LLM Inference Engineering
A practical series on how large language model inference works in production: tokens, decode loops, caches, attention, batching, memory management, and serving economics.
4 modules · 14 chapters
Scope
Infrastructure Engineer
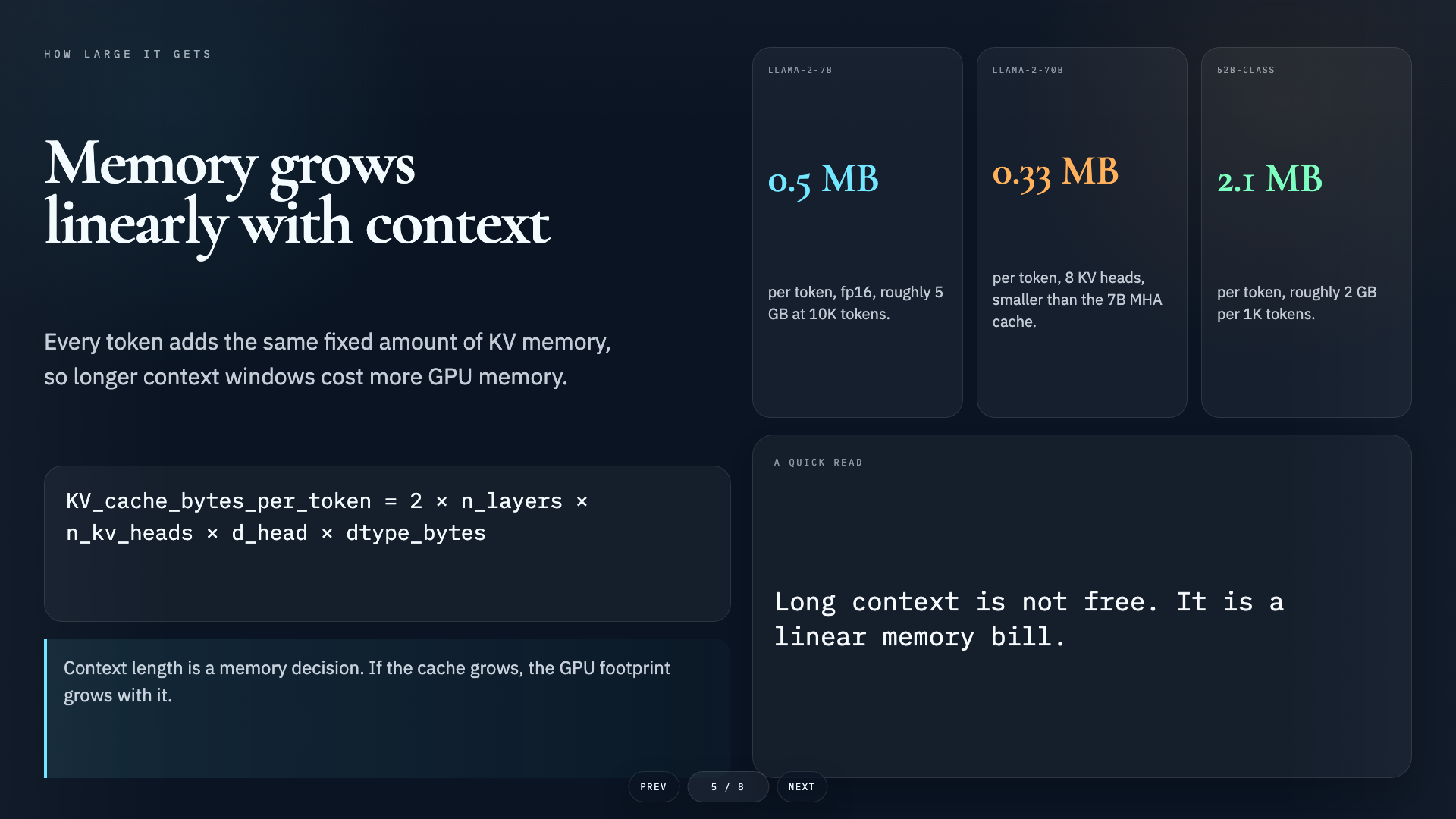
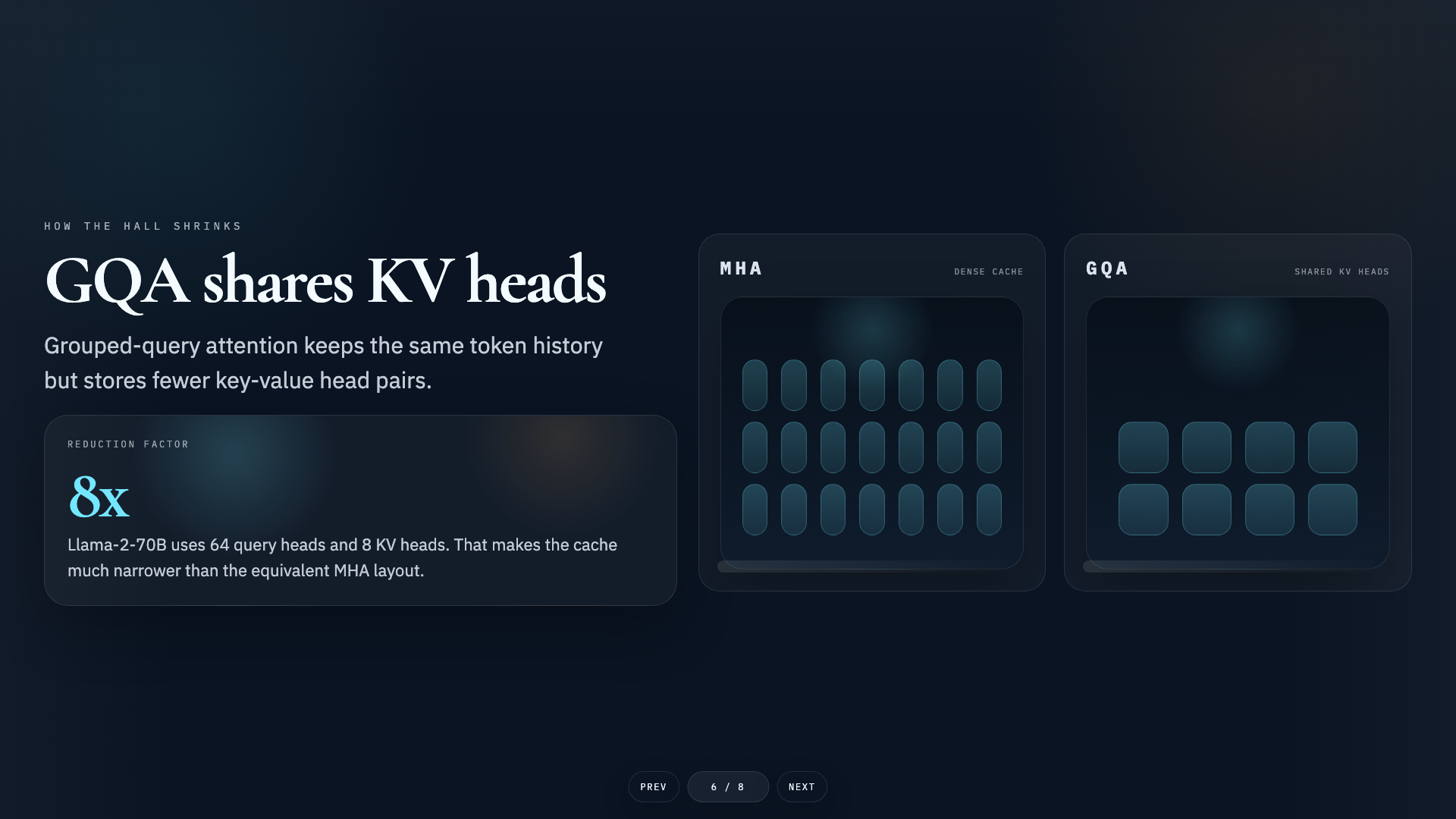
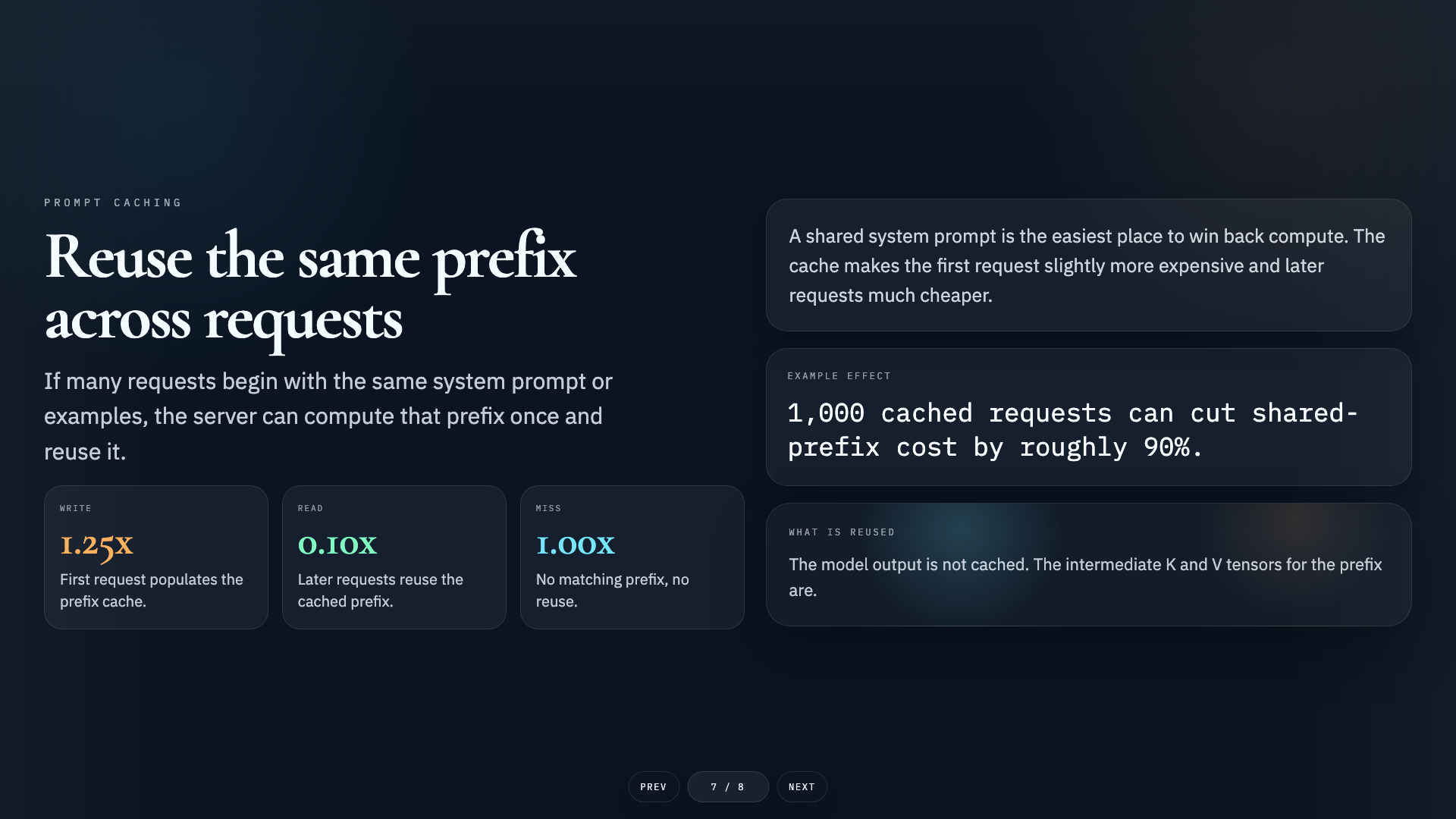
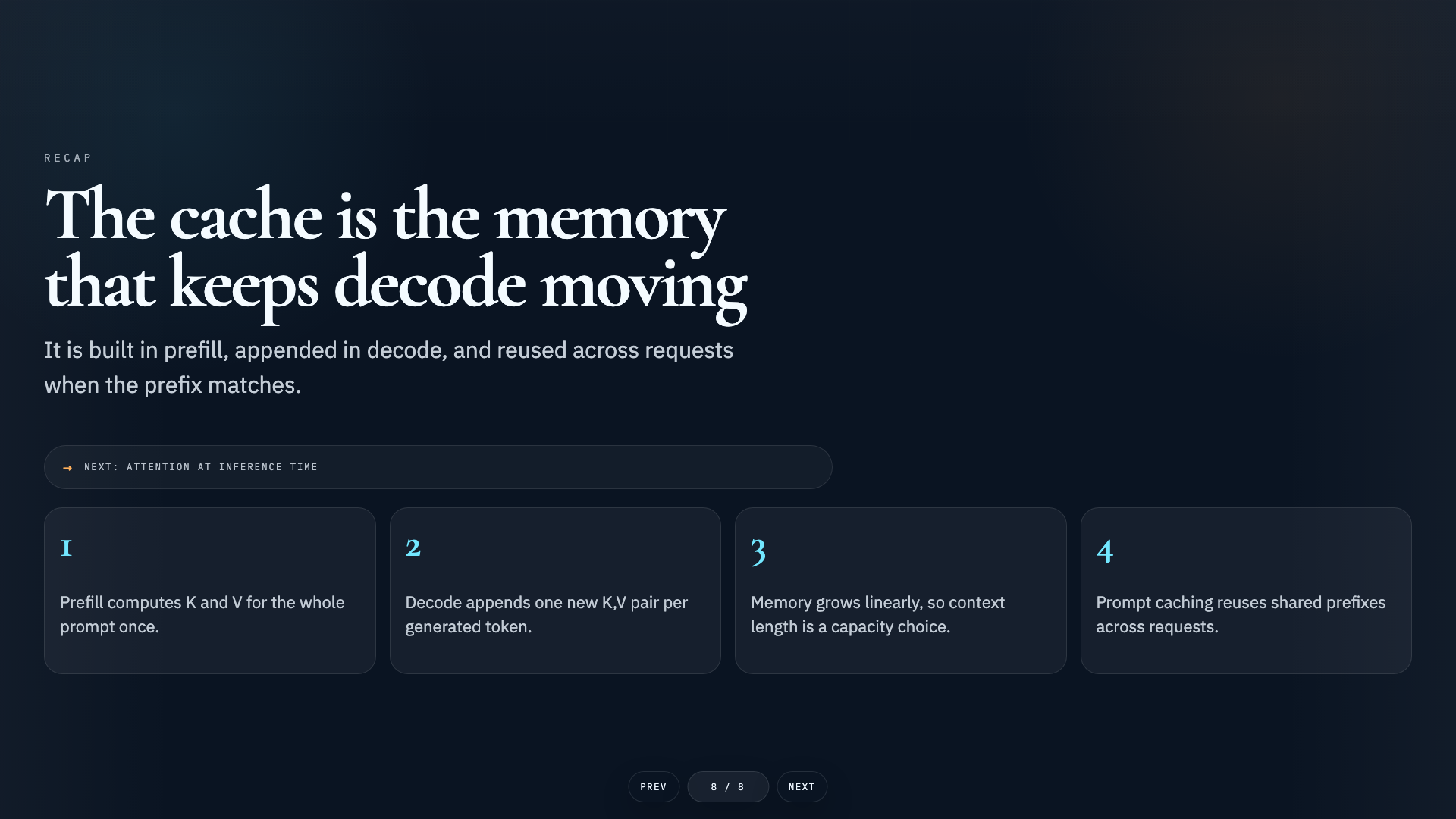
Audience
Book a complete training session
Contact to book complete training sessions including training slides, hands-on exercises, mini-projects, and capstone projects.
Curriculum
Foundations
How tokens, the first forward pass, and step-by-step generation set up the rest of inference.
- →You Hit Enter
- →Tokens - The LLM's Alphabet
- →One Word at a Time
- →Prefill vs Decode
Memory, Attention, and the Bottleneck
KV cache behavior, attention mechanics, and the hardware bottleneck that shapes decode.
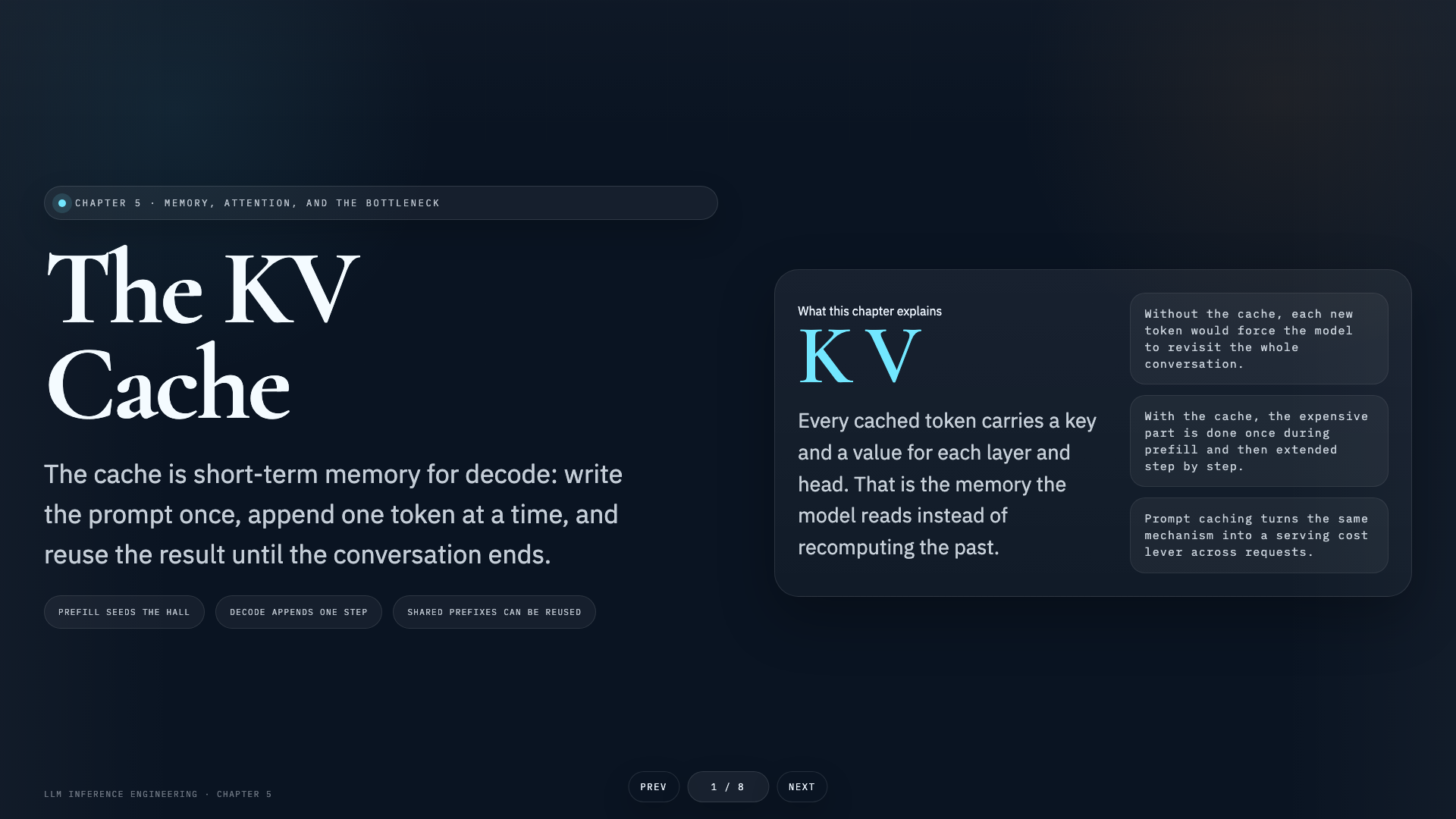
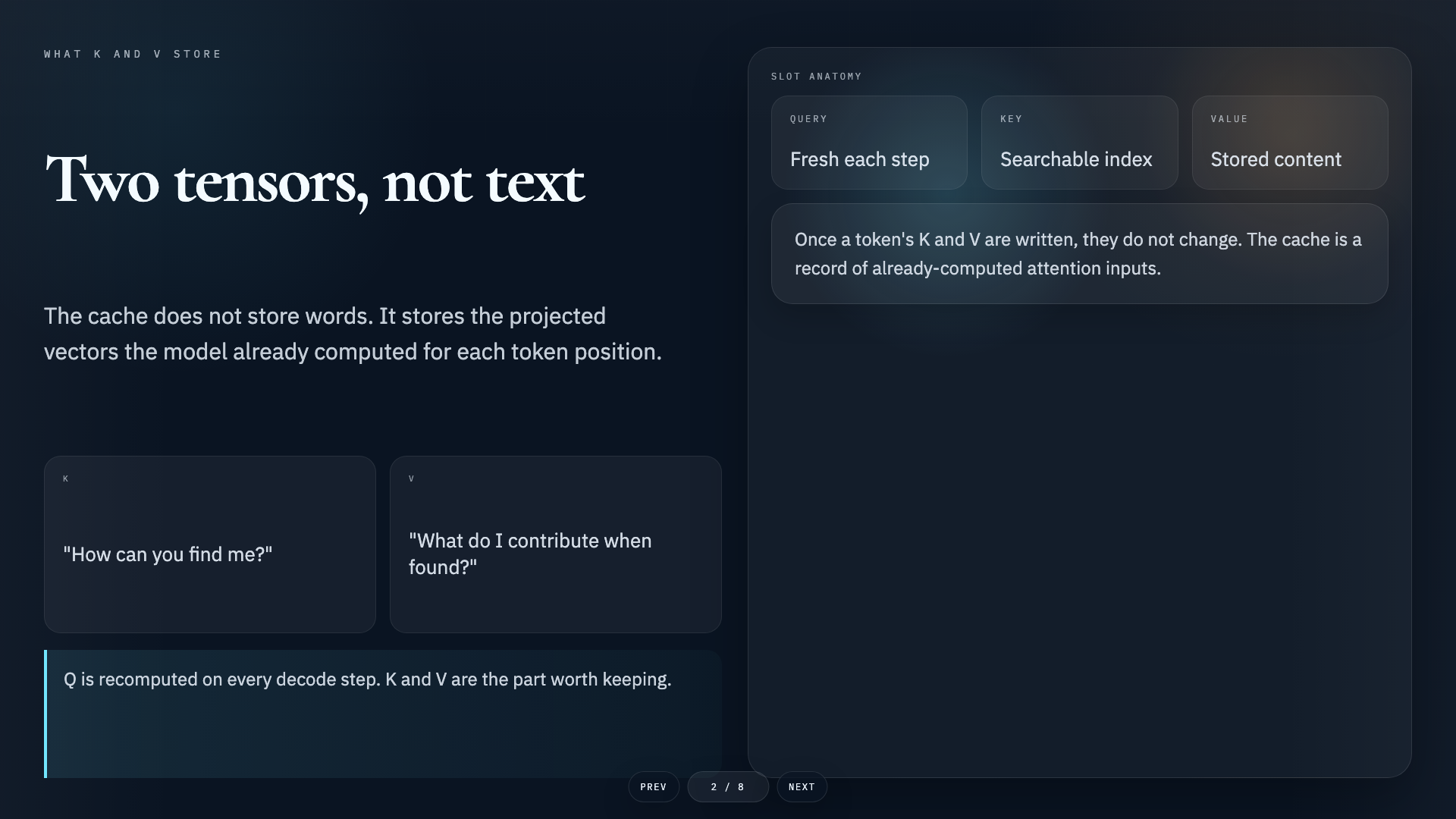
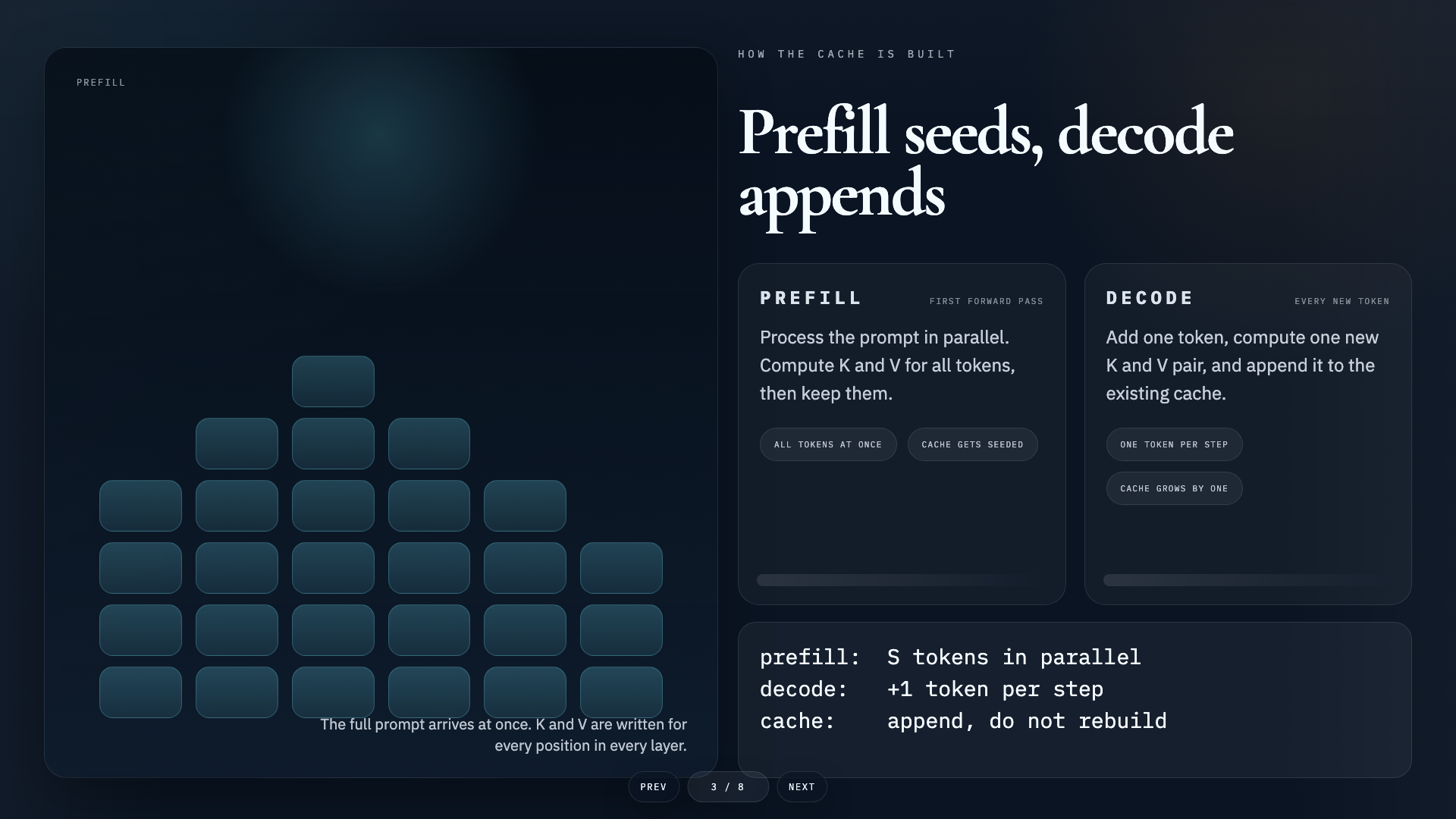
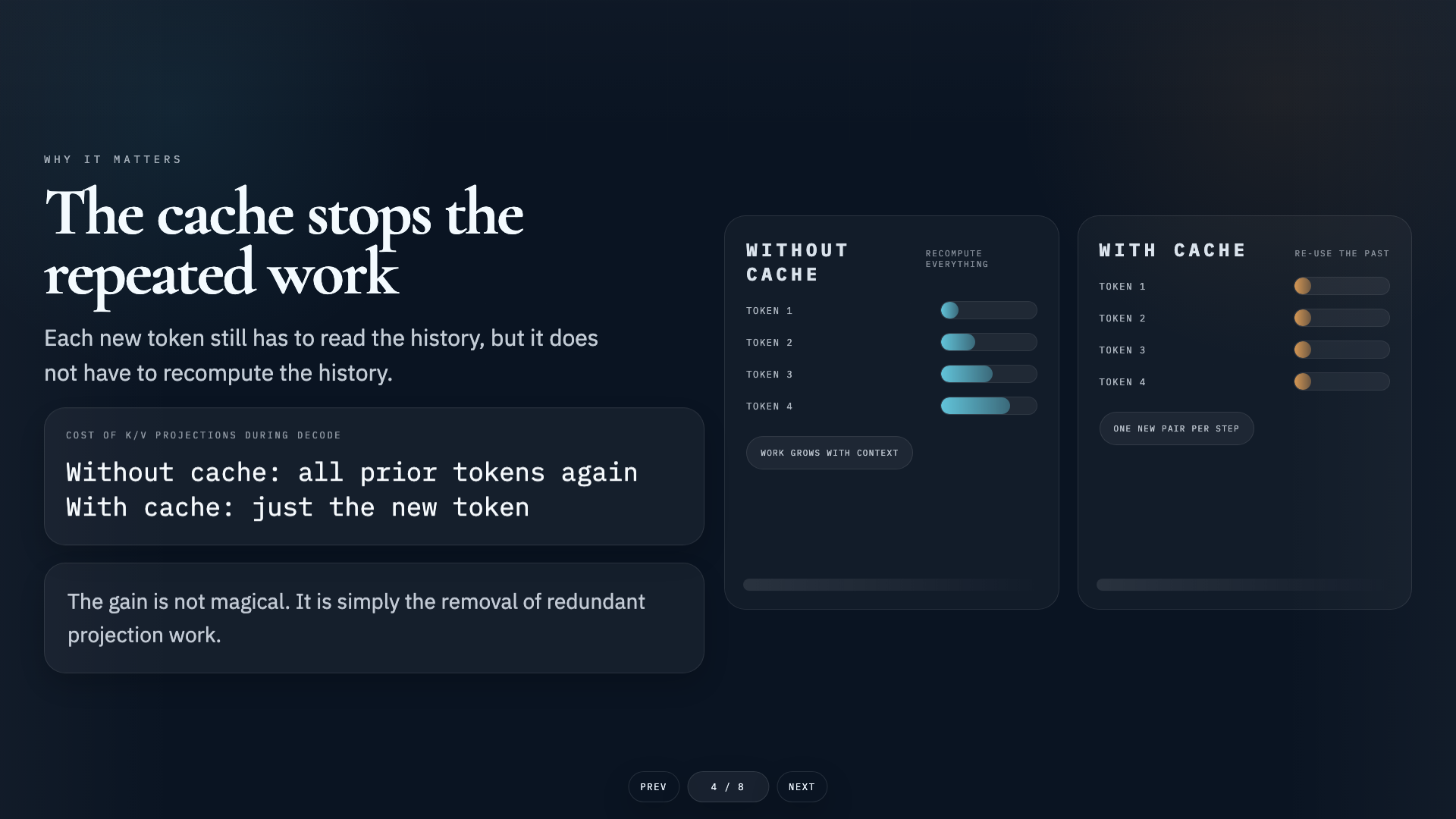
- →The KV Cache
- →Attention at Inference Time
- →The Memory Wall
Throughput, Batching, and Memory Management
Serving mechanics that raise utilization without breaking latency or memory limits.
- →Continuous Batching
- →PagedAttention
- →FlashAttention
Efficiency, Compression, and Economics
Faster decode, smaller caches, cheaper tokens, and the trade-offs that shape serving cost.
- →Speculative Decoding
- →Quantization
- →The Economics
- →Epilogue - The Full Journey
Sample Slides