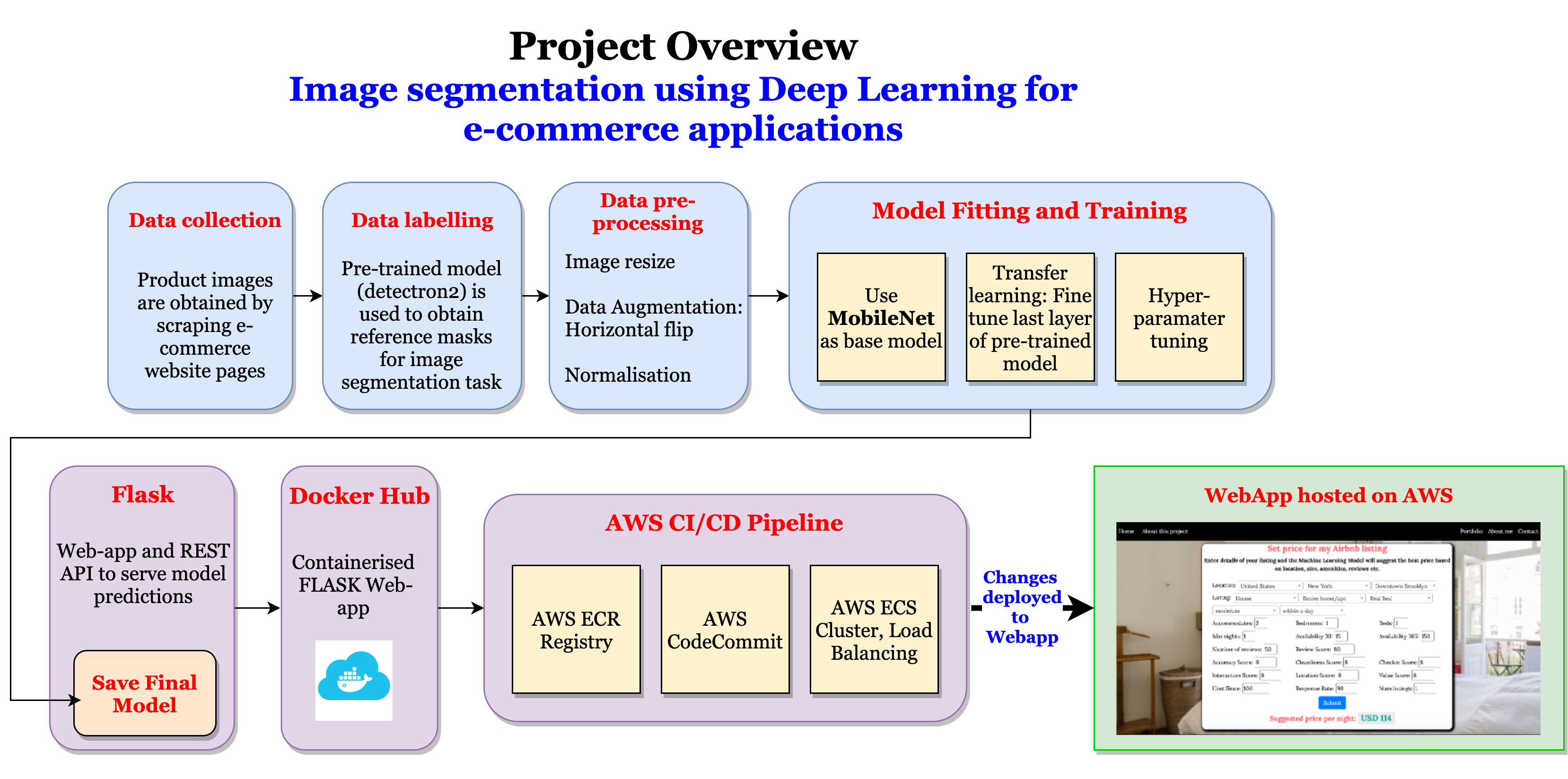
Project Overview: Image segmentation using Deep Learning for e-commerce applications
The project consisted of the following steps,
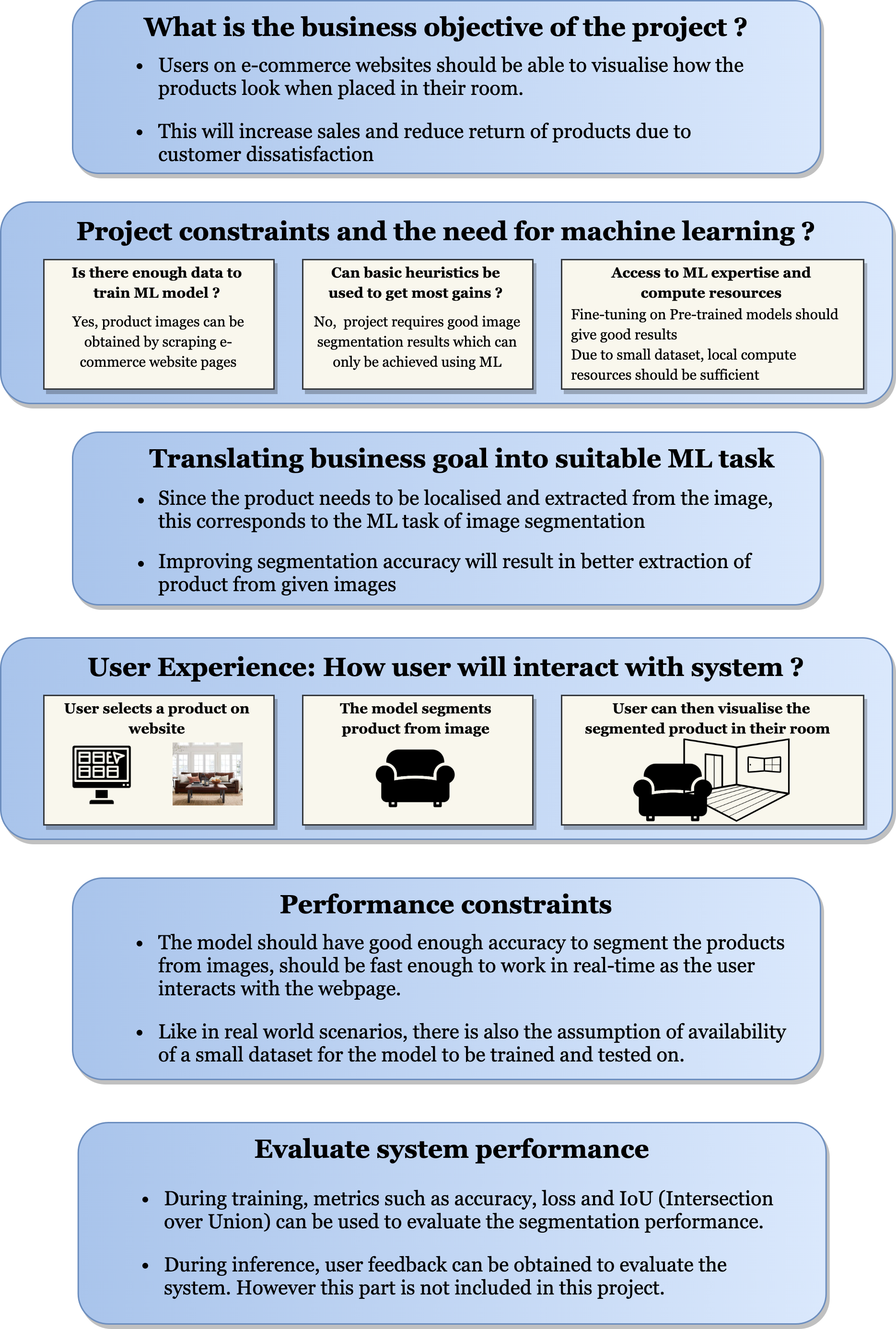
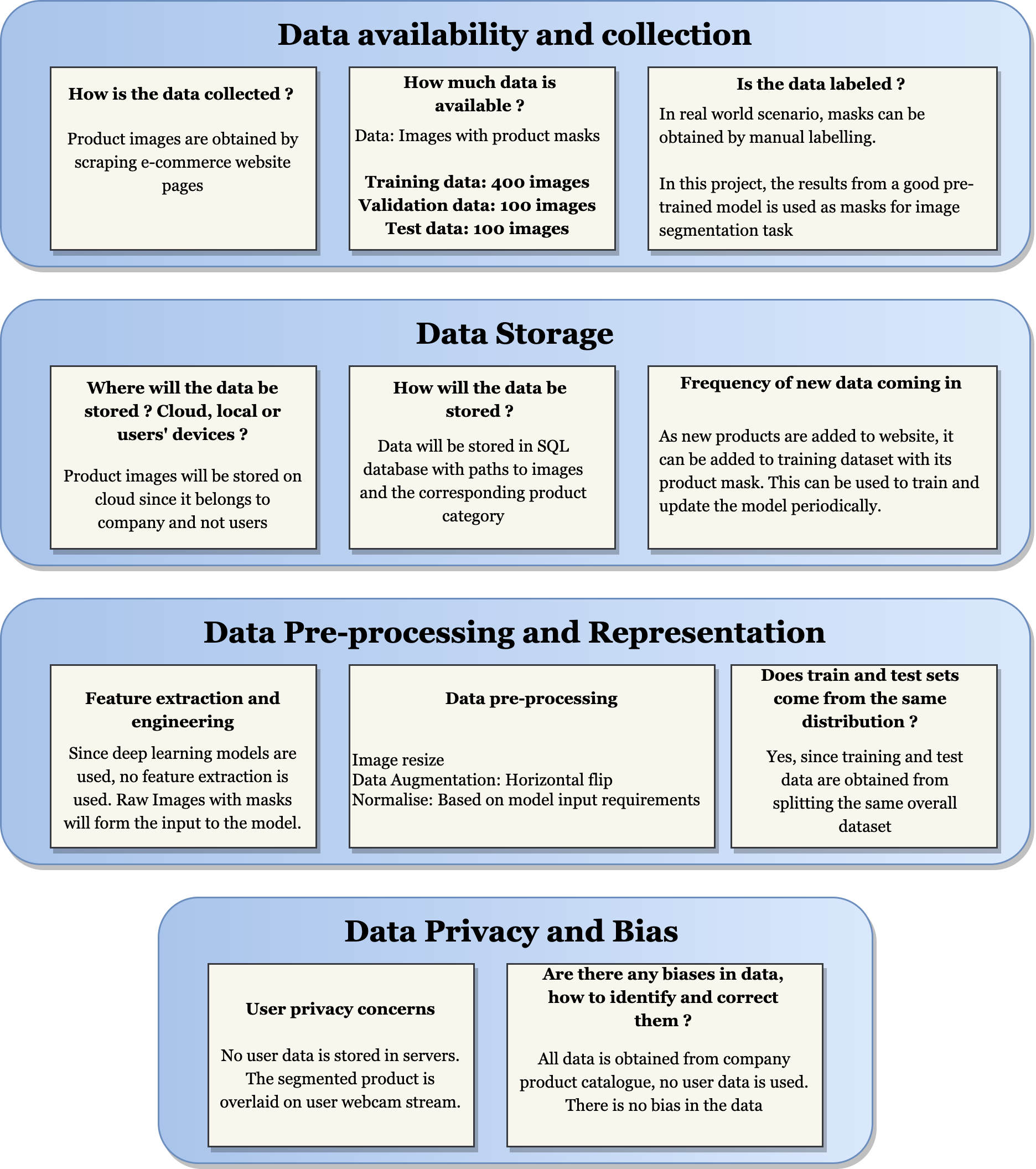
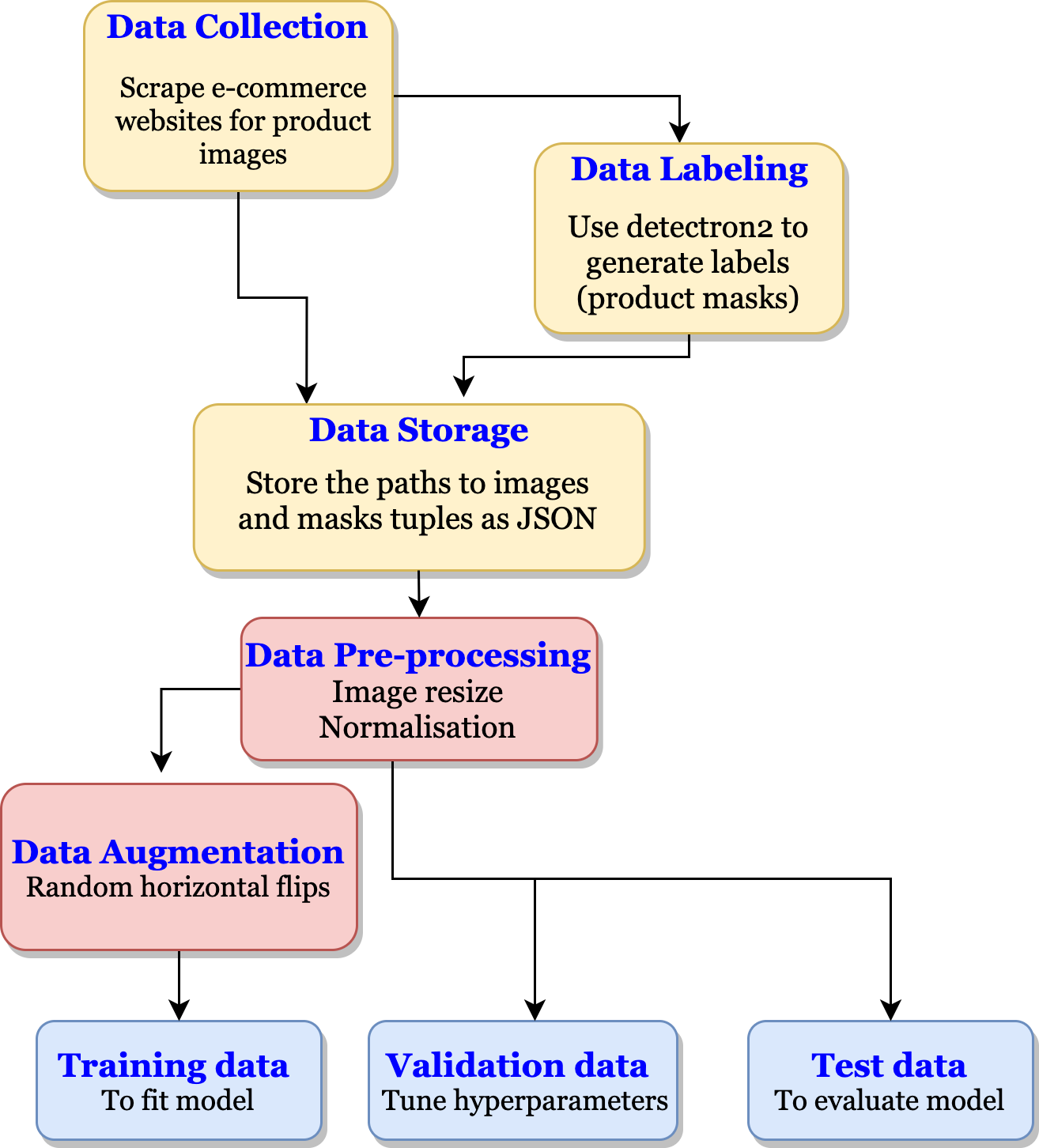
- Data Collection: Scraping product images from ecommerce websites
- Data Labelling: Using Detectron2 to obtain labels (masks) for training custom model
- Data Pre-processing: Image resize, Data augmentation, Normalisation
- Model Fitting and Training:
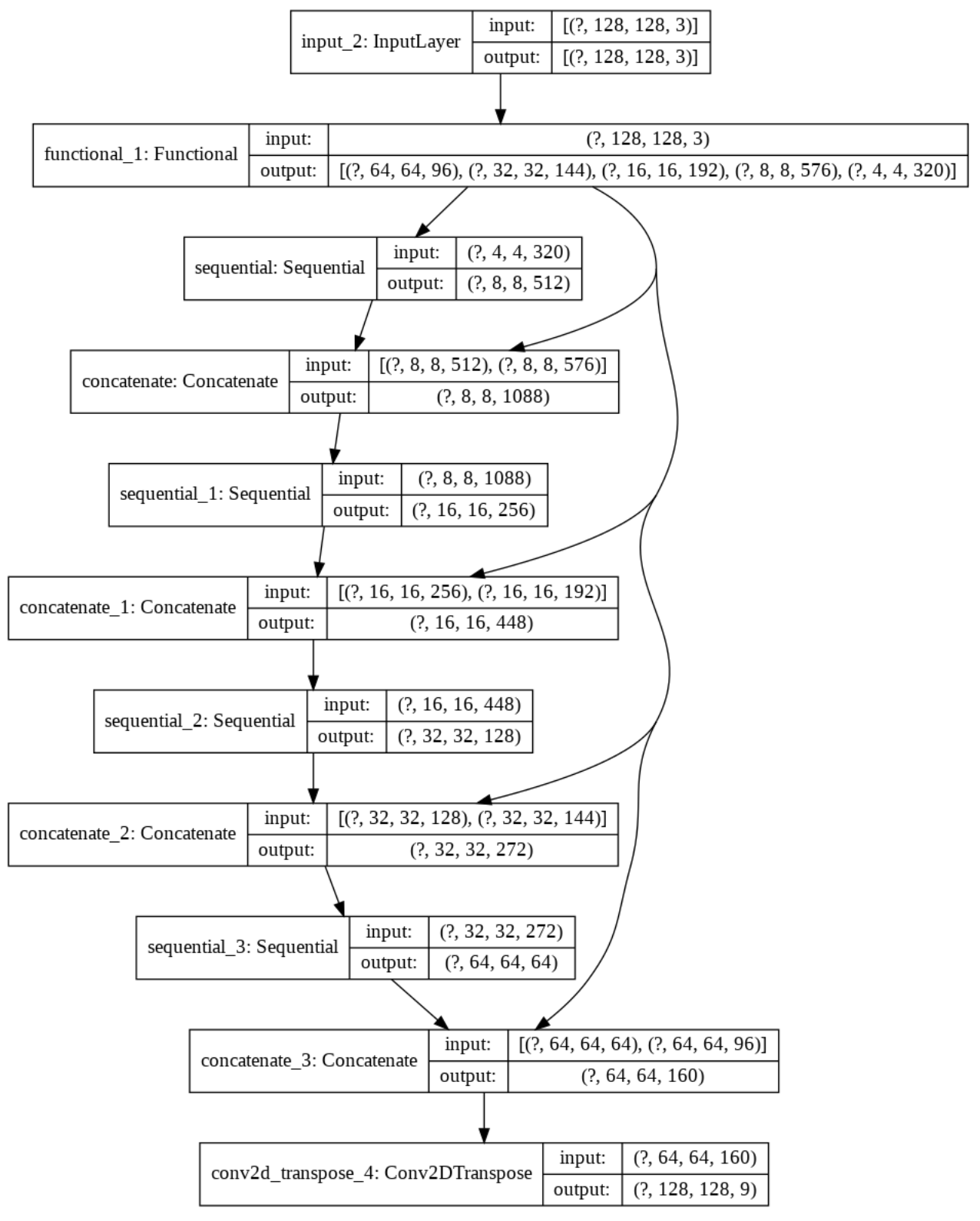
- Building image segmentation model using MobileNet as base model
- Fine-tuning last layer of pre-trained model
- Tuning hyperparameters
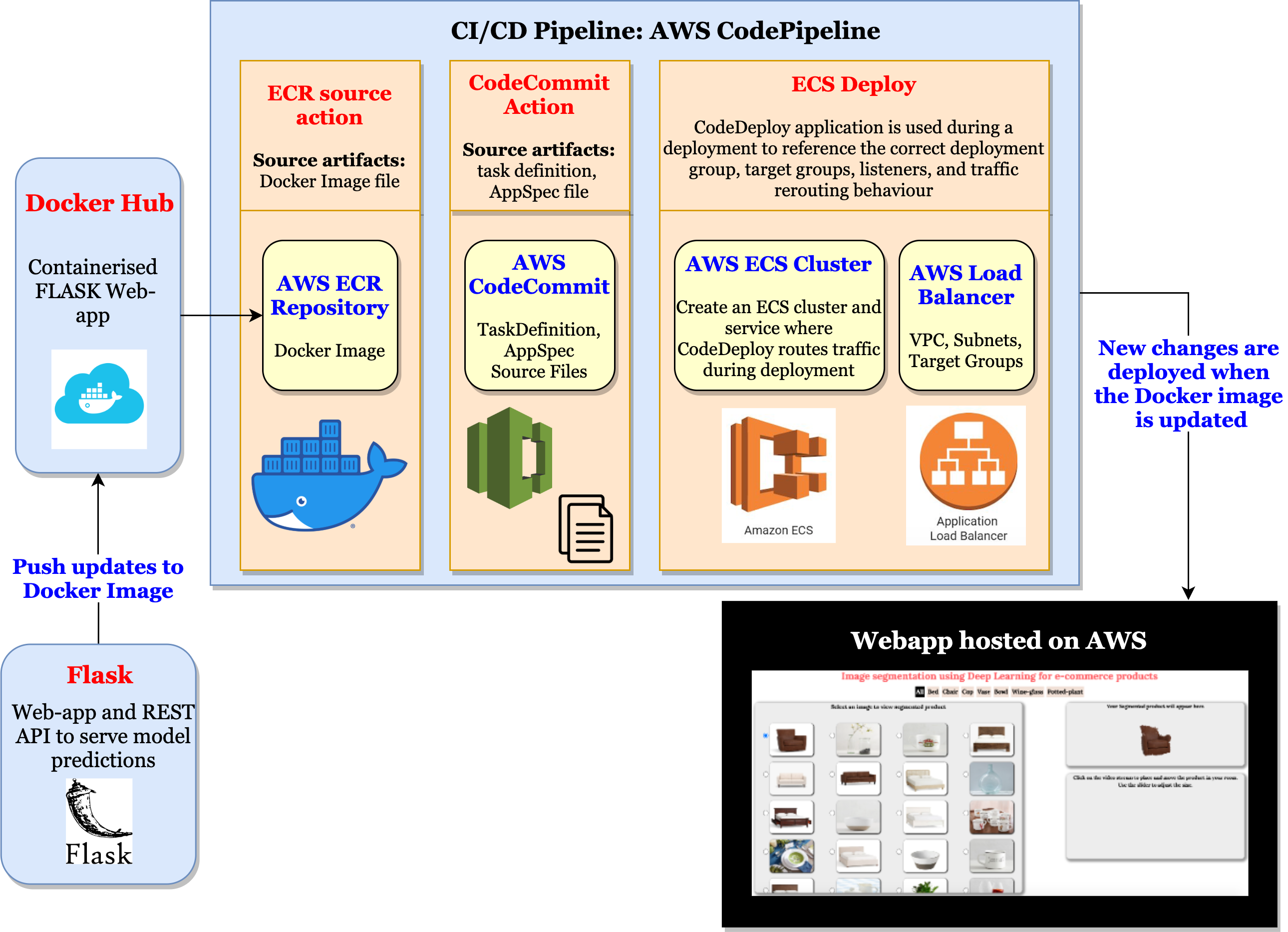
- Model Serving: Using FLASK to deploy and serve Model predictions using REST API
- Container: Using Docker to containerise the Web Application
- Production: Using AWS CI/CD Pipeline for continuous integration and deployment.
The project documentation has the following sections:
- Project Setup
- Data Setup
- Modeling
- Setting up Metrics
- Setting up Baseline Models
- Transfer Learning: Fine-tuning pre-trained model
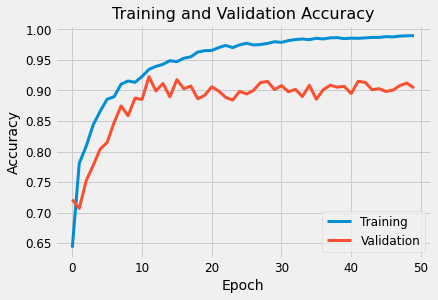
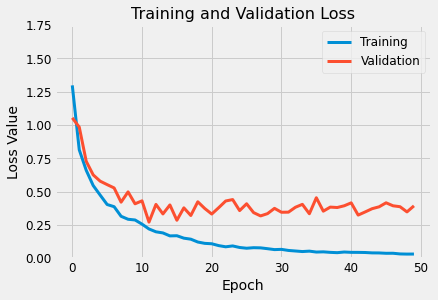
- Model Training
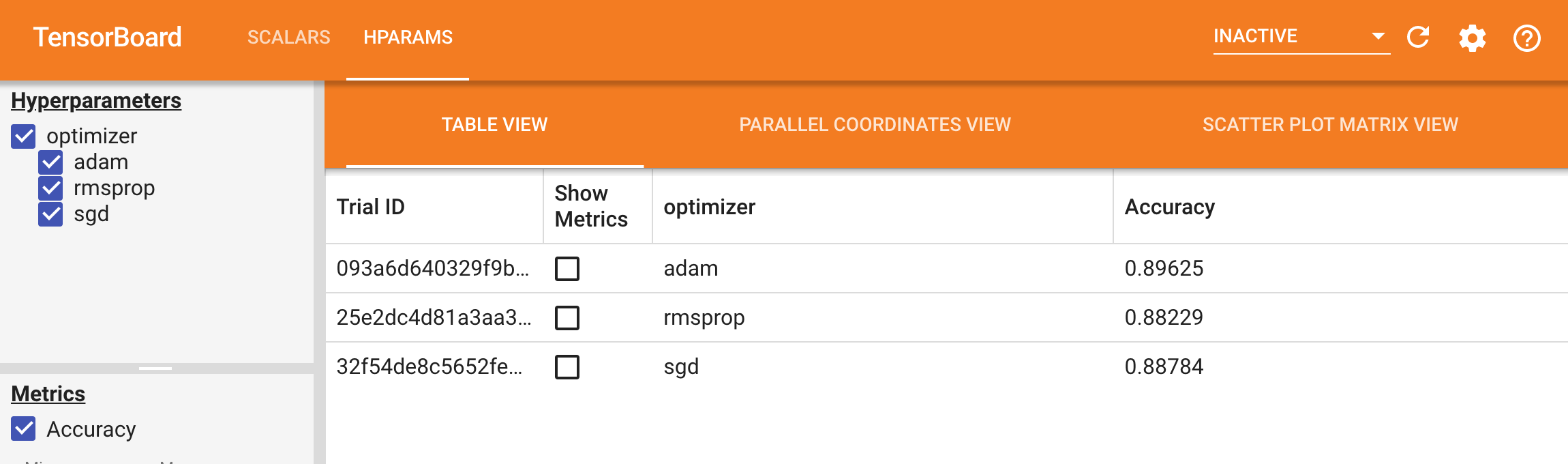
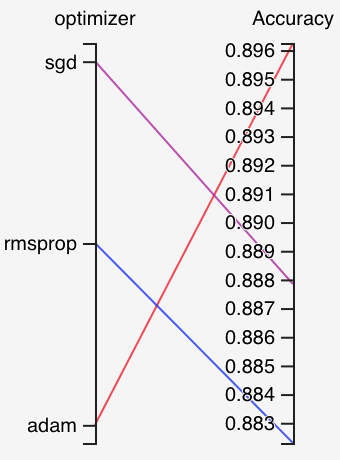
- Hyperparameter tuning
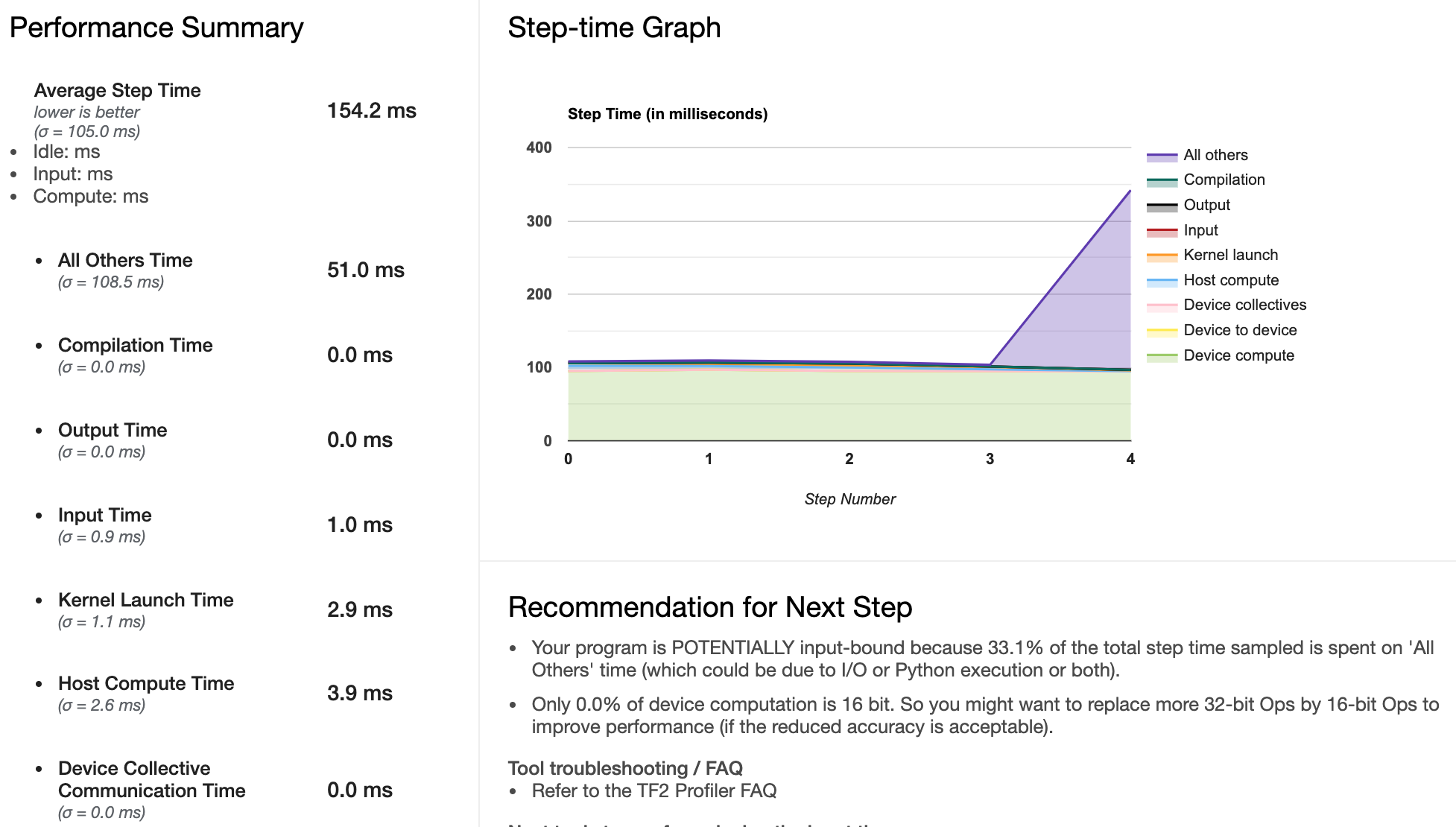
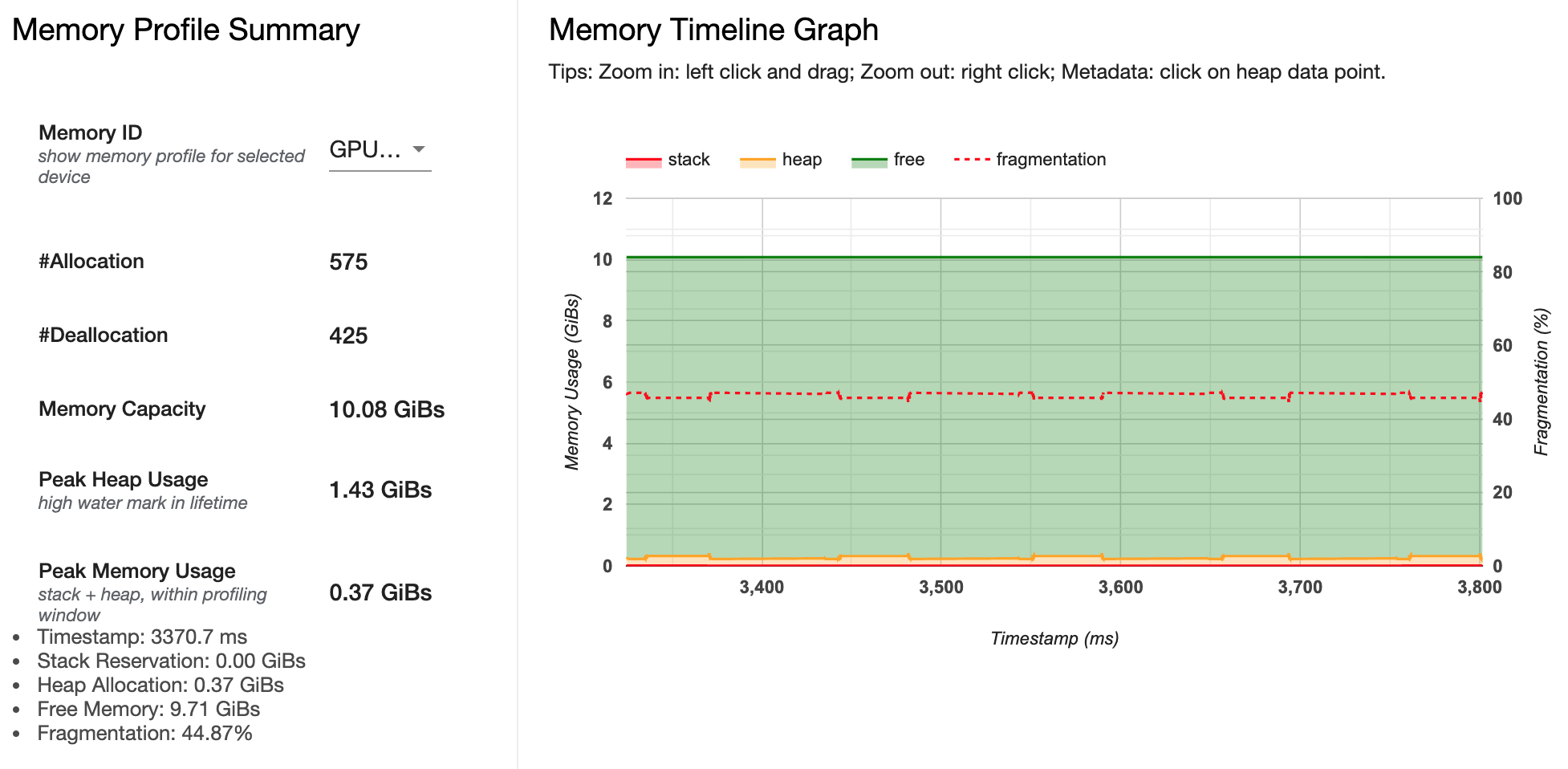
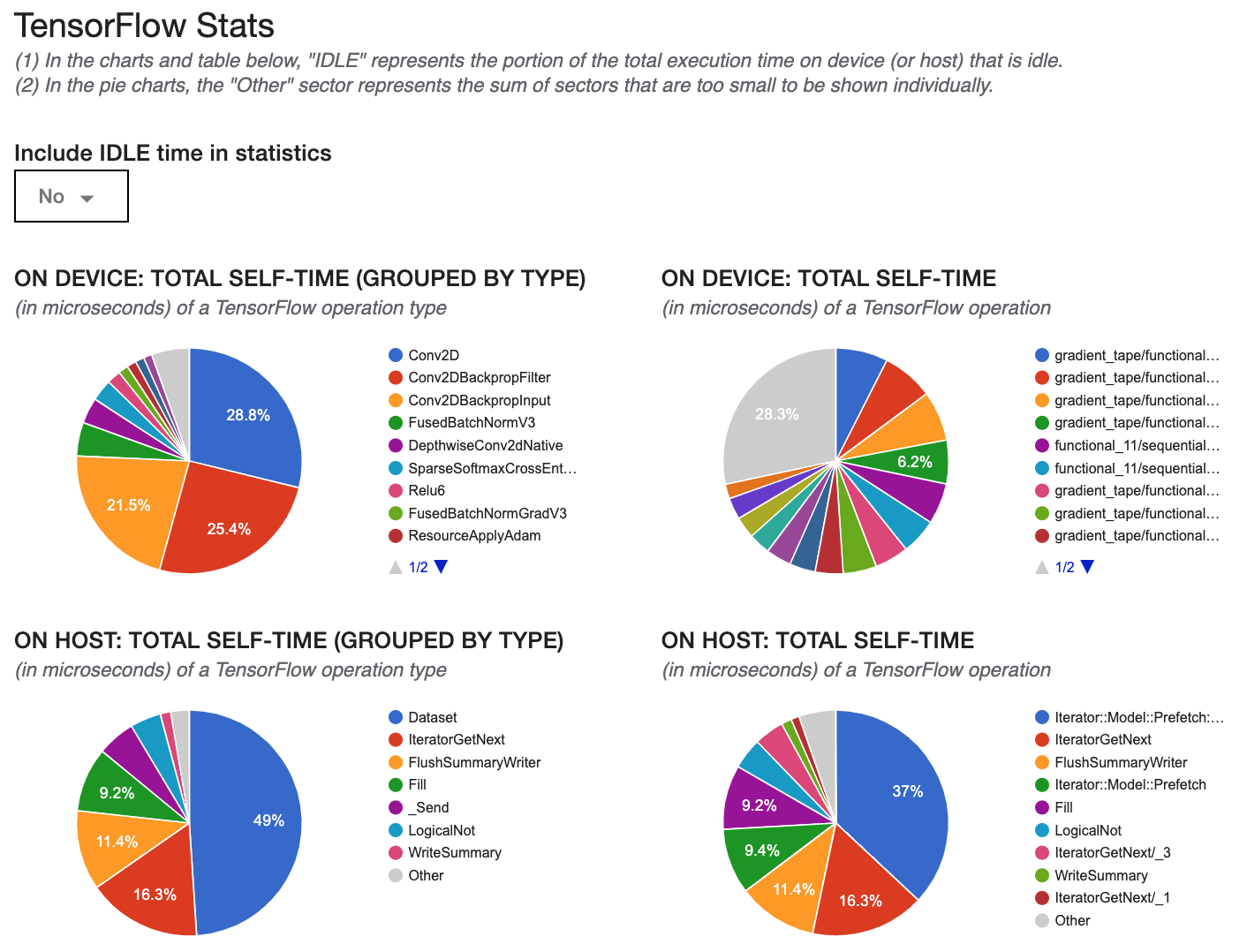
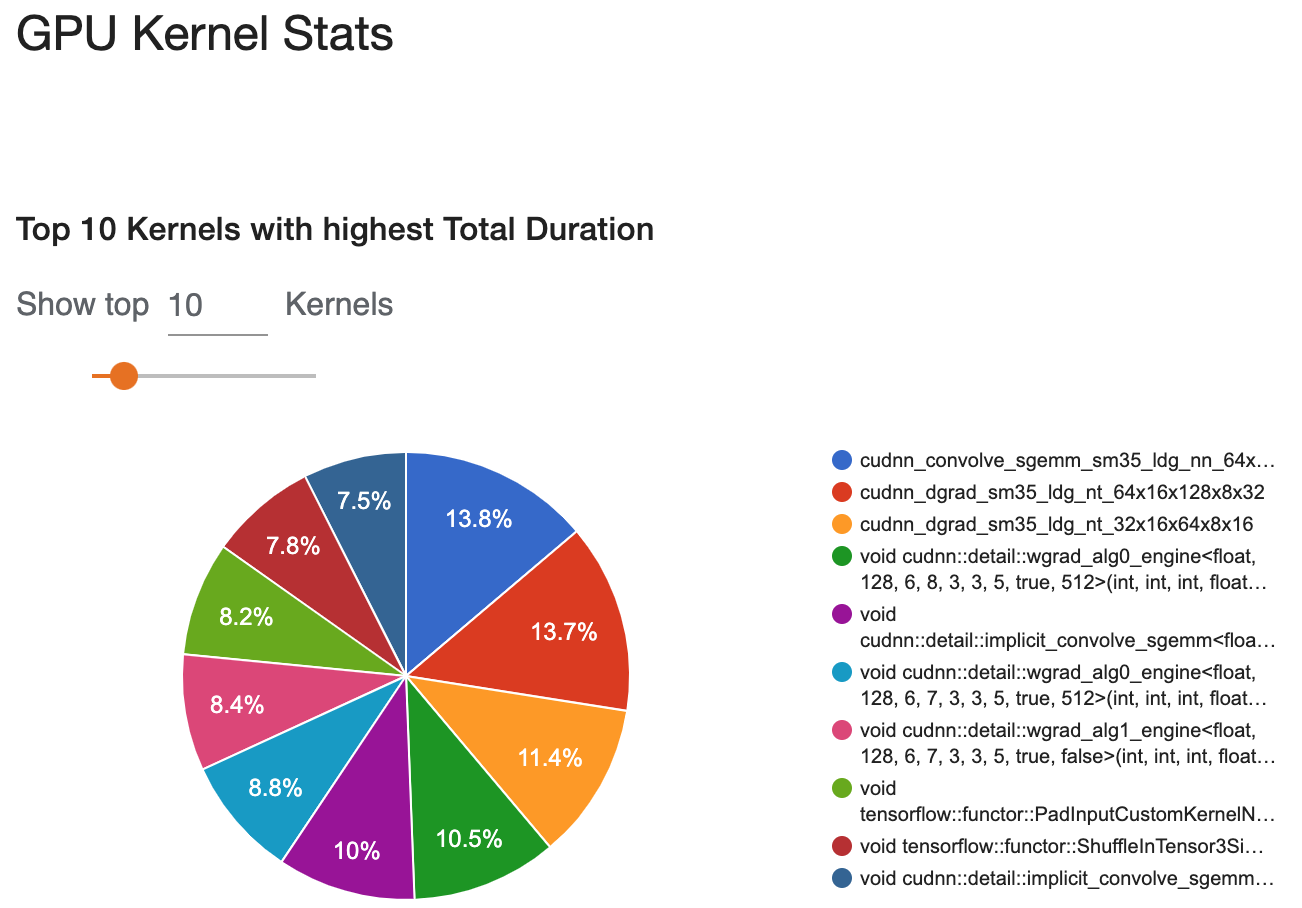
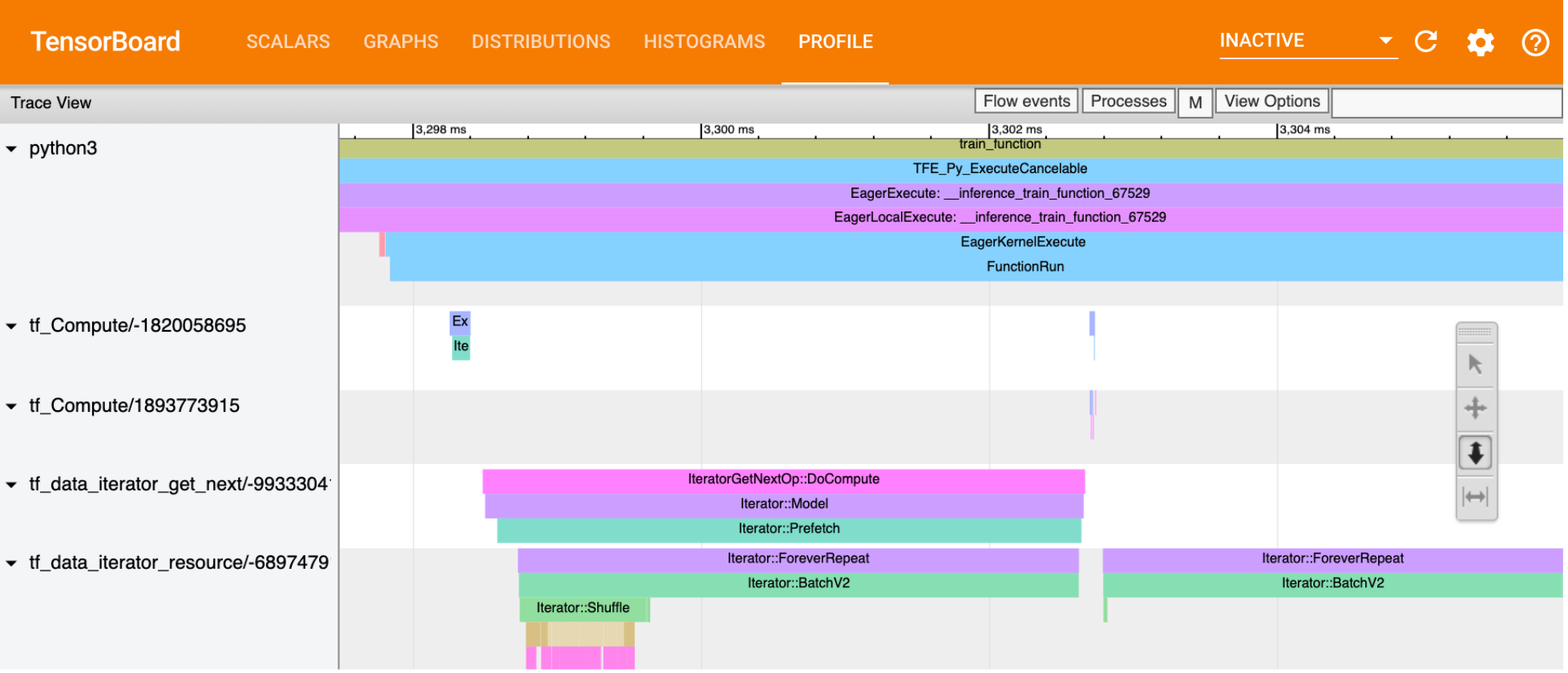
- Profiler
- Input data pipeline for Model
- Logging custom data to Tensorboard
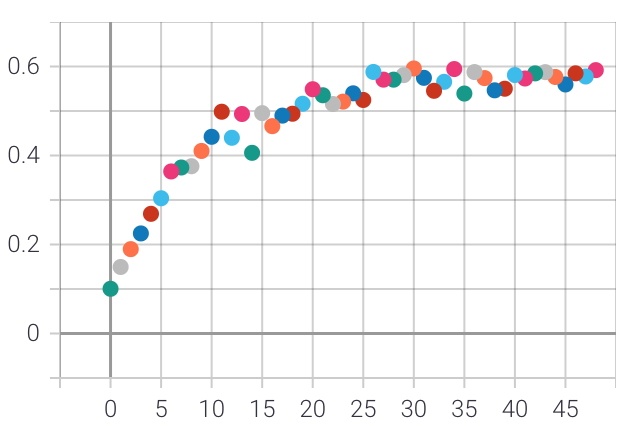
- Model learning
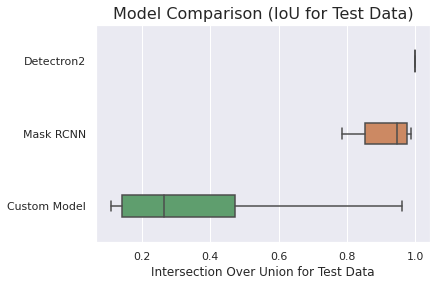
- Model Comparison and Selection
- Model Quantisation
- Saving Model for Serving
- Model Predictions
- Deployment and Production Setup
- Conclusion, Challenges and Learnings