that looks like a product launch: clear problem definition, before/after comparisons, visuals that non-experts can understand.
From Demo to Product: Agentic ScriptWriter Assistant
This trained model demonstrates the foundation for a real-world AI-powered screenwriting co-pilot—a tool for aspiring writers, professional screenwriters, and showrunners to accelerate their creative process while maintaining artistic control.
Instead of replacing writers, the system acts as an intelligent collaborator that helps execute ideas, ensures consistency, and handles the mechanical aspects of screenplay formatting while the human focuses on story and vision.
Core Product Architecture
Story Architect Agent
Brainstorming & Structure Planning
The entry point for writers. This agent helps develop high-level story concepts into structured narratives.
User Input
- • Rough situation ideas
- • Character preferences
- • Comedic tone requirements
Agent Output
- • Beat-by-beat scene structure
- • Character dynamics map
- • Multiple story variations
Screenplay Generator Agent
Dialogue & Scene Execution
This is where our trained RFT model powers the system. Takes the structured reasoning trace and generates production-ready screenplay with authentic character voices.
Leverages Training
- • Character consistency (25% weight)
- • Show-specific humor (25% weight)
- • Mockumentary format adherence
User Controls
- • Regenerate specific sections
- • Adjust character focus
- • Tune comedic intensity
Continuity & Quality Guardian Agent
Script Review & Consistency Checking
Monitors the entire script across multiple scenes, ensuring character arcs, running gags, and show mythology remain consistent.
Automated Checks
- • Character voice drift detection
- • Timeline consistency validation
- • Callback/setup-payoff tracking
Feedback Loop
- • Flags inconsistencies for review
- • Suggests revisions
- • Learns from user edits (RLHF)
Dialogue Polish & Alternative Generator
Iterative Refinement
Provides alternative phrasings, comedic variations, and line-by-line improvements while preserving the writer's intent.
Features
- • A/B/C line variations
- • Punch-up suggestions
- • Timing/pacing adjustments
Writer Control
- • Accept/reject changes
- • Lock favorite lines
- • Set tone constraints
Why This Becomes a Real Product
⚡Speed Without Sacrificing Quality
Writers spend 70% of their time on mechanical work: formatting, ensuring consistency, rewriting dialogue variations. This system handles the grunt work, letting writers focus on creative decisions and story vision. What takes weeks in a traditional writers' room can be iteratively refined in days.
🎯Specialized Domain Models
Unlike generic LLMs, our fine-tuned models are experts in specific show formats. Train separate models for sitcoms, dramas, thriller formats—each deeply understanding the genre's unique storytelling patterns, pacing requirements, and audience expectations.
🔄Continuous Improvement via RLHF
Every writer edit becomes training data. When users accept/reject suggestions, the system learns their preferences. Over time, the agent adapts to individual writing styles while maintaining show-level consistency—creating a personalized co-pilot.
💰Clear Business Model
Subscription tiers: Aspiring writers get basic agents. Professional showrunners pay for multi-episode management, team collaboration, and custom model fine-tuning on their show's existing episodes. Studios license enterprise versions with proprietary IP training.
From Technical Demo to Market Reality
This case study proves the foundational tech works: we can fine-tune models to understand nuanced creative domains, evaluate quality with specialized judges, and generate content that improves measurably across training.
The product layer—agentic workflows, human-in-the-loop refinement, team collaboration tools—turns this technical capability into a tool that practicing writers would actually pay to use. It's not about automating creativity; it's about amplifying human storytellers with AI that understands their craft.