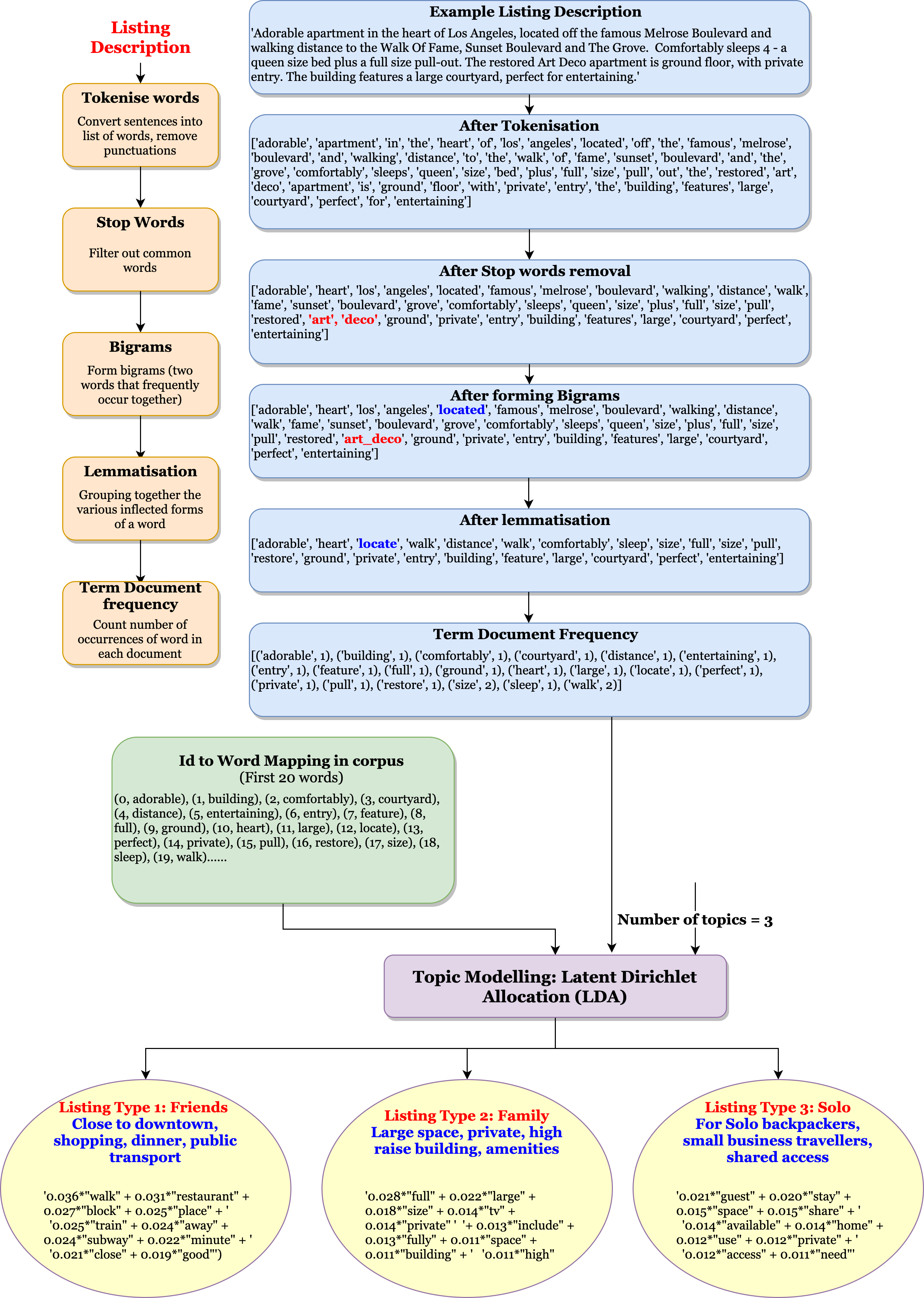
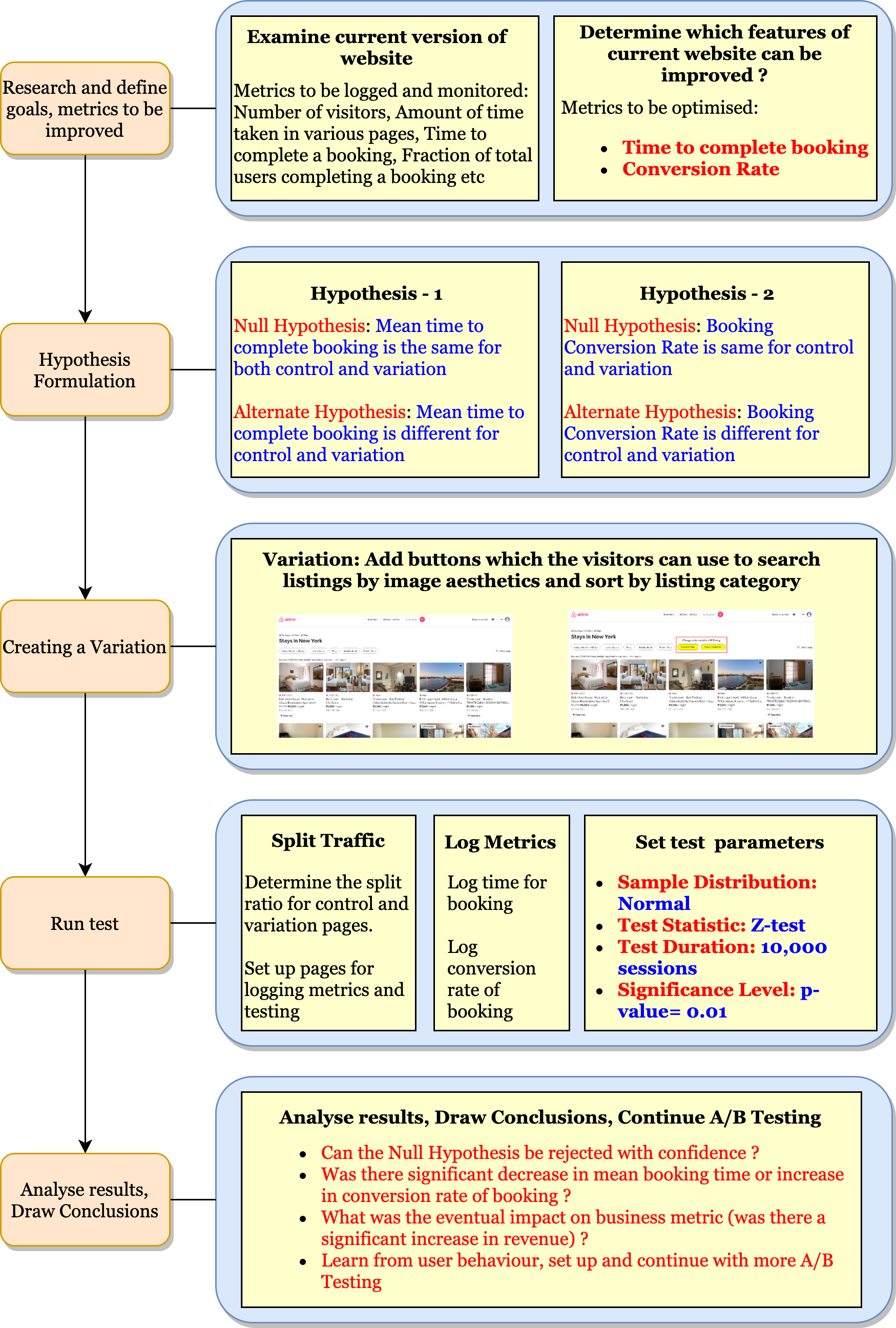
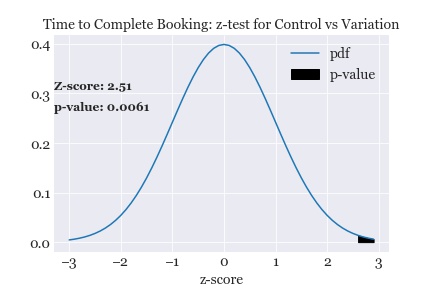
Search by Image Aesthetics: Using pre-trained Deep Learning Model to assess image quality
Why search by image quality and aesthetics ?
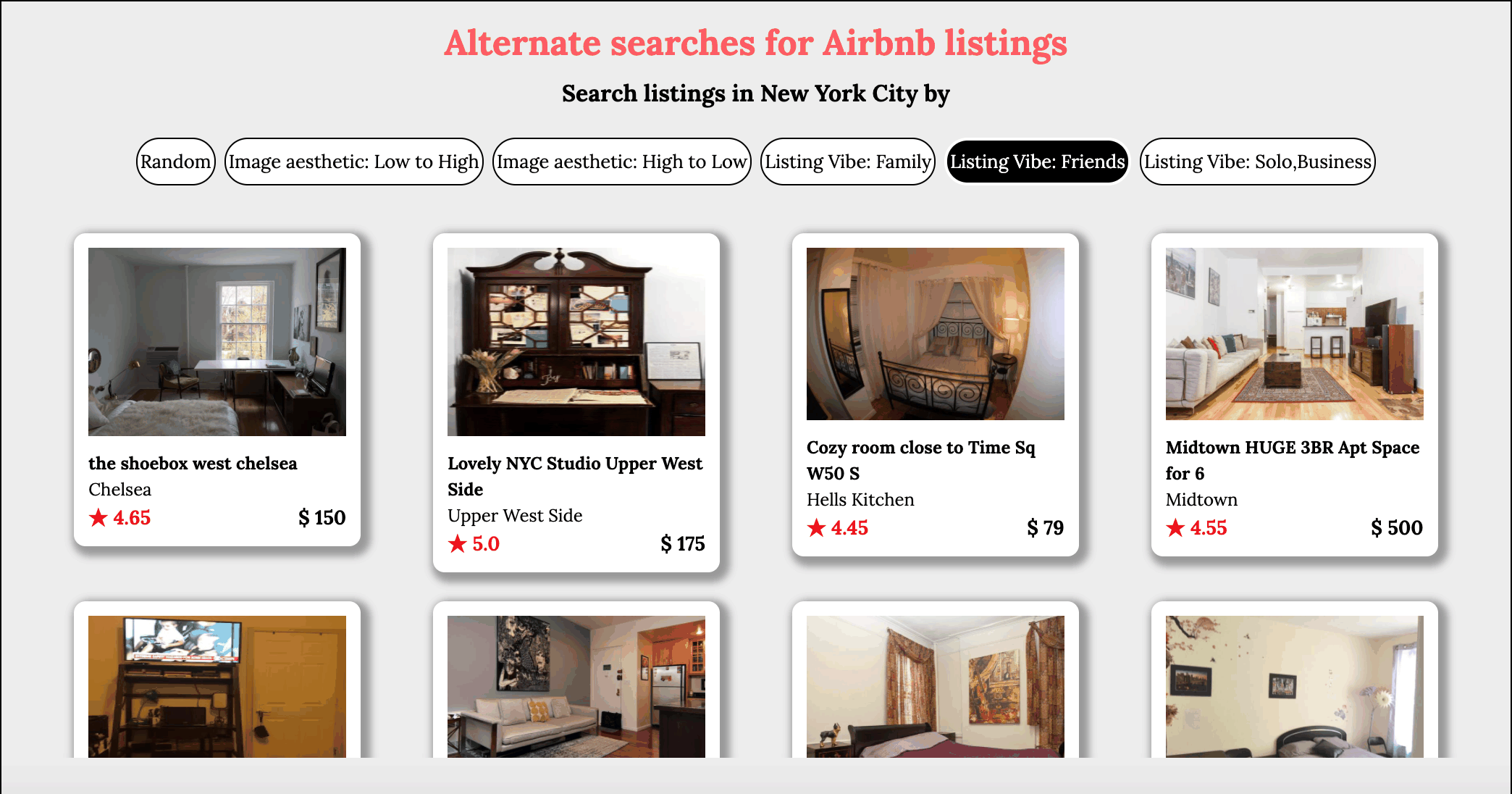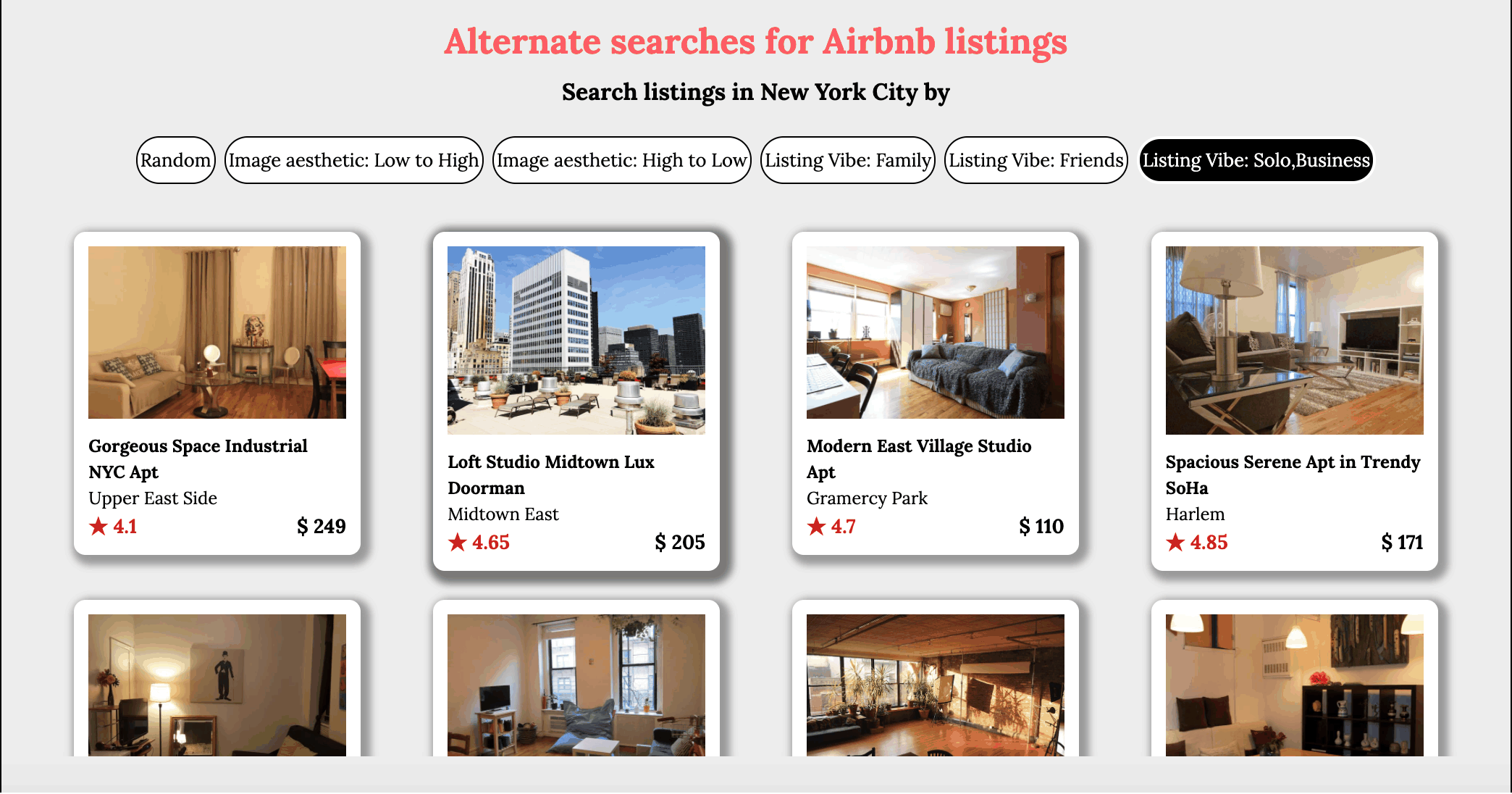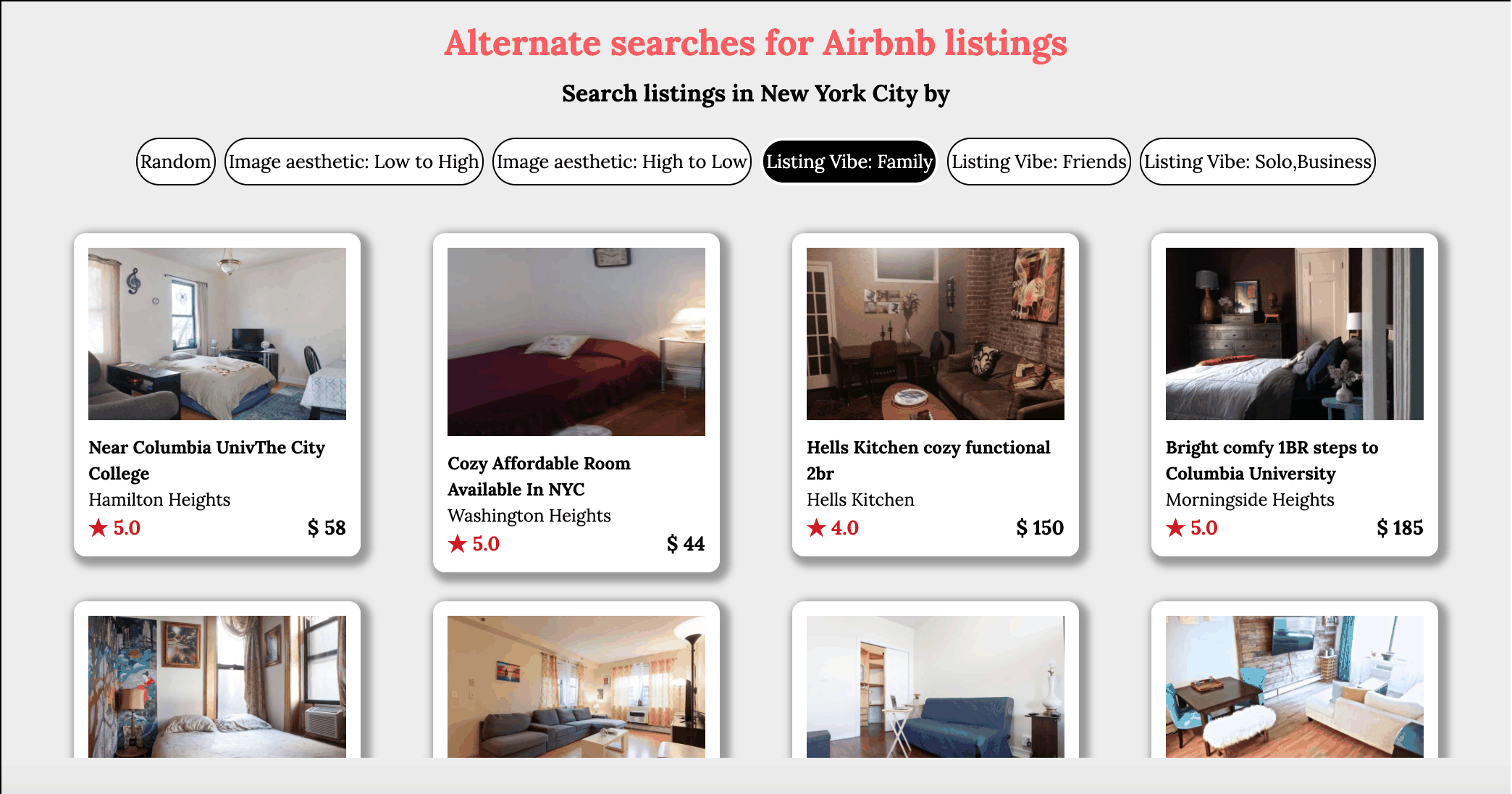
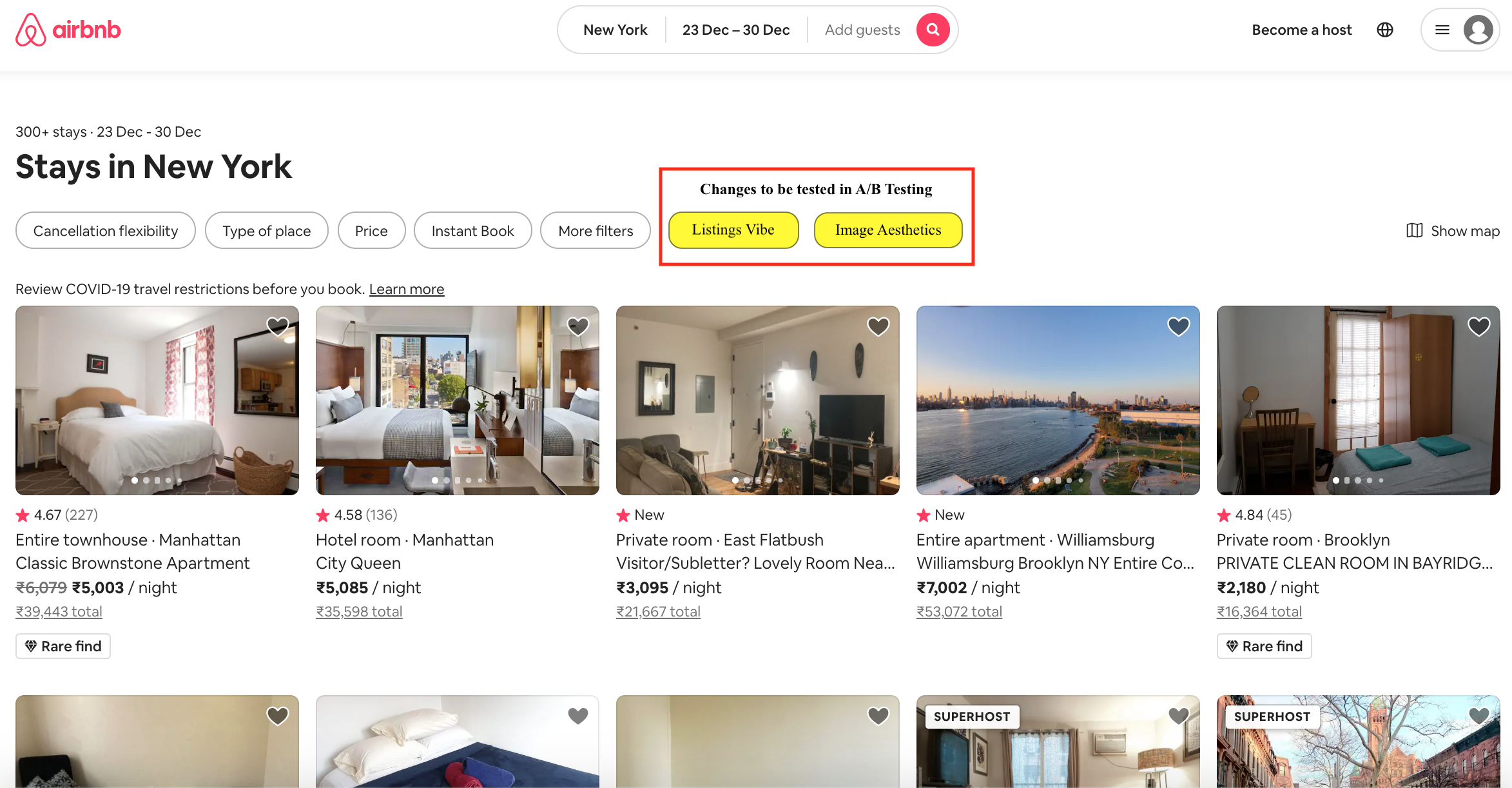
Users of online home listings portal such as Airbnb have to rely solely on information provided by hosts. It is vital that the images posted by the host is clear and an accurate depiction of reality. In this regard, it makes sense that users would want to prefer listings with very good image quality and aesthetics. Currently there is no easy way for users to search by image quality, in this project a deep learning model is used to assess the image posted by hosts. A image quality score is assigned to each image and the users can then sort the listings by this score such that the listings with the best image quality will appear at the top and making it easier for users to find what they are looking for.
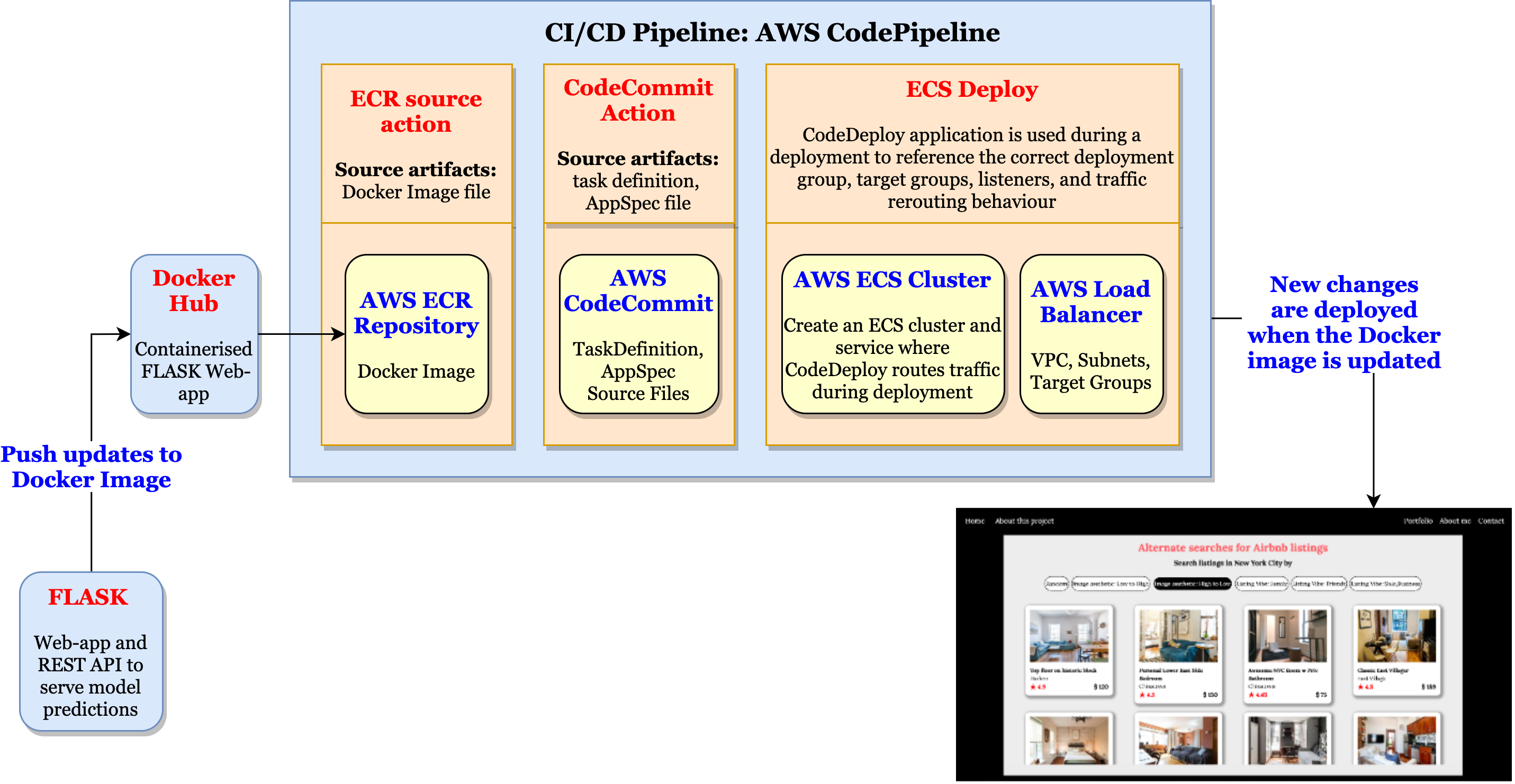
Pipeline: Search by Image Aesthetics

The Deep Learning Model used to assess image quality is Google's Neural image assessment model. It is based on Convolutional Neural Networks (CNN). This implementation of the model was used to assign scores to photos of listings.
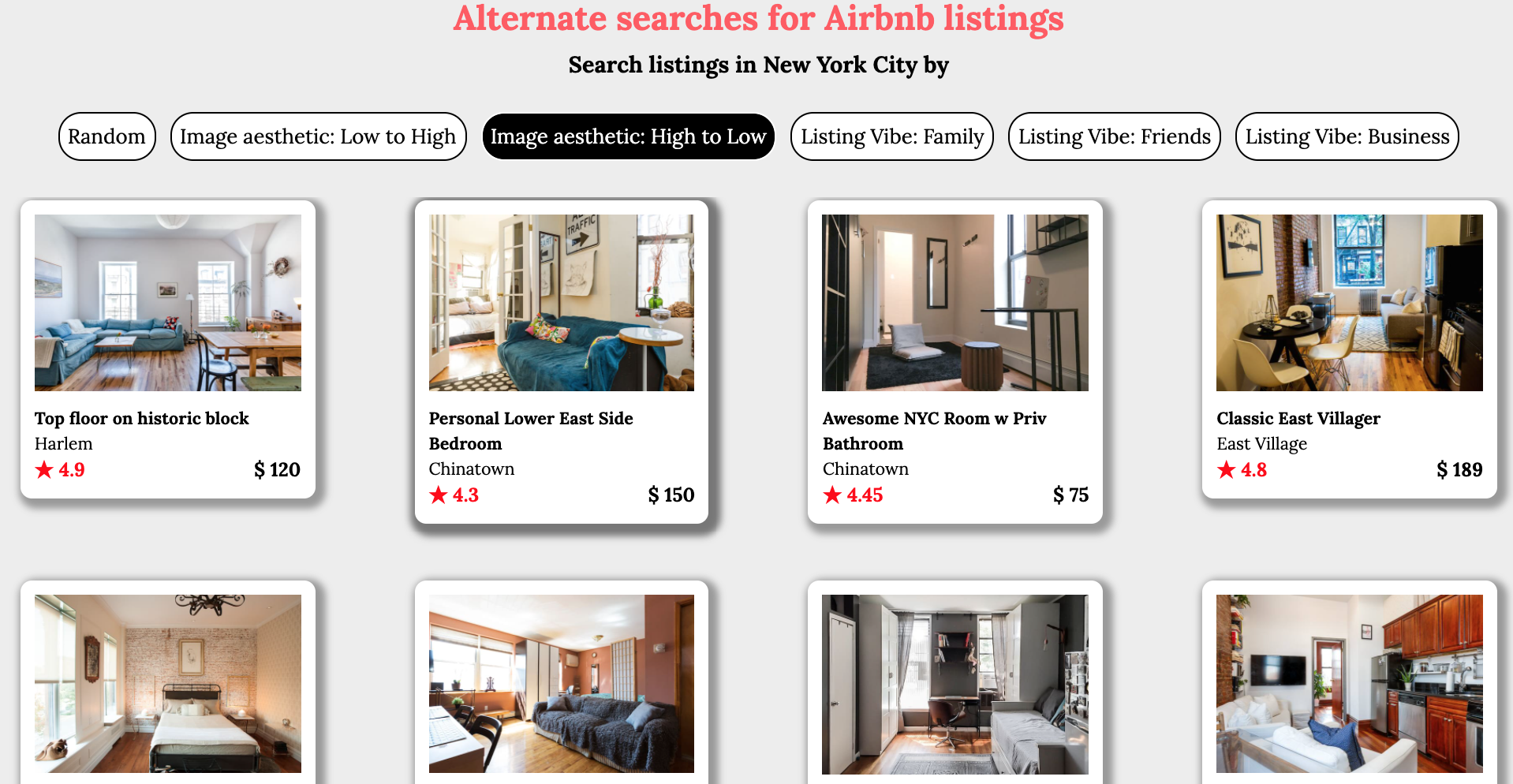
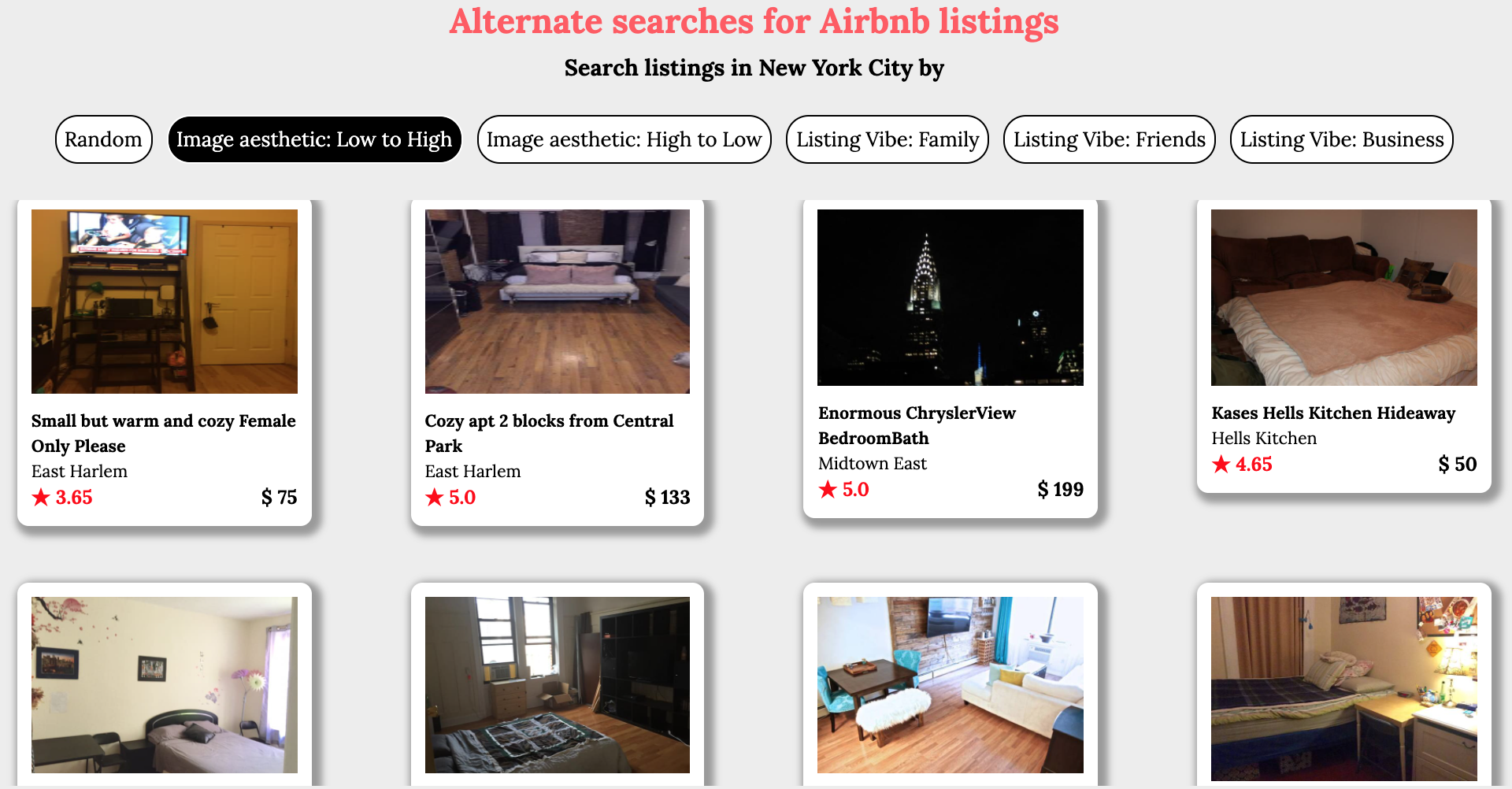
The results indicate how the Deep Learning model has accurately assigned high aesthetic scores to brightly lit images of rooms with clearly visible amenities. Whereas images shot in low light, with poor clarity are assigned lower scores. This feature would be very useful for users to eliminate such listings and encourage more hosts to upload pictures of better quality.